







上一篇文章中对Apriori算法进行了简单的描述(Apriori算法详解之【一、相关概念和核心步骤】http://blog.csdn.net/lizhengnanhua/article/details/9061755),现在用伪代码实现,及对经典例子进行描述(红兰PPT上之摘抄)。
一、Apriori算法伪代码实现:
伪代码描述:
// 找出频繁 1 项集
L1 =find_frequent_1-itemsets(D);
For(k=2;Lk-1 !=null;k++){
// 产生候选,并剪枝
Ck =apriori_gen(Lk-1 );
// 扫描 D 进行候选计数
For each 事务t in D{
Ct =subset(Ck,t); // 得到 t 的子集
For each 候选 c 属于 Ct
c.count++;
}
//返回候选项集中不小于最小支持度的项集
Lk ={c 属于 Ck | c.count>=min_sup}
}
Return L= 所有的频繁集;
第一步:连接(join)
Procedure apriori_gen (Lk-1 :frequent(k-1)-itemsets)
For each 项集 l1 属于 Lk-1
For each 项集 l2 属于 Lk-1
If( (l1 [1]=l2 [1])&&( l1 [2]=l2 [2])&& ……&& (l1 [k-2]=l2 [k-2])&&(l1 [k-1]<l2 [k-1]) )
then{
c = l1 连接 l2 // 连接步:产生候选
//若k-1项集中已经存在子集c则进行剪枝
if has_infrequent_subset(c, Lk-1 ) then
delete c; // 剪枝步:删除非频繁候选
else add c to Ck;
}
Return Ck;
第二步:剪枝(prune)
Procedure has_infrequent_sub (c:candidate k-itemset; Lk-1 :frequent(k-1)-itemsets)
For each (k-1)-subset s of c
If s 不属于 Lk-1 then
Return true;
Return false;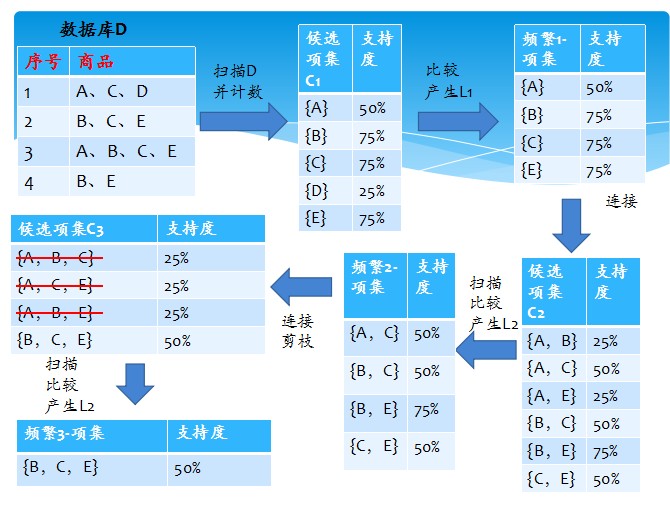
三、总结:
①Apriori算法的缺点:(1)由频繁k-1项集进行自连接生成的候选频繁k项集数量巨大。(2)在验证候选频繁k项集的时候需要对整个数据库进行扫描,非常耗时。
②网上提到的频集算法的几种优化方法:1. 基于划分的方法。2. 基于hash的方法。3. 基于采样的方法。4. 减少交易的个数。
我重点看了“基于划分的方法”改进算法,现在简单介绍一下实现思想:
基于划分(partition)的算法,这个算法先把数据库从逻辑上分成几个互不相交的块,每次单独考虑一个分块并 对它生成所有的频集,然后把产生的频集合并,用来生成所有可能的频集,最后计算这些项集的支持度。
其中,partition算法要注意的是分片的大小选取,要保证每个分片可以被放入到内存。当每个分片产生频集后,再合并产生产生全局的候选k-项集。若在多个处理器分片,可以通过处理器之间共享一个杂凑树来产生频集。
看这个图基本再对照伪代码,基本就可以看懂了~简单明了。















 5152
5152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









