






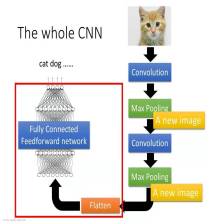
上篇博文我们对机器学习有了大致的了解
https://blog.csdn.net/liuzuoping/article/details/103335958
现在我们来看看实际的招聘数据建模
招聘数据的建模:GBDT
import pandas as pd
import numpy as np
df = pd.read_csv('./lagou_featured.csv', encoding='gbk')
df.shape
1650, 60)
pd.options.display.max_columns = 999
df.head()

import matplotlib.pyplot as plt
plt.hist(df['salary'])
plt.show();

X = df.drop(['salary'], axis=1).values
y = df['salary'].values.reshape((-1, 1))
print(X.shape, y.shape)
(1650, 59) (1650, 1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(1155, 59) (1155, 1) (495, 59) (495, 1)
from sklearn.ensemble import GradientBoostingRegressor
model = GradientBoostingRegressor(n_estimators = 100, max_depth = 5)
model.fit(X_train, y_train)

from sklearn.metrics import mean_squared_error
y_pred = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test, y_pred)))
print(y_pred[:10])
print(y_test[:10].flatten())
plt.plot(y_pred)
plt.plot(y_test)
plt.legend(['y_pred', 'y_test'])
plt.show();
8622.987377935946
[25297.50618265 6663.32391091 28277.21891716 33079.18172213
15296.22154914 32275.89608055 35078.15056713 12793.41861457
25296.7693544 14796.7485948 ][22500 10000 25000 40000 13500 25000 42500 3500 30000 20000]

# 目标变量对数化处理
X_train, X_test, y_train, y_test = train_test_split(X, np.log(y), test_size=0.3, random_state=42)
model = GradientBoostingRegressor(n_estimators = 100, max_depth = 5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test, y_pred)))
0.42803287201114965
plt.plot(np.exp(y_pred))
plt.plot(np.exp(y_test))
plt.legend(['y_pred', 'y_test'])
plt.show();

