







分词器(Tokenizer)
分词是一个处理过程,其将文本句子分割成一系列独立的单词词汇集合,Spark提供Tokenizer分词器类,其提供的功能是使用分隔符的方式处理文本句子的特征转换,Spark提供RegexTokenizer分词器类,其提供的功能是使用正则表达式的方式处理文本句子的特征转换,默认的分隔符是空格,其正则表达式是\\s+,该表达式表示的意思是一个或者多个空格作为分词器的分隔符。


如上所示,data创建了三行记录,每行记录对应一个文本句子。Schema定义一个两列的数据表格,第一列是id,表示行记录的序号,第二列是sentence,表示行记录的文本句子。sentenceDataFrame使用data以及schema创建一个数据框架。tokenizer定义一个分词器,输入sentence列,输出words单词词汇集合列。regexTokenizer定义一个正则表达式的分词器,其匹配的正则表达式是\\W,该表达式表示的意思是匹配每个单词。countTokens定义一个分词计数器,用于统计分词器所得的单词词汇集合的大小。tokenized以及regexTokenized是分词所得的单词词汇集合。
StopWordsRemover
该转换器提供在单词分割的过程中,删除一些没有实质性意义的单词,例如,英文句子中的a、the。


如上所示,对输入的原文进行转换,输出合法的单词词汇集合。

如上所示,使用Java代码对输入的数据集,执行对应的转换,输出合法的单词词汇集合。其中,remover定义一个过滤不合法单词的转换器,data定义一个输入的原文句子,schema定义一个数据表格,dataset使用data以及schema创建一个数据框架,remover对数据框架执行转换。
n-gram
该转换器是指对原文句子执行转换,输出一个包括n个单词的单词序列的集合。

如上所示,使用Java代码对输入的原文句子执行n-gram的转换。

如上所示,使用scala的本地单元测试环境对原文句子的数据集合执行n-gram的转换,最后,输出n-grams的数据集合,其中n-gram对应2-gram。
Binarizer
该转换器是对数字特征的二元分类转换器,其设定一个临界值,小于临界值的是一种分类,大于临界值的是其他分类。

如上所示,使用Java代码对输入的数字特征执行转换,其中,data定义输入的数字特征,schema定义一个数据表格,包括id以及feature两列,continuousDataFrame定义一个数据框架,binarizer定义一个二元分类转换器,binarizedDataFrame是使用二元分类转换器对数据集合执行二元分类。
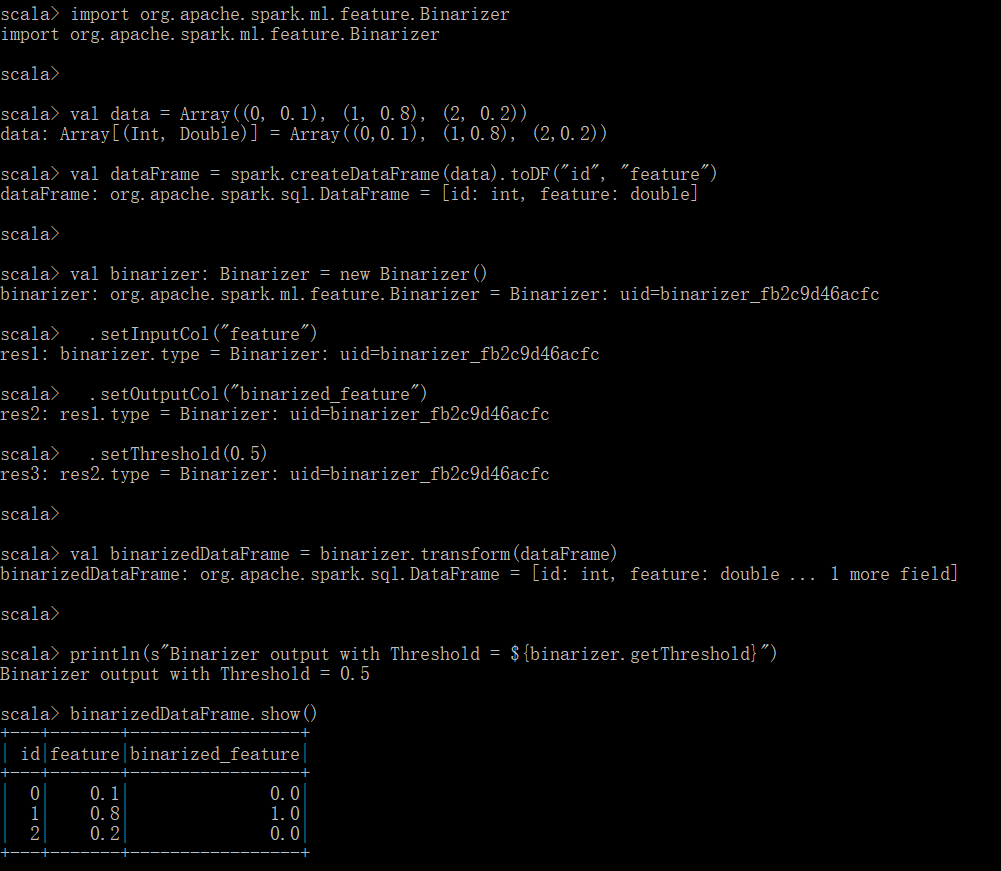
如上所示,使用scala语言执行二元分类的转换,其中,小于临界值的数字特征被转换成0.0,大于临界值的数字特征被转换成1.0。
(未完待续)
















 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











