







RAG(检索增强生成)和 LangChain 的关系可以用一句话概括:LangChain 是一个框架,而 RAG 是 LangChain 支持的一种核心技术应用模式。两者结合使用时,LangChain 提供了一套完整的工具链来简化 RAG 的实现流程。以下是具体解析:
一、RAG 和 LangChain 的关系
1. 定义层面的关系
-
RAG(Retrieval-Augmented Generation):
是一种技术范式(方法论),通过“检索外部知识 → 增强大模型输入 → 生成精准回答”的流程,提升回答的专业性和实时性。 -
LangChain:
是一个开发框架(工具箱),提供实现 RAG 所需的模块化组件(如文档加载、向量化、检索链),让开发者无需从零造轮子。
2. 流程中的协作关系
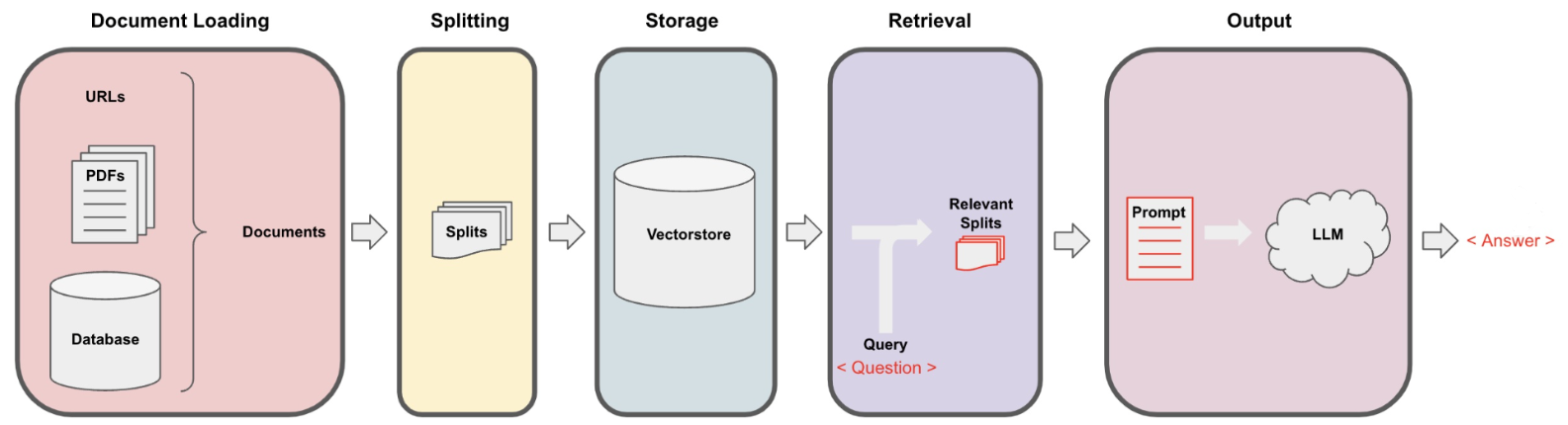
在 RAG 的实现中,LangChain 负责以下关键步骤:
复制
[1] 文档加载 → [2] 文本分块 → [3] 向量化 → [4] 存储 → [5] 检索 → [6] 生成回答
-
LangChain 的贡献:
-
提供
DocumentLoader(加载 PDF/网页/数据库等数据) -
内置
TextSplitter(智能分块避免语义割裂) -
封装
Embedding 模型(如 OpenAI、Hugging Face) -
集成
向量数据库(如 FAISS、Pinecone) -
预置
RetrievalQA链(自动拼接检索结果和生成步骤)
-
3. 结合优势
-
LangChain 降低 RAG 开发门槛:
开发者无需手动处理分块策略、相似度匹配算法等复杂细节,通过框架 API 快速搭建流程。 -
RAG 扩展 LangChain 的应用场景:
赋予 LangChain 构建的 AI 应用动态知识获取能力,使其适用于客服、法律咨询等专业领域。
二、通俗类比
-
LangChain 像乐高积木套装:
提供各种标准化积木块(工具模块),开发者可以按需拼接。 -
RAG 像用乐高搭一座桥:
这座桥的结构是“检索→增强→生成”,而 LangChain 提供了搭桥所需的桥墩、桥面等预制件。
三、代码示例:用 LangChain 实现 RAG
场景:基于本地文档的问答系统
# 安装依赖:pip install langchain langchain-openai faiss-cpu python-dotenv
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
import os
# 1. 加载文档(示例:本地知识库)
loader = TextLoader("knowledge.txt") # 准备一个包含知识的文本文件
documents = loader.load()
# 2. 文本分块(将长文档切分为语义片段)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块约500字符
chunk_overlap=50 # 块间重叠50字符避免断句
)
chunks = text_splitter.split_documents(documents)
# 3. 向量化存储(把文本转换为数学向量)
embeddings = OpenAIEmbeddings() # 使用OpenAI的嵌入模型
vector_db = FAISS.from_documents(chunks, embeddings) # 存储到FAISS向量库
# 4. 构建RAG问答链
llm = ChatOpenAI(model="gpt-3.5-turbo") # 生成用的大模型
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_db.as_retriever(search_kwargs={"k": 3}), # 检索前3相关块
chain_type="stuff" # 简单拼接检索结果
)
# 5. 提问测试
question = "Python中如何创建虚拟环境?"
answer = qa_chain.invoke({"query": question})
print(answer["result"])代码解析
-
文档处理:
-
从本地文件加载知识(支持 PDF、网页等格式)
-
将长文本切割为小段,避免信息过载
-
-
向量化与检索:
-
使用 OpenAI 模型将文本转换为向量
-
FAISS 向量库快速匹配相似内容
-
-
生成回答:
-
将检索到的文本作为上下文,输入 GPT-3.5 生成最终答案
-
四、关键结论
-
依赖关系:
RAG 可以通过 LangChain 更高效地实现,但 LangChain 不只用于 RAG(还支持 Agents、记忆管理等)。 -
分工关系:
-
LangChain = 工具箱(提供锤子、螺丝刀)
-
RAG = 用这些工具组装出的产品(如椅子)
-
-
适用场景:
当需要让大模型基于特定知识库回答时(如企业文档、最新资讯),RAG + LangChain 是黄金组合。


















 3330
3330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