招聘数据建模:XGBoost
from sklearn.model_selection import KFold
import xgboost as xgb
from sklearn.metrics import mean_squared_error
import time
kf = KFold(n_splits=5, random_state=123, shuffle=True)
def evalerror(preds, dtrain):
labels = dtrain.get_label()
return 'mse', mean_squared_error(np.exp(preds), np.exp(labels))
y = np.log(y)
valid_preds = np.zeros((330, 5))
time_start = time.time()
for i, (train_ind, valid_ind) in enumerate(kf.split(X)):
print('Fold', i+1, 'out of', 5)
X_train, y_train = X[train_ind], y[train_ind]
X_valid, y_valid = X[valid_ind], y[valid_ind]
xgb_params = {
'eta': 0.01,
'max_depth': 6,
'subsample': 0.9,
'colsample_bytree': 0.9,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'seed': 99,
'silent': True
}
d_train = xgb.DMatrix(X_train, y_train)
d_valid = xgb.DMatrix(X_valid, y_valid)
watchlist = [(d_train, 'train'), (d_valid, 'valid')]
model = xgb.train(
xgb_params,
d_train,
2000,
watchlist,
verbose_eval=100,
# feval=evalerror,
early_stopping_rounds=1000
)
# valid_preds[:, i] = np.exp(model.predict(d_valid))
# valid_pred = valid_preds.means(axis=1)
# print('outline score:{}'.format(np.sqrt(mean_squared_error(y_pred, valid_pred)*0.5)))
print('cv training time {} seconds'.format(time.time() - time_start))
Fold 1 out of 5
[0] train-rmse:0.33306 valid-rmse:0.331891
Multiple eval metrics have been passed: ‘valid-rmse’ will be used for early stopping.Will train until valid-rmse hasn’t improved in 1000 rounds.
[100] train-rmse:0.123801 valid-rmse:0.122953
[200] train-rmse:0.048429 valid-rmse:0.047906
[300] train-rmse:0.022679 valid-rmse:0.023399
[400] train-rmse:0.015262 valid-rmse:0.017538
[500] train-rmse:0.013248 valid-rmse:0.016514
[600] train-rmse:0.012385 valid-rmse:0.016278
[700] train-rmse:0.011668 valid-rmse:0.016141
[800] train-rmse:0.011105 valid-rmse:0.016072
[900] train-rmse:0.010508 valid-rmse:0.016045
[1000] train-rmse:0.009946 valid-rmse:0.016034
[1100] train-rmse:0.009444 valid-rmse:0.016018
[1200] train-rmse:0.008941 valid-rmse:0.015965
[1300] train-rmse:0.008467 valid-rmse:0.015955
[1400] train-rmse:0.008074 valid-rmse:0.015952
[1500] train-rmse:0.00766 valid-rmse:0.015982
[1600] train-rmse:0.007329 valid-rmse:0.015999
[1700] train-rmse:0.006996 valid-rmse:0.01601
[1800] train-rmse:0.00671 valid-rmse:0.016027
[1900] train-rmse:0.006431 valid-rmse:0.016048
[1999] train-rmse:0.006165 valid-rmse:0.016077 Fold 2 out of 5
[0] train-rmse:0.333054 valid-rmse:0.331892 Multiple eval metrics have
been passed: ‘valid-rmse’ will be used for early stopping.Will train until valid-rmse hasn’t improved in 1000 rounds.
[100] train-rmse:0.123781 valid-rmse:0.122921
[200] train-rmse:0.04833 valid-rmse:0.048388
[300] train-rmse:0.022486 valid-rmse:0.024579
[400] train-rmse:0.014937 valid-rmse:0.018959
[500] train-rmse:0.012796 valid-rmse:0.01799
[600] train-rmse:0.011832 valid-rmse:0.017761
[700] train-rmse:0.011143 valid-rmse:0.017666
[800] train-rmse:0.010577 valid-rmse:0.017583
[900] train-rmse:0.01002 valid-rmse:0.017578
[1000] train-rmse:0.009464 valid-rmse:0.017567
[1100] train-rmse:0.008973 valid-rmse:0.017573
[1200] train-rmse:0.008511 valid-rmse:0.017533
[1300] train-rmse:0.008094 valid-rmse:0.017558
[1400] train-rmse:0.007692 valid-rmse:0.017593
[1500] train-rmse:0.00734 valid-rmse:0.017602
[1600] train-rmse:0.006998 valid-rmse:0.017616
[1700] train-rmse:0.006699 valid-rmse:0.017634
[1800] train-rmse:0.006431 valid-rmse:0.017649
[1900] train-rmse:0.006175 valid-rmse:0.01767
[1999] train-rmse:0.005947 valid-rmse:0.017685 Fold 3 out of 5
[0] train-rmse:0.3332 valid-rmse:0.331293 Multiple eval metrics have
