







参考文献[1][2]解释了VBO的概念,并附带示例代码。
参考文献[3]提供的代码示例演示了OpenGL的三种绘制方式:
1)直接绘制: glBegin(),glEnd();
2)使用顶点数组; glDrawArrays()或glDrawElements()或glDrawRangeElements();
3)VBO: glBindBufferARB(), glDrawArrays()或glDrawElements();
PBO(pixel buffer object)是GPU上存储像素数据的高速缓存,类似于VBO存储顶点数据。PBO的优势是像素数据的快速传递,还可以使CPU与GPU异步执行。图1是用传统的方法从图像源(如图像文件或视频)载入图像数据到纹理对象的过程。像素数据首先存到系统内存中,接着使用glTexImage2D将数据从系统内存拷贝到纹理对象。包含的两个子过程均需要有CPU执行。而从图2中,可以看到像素数据直接载入到PBO中,这个过程仍需要CPU来执行,但是从数据从PBO到纹理对象的过程则由GPU来执行DMA,而不需要CPU参与。另外,OpenGL可以进行异步DMA,不必等像素数据传递完毕CPU就可以继续执行其他操作。
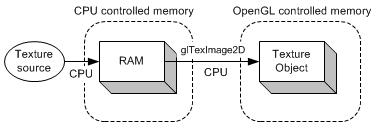
图1
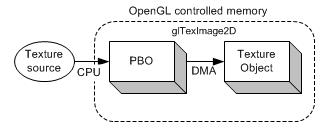
图2
参考文献[4]提供了PBO的代码示例。
FBO(frame buffer object)是OpenGL扩展GL_EXT_framebuffer_object提供的不能显示的帧缓存接口。和window系统提供的帧缓存一样,FBO也有一组相应存储颜色、深度和模板(注意没有累积)数据的缓存区域。FBO中存储这些数据的区域称之为“缓存关联图像”(frame buffer-attached image)。缓存关联图像分为两类:纹理缓存和渲染(显示)缓存(renderbuffer)。如果纹理对象的图像数据关联到帧缓存,opengl执行的将是“渲染到纹理”(render to texture)操作。如果渲染缓存对象的图像数据关联到帧缓存,opengl执行的将是“离线渲染”(offscreen rendering)。
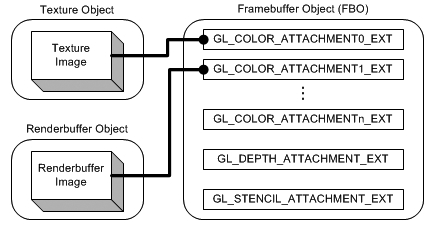
参考文献[5]提供了PBO的代码示例。
参考:
[1] VBO:http://blog.sina.com.cn/s/blog_4062094e0100aluv.html
[2]VBO简单代码示例:http://www.cnblogs.com/hefee/p/3824300.html
[3]opengl代码实现三种绘制方式:immediate mode, VA, VBO:
http://wap.oschina.net/code/snippet_149334_10461
[4]PBO代码:http://blog.sina.com.cn/s/blog_4062094e0100alvt.html
[5]FBO代码:http://blog.sina.com.cn/s/blog_4062094e0100alvv.html















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









