







 本文介绍了基于贝叶斯理论的分类方法,讲解了朴素贝叶斯算法在文档分类中的应用场景,并通过Python实现了一个简单的文本分类器。文章详细阐述了如何准备数据、训练算法以及测试算法,展示了朴素贝叶斯分类器的工作原理和效果。
本文介绍了基于贝叶斯理论的分类方法,讲解了朴素贝叶斯算法在文档分类中的应用场景,并通过Python实现了一个简单的文本分类器。文章详细阐述了如何准备数据、训练算法以及测试算法,展示了朴素贝叶斯分类器的工作原理和效果。
概率是许多机器学习算法的基础,在前面生成决策树的过程中使用了一小部分关于概率的知识,即统计特征在数据集中取某个特定值的次数,然后除以数据集的实例总数,得到特征取该值的概率。
目录:
一.基于贝叶斯理论的分类方法
二.关于朴素贝叶斯的应用场景
三.基于Python和朴素贝叶斯的文本分类
1.准备数据
2.训练算法
3.测试算法
四.小结
以下进入正文:
一.基于贝叶斯理论的分类方法
假设有两类数据组成的数据集如下:
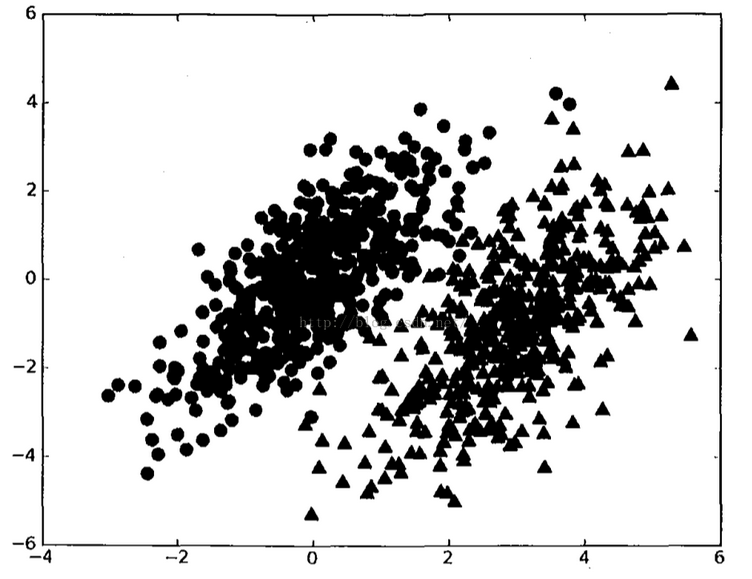
其中,假设两个概率分布的参数已知,并用p1(x,y)表示当前数据点(x,y)属于类别一的概率;用p2(x,y)表示当前数据点(x,y)属于类别二的概率。
贝叶斯决策理论的核心思想是:选择高概率所对应的类别,选择具有最高概率的决策。有时也被总结成“多数占优”的原则。
具体到实例,对于一个数据点(x,y),可以用如下规则判定它的类别:
若p1(x,y)>p2(x,y),那么点(x,y)被判定为类别一。
若p1(x,y)<p2(x,y),那么点(x,y)被判定为类别二。
当然,在实际情况中,单单依靠以上的判定无法解决所有的问题,因为以上准则还不是贝叶斯决策理论的所有内容,使用p1(x,y)和p2(x,y) 只是为了简化描述。更多的,我们使用p(ci|x,y) 来确定给定坐标的点(x,y),该数据点来自类别ci的概率是多少。具体地,应用贝叶斯准则可得到,该准则可以通过已知的三个概率值来计算未知的概率值:
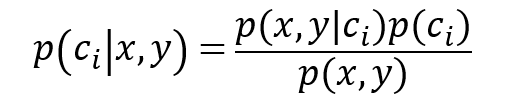
则以上判定法则可转化为:
若p(c1|x,y)>p(c2|x,y),那么点(x,y)被判定为类别一。
若p(c1|x,y)<p(c2|x,y),那么点(x,y)被判定为类别二。
二.关于朴素贝叶斯的应用场景
机器学习的一个重要应用就是文档的自动分类,而朴素贝叶斯正是文档分类的常用算法。基本步骤是遍历并记录下文档中出现的词,并把每个词的出现或者不出现作为一个特征。这样便有跟文档中出现过词汇的个数一样多的特征。若有大量特征时,使用直方图效果更好。以下是朴素贝叶斯的一般过程:
- 收集数据:这里使用RSS源
- 准备数据:需要数值型&布尔型数据
- 分析数据:有大量特征时,绘制特征的作用不大,此时使用直方图效果更好
- 训练算法:计算不同的独立特征的条件概率
- 测试算法:计算错误率
- 使用算法:如文档分类
讲到这里,你也许还会带着疑问,为什么贝叶斯前会加上“朴素”,其实,这是基于朴素贝叶斯的一个假设,即:特征之间相互(统计意义上)独立,如一个单词出现的可能性与其他单词相邻没有关系,当然这在实际情况中不一定是正确的,但无数实验表明,这种假设是有必要的,而且朴素贝叶斯的实际效果其实很好。
朴素贝叶斯的另外一个假设是:每个特征同等重要。当然,这个假设也有问题(不然就不叫假设了……),但确实有用的假设。
三.基于Python和朴素贝叶斯的文本分类
从文本中提取特征,首先需要将文本进行拆分,转化为词向量,某个词存在表示为1,不存在表示为0,这样,原来一大串字符串便转为简单的0,1序列的向量。这种情况下只考虑某个词是否出现,当然,你也可以使用记录词的出现次数作为向量,或者记录不同词出现的频率等等。
1.准备数据:从文本中构建词向量,这里考虑出现在所有文档中的所有单词,并将每一篇文档转化为词汇表上的向量。下面的代码实现了功能,其中:
函数loadDataSet() 创建了一些实验样本postingList和对应的标签listClass,有一些样本被标签为带有侮辱性文字;
函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