been passed: ‘valid-rmse’ will be used for early stopping.Will train until valid-rmse hasn’t improved in 1000 rounds.
[100] train-rmse:0.123861 valid-rmse:0.122517
[200] train-rmse:0.048373 valid-rmse:0.048126
[300] train-rmse:0.022538 valid-rmse:0.024518
[400] train-rmse:0.015041 valid-rmse:0.019007
[500] train-rmse:0.013027 valid-rmse:0.017962
[600] train-rmse:0.012218 valid-rmse:0.017705
[700] train-rmse:0.011589 valid-rmse:0.017572
[800] train-rmse:0.011017 valid-rmse:0.017488
[900] train-rmse:0.010478 valid-rmse:0.017429
[1000] train-rmse:0.009962 valid-rmse:0.017398
[1100] train-rmse:0.009473 valid-rmse:0.017389
[1200] train-rmse:0.009021 valid-rmse:0.017407
[1300] train-rmse:0.008564 valid-rmse:0.01738
[1400] train-rmse:0.008107 valid-rmse:0.017453
[1500] train-rmse:0.007716 valid-rmse:0.01751
[1600] train-rmse:0.007366 valid-rmse:0.017524
[1700] train-rmse:0.007038 valid-rmse:0.017577
[1800] train-rmse:0.006747 valid-rmse:0.01762
[1900] train-rmse:0.006463 valid-rmse:0.017656
[1999] train-rmse:0.00621 valid-rmse:0.017681 Fold 4 out of 5
[0] train-rmse:0.332278 valid-rmse:0.335004 Multiple eval metrics have
been passed: ‘valid-rmse’ will be used for early stopping.Will train until valid-rmse hasn’t improved in 1000 rounds.
[100] train-rmse:0.123496 valid-rmse:0.125373
[200] train-rmse:0.04828 valid-rmse:0.050471
[300] train-rmse:0.022633 valid-rmse:0.02646
[400] train-rmse:0.015129 valid-rmse:0.020626
[500] train-rmse:0.013123 valid-rmse:0.019473
[600] train-rmse:0.012111 valid-rmse:0.01922
[700] train-rmse:0.011387 valid-rmse:0.019143
[800] train-rmse:0.010835 valid-rmse:0.019108
[900] train-rmse:0.010264 valid-rmse:0.019091
[1000] train-rmse:0.009751 valid-rmse:0.019083
[1100] train-rmse:0.009241 valid-rmse:0.019066
[1200] train-rmse:0.008762 valid-rmse:0.019096
[1300] train-rmse:0.008298 valid-rmse:0.019128
[1400] train-rmse:0.00785 valid-rmse:0.019159
[1500] train-rmse:0.007463 valid-rmse:0.019204
[1600] train-rmse:0.007102 valid-rmse:0.019224
[1700] train-rmse:0.006768 valid-rmse:0.019289
[1800] train-rmse:0.006462 valid-rmse:0.019321
[1900] train-rmse:0.006175 valid-rmse:0.019345
[1999] train-rmse:0.005929 valid-rmse:0.019371 Fold 5 out of 5
[0] train-rmse:0.332528 valid-rmse:0.334015 Multiple eval metrics have
been passed: ‘valid-rmse’ will be used for early stopping.Will train until valid-rmse hasn’t improved in 1000 rounds.
[100] train-rmse:0.123627 valid-rmse:0.125205
[200] train-rmse:0.048266 valid-rmse:0.050478
[300] train-rmse:0.022459 valid-rmse:0.025812
[400] train-rmse:0.014984 valid-rmse:0.019349
[500] train-rmse:0.012888 valid-rmse:0.017977
[600] train-rmse:0.011971 valid-rmse:0.017668
[700] train-rmse:0.011257 valid-rmse:0.017635
[800] train-rmse:0.010674 valid-rmse:0.017651
[900] train-rmse:0.010119 valid-rmse:0.017668
[1000] train-rmse:0.00961 valid-rmse:0.01767
[1100] train-rmse:0.0091 valid-rmse:0.017696
[1200] train-rmse:0.008653 valid-rmse:0.017712
[1300] train-rmse:0.008234 valid-rmse:0.017735
[1400] train-rmse:0.007845 valid-rmse:0.017774
[1500] train-rmse:0.007475 valid-rmse:0.017833
[1600] train-rmse:0.007145 valid-rmse:0.017878 Stopping. Best
iteration: [682] train-rmse:0.011366 valid-rmse:0.017624cv training time 43.72867012023926 seconds
import xgboost as xgb
xg_train = xgb.DMatrix(X, y)
params = {
'eta': 0.01,
'max_depth': 6,
'subsample': 0.9,
'colsample_bytree': 0.9,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'seed': 99,
'silent': True
}
cv = xgb.cv(params, xg_train, 1000, nfold=5, early_stopping_rounds=800, verbose_eval=100)

