







def ptb_producer(raw_data, batch_size, num_steps, name=None):
"""Iterate on the raw PTB data.
This chunks up raw_data into batches of examples and returns Tensors that
are drawn from these batches.
Args:
raw_data: one of the raw data outputs from ptb_raw_data.
batch_size: int, the batch size.
num_steps: int, the number of unrolls.
name: the name of this operation (optional).
Returns:
A pair of Tensors, each shaped [batch_size, num_steps]. The second element
of the tuple is the same data time-shifted to the right by one.
Raises:
tf.errors.InvalidArgumentError: if batch_size or num_steps are too high.
"""
with tf.name_scope(name, "PTBProducer", [raw_data, batch_size, num_steps]):
#原始数据就是一个个的单词,这里将原始数据转换为tensor
raw_data = tf.convert_to_tensor(raw_data, name="raw_data", dtype=tf.int32)
#求单词的个数
data_len = tf.size(raw_data)
#得到总共批的个数
batch_len = data_len // batch_size
#将样本进行reshape
#shape的行数是一个批的大小,最后处理的时候是一列一列处理的
#shape的列数是总共批的个数
data = tf.reshape(raw_data[0 : batch_size * batch_len],
[batch_size, batch_len])
#epoch_size是用总的批数除以时间步长长度
#得到的就是运行一个epoch需要运行num_steps的个数
epoch_size = (batch_len - 1) // num_steps
assertion = tf.assert_positive(
epoch_size,
messageepoch_size = (batch_len - 1) // num_step="epoch_size == 0, decrease batch_size or num_steps")
with tf.control_dependencies([assertion]):
epoch_size = tf.identity(epoch_size, name="epoch_size")
#产生一个队列,队列的长度为epoch_size,未对样本打乱
#i是一个出列的操作,每次出列1,也就是一个num_steps
i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue()
#将数据进行切片,起始点是[0, i * num_steps]
#终止点是[batch_size, (i + 1) * num_steps]
#其中终止点的batch_size代表的是维度
#(i + 1) * num_steps代表的是数据的长度
#这里即将data数据从第i * num_steps列开始,向后取(i + 1) * num_steps列,即一个num_steps的长度
x = tf.strided_slice(data, [0, i * num_steps],
[batch_size, (i + 1) * num_steps])
#将取到的数据reshape一下
x.set_shape([batch_size, num_steps])
#y的切法和x类似,只是y要向后一列移动一个单位,因为这里是根据上一个单词预测下一个单词
y = tf.strided_slice(data, [0, i * num_steps + 1],
[batch_size, (i + 1) * num_steps + 1])
y.set_shape([batch_size, num_steps])
return x, y
ptb_word_lm.py
中一些参数的理解:
num_steps,也就是rnn中的time_steps,我的理解是一句话,有time_steps个单词,
有n句话,那么会形成一个n x time_steps的矩阵,那么输入的时候就是每次输入每句话中相同时刻的单词,
然后会得到一个输出,假设也为一个单词,那么经过time_steps-1次处理后,
就会预测到n x (time_steps-1)个单词,然后与label相比较,求误差就会得到梯度,
然后这个梯度反向传播的时候,能够到达的范围就是time_steps
config.hidden_size,这个指的是隐藏层的个数,同时也是输出向量ht的维度,同时也是输入词embedding后的向量维数
那么也就是说,输入向量大小为config.hidden_size时,而对应循环网络这个循环而言,真正循环的次数,应该是循环time_steps
次,不知道理解的对不对
下面是一个rnn 一个step更新的简单示意图与解释
classRNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
W_xh:输入矩阵
W_hy:输出矩阵
W_hh:网络连接,W_hh理论上可以可以刻画输入的整个历史对于最终输出的任何反馈形式
x:输入
y:输出
h:隐藏变量,也就是网络每个神经元的状态,
就是通常说的神经网络本体,也正是循环得以实现的基础,
因为它如同一个可以储存无穷历史信息(理论上)的水库
附lstm结构示意图:
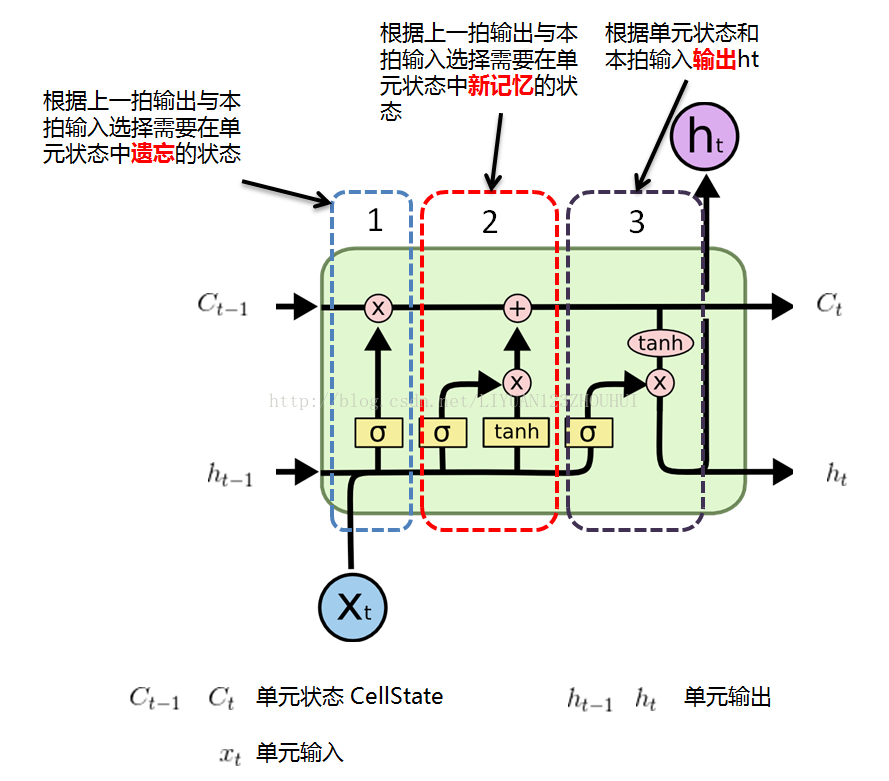
tensorflow官网有lstm语言建模的例子,也可以使用lstm识别手写数字:
https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/5-08-RNN2/














 7421
7421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