招聘数据建模:lightGBM
X = df.drop(['salary'], axis=1).values
y = np.log(df['salary'].values.reshape((-1, 1))).ravel()
print(type(X), type(y))\
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
def evalerror(preds, dtrain):
labels = dtrain.get_label()
return 'mse', mean_squared_error(np.exp(preds), np.exp(labels))
params = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mse',
'sub_feature': 0.7,
'num_leaves': 17,
'colsample_bytree': 0.7,
'feature_fraction': 0.7,
'min_data': 100,
'min_hessian': 1,
'verbose': -1,
}
print('begin cv 5-fold training...')
scores = []
start_time = time.time()
kf = KFold(n_splits=5, shuffle=True, random_state=27)
for i, (train_index, valid_index) in enumerate(kf.split(X)):
print('Fold', i+1, 'out of', 5)
X_train, y_train = X[train_index], y[train_index]
X_valid, y_valid = X[valid_index], y[valid_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
model = lgb.train(params,
lgb_train,
num_boost_round=2000,
valid_sets=lgb_valid,
verbose_eval=200,
# feval=evalerror,
early_stopping_rounds=1000)
# feat_importance = pd.Series(model.feature_importance(), index=X.columns).sort_values(ascending=False)
# test_preds[:, i] = model.predict(lgb_valid)
# print('outline score:{}'.format(np.sqrt(mean_squared_error(y_pred, valid_pred)*0.5)))
print('cv training time {} seconds'.format(time.time() - time_start))
<class ‘numpy.ndarray’> <class ‘numpy.ndarray’>
begin cv 5-fold training… Fold 1 out of 5 Training until validation
scores don’t improve for 1000 rounds. [200] valid_0’s l2: 0.187053
[400] valid_0’s l2: 0.168876 [600] valid_0’s l2: 0.163493
[800] valid_0’s l2: 0.159567 [1000] valid_0’s l2: 0.156541
[1200] valid_0’s l2: 0.154333 [1400] valid_0’s l2: 0.152615
[1600] valid_0’s l2: 0.151386 [1800] valid_0’s l2: 0.150502
[2000] valid_0’s l2: 0.150052 Did not meet early stopping. Best
iteration is: [2000] valid_0’s l2: 0.150052 Fold 2 out of 5 Training
until validation scores don’t improve for 1000 rounds. [200] valid_0’s
l2: 0.215835 [400] valid_0’s l2: 0.193448 [600] valid_0’s l2: 0.183787
[800] valid_0’s l2: 0.17847 [1000] valid_0’s l2: 0.176257
[1200] valid_0’s l2: 0.17524 [1400] valid_0’s l2: 0.175028
[1600] valid_0’s l2: 0.17538 [1800] valid_0’s l2: 0.175021
[2000] valid_0’s l2: 0.174812 Did not meet early stopping. Best
iteration is: [1980] valid_0’s l2: 0.174742 Fold 3 out of 5 Training
until validation scores don’t improve for 1000 rounds. [200] valid_0’s
l2: 0.241614 [400] valid_0’s l2: 0.227725 [600] valid_0’s l2: 0.221405
[800] valid_0’s l2: 0.217776 [1000] valid_0’s l2: 0.215626
[1200] valid_0’s l2: 0.214789 [1400] valid_0’s l2: 0.214369
[1600] valid_0’s l2: 0.213602 [1800] valid_0’s l2: 0.213375
[2000] valid_0’s l2: 0.213225 Did not meet early stopping. Best
iteration is: [2000] valid_0’s l2: 0.213225 Fold 4 out of 5 Training
until validation scores don’t improve for 1000 rounds. [200] valid_0’s
l2: 0.179245 [400] valid_0’s l2: 0.161027 [600] valid_0’s l2: 0.155393
[800] valid_0’s l2: 0.151949 [1000] valid_0’s l2: 0.149745
[1200] valid_0’s l2: 0.1482 [1400] valid_0’s l2: 0.146711
[1600] valid_0’s l2: 0.146226 [1800] valid_0’s l2: 0.14604
[2000] valid_0’s l2: 0.145825 Did not meet early stopping. Best
iteration is: [1999] valid_0’s l2: 0.145815 Fold 5 out of 5 Training
until validation scores don’t improve for 1000 rounds. [200] valid_0’s
l2: 0.192271 [400] valid_0’s l2: 0.167746 [600] valid_0’s l2: 0.157526
[800] valid_0’s l2: 0.151366 [1000] valid_0’s l2: 0.147443
[1200] valid_0’s l2: 0.144963 [1400] valid_0’s l2: 0.143564
[1600] valid_0’s l2: 0.142231 [1800] valid_0’s l2: 0.141538
[2000] valid_0’s l2: 0.141212 Did not meet early stopping. Best
iteration is: [1983] valid_0’s l2: 0.141169 cv training time
4696.695798635483 seconds















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









