






一、偏态分布
1、何为数据的偏态分布?
频数分布有正态分布和偏态分布之分。正态分布是指多数频数集中在中央位置,两端的频数分布大致对称。
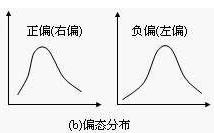
偏态分布是指频数分布不对称,集中位置偏向一侧。若集中位置偏向数值小的一侧,称为正偏态分布;集中位置偏向数值大的一侧,称为负偏态分布。
如果频数分布的高峰向左偏移,长尾向右侧延伸称为正偏态分布,也称右偏态分布;同样的,如果频数分布的高峰向右偏移,长尾向左延伸则成为负偏态分布,也称左偏态分布。
峰左移,右偏,正偏
峰右移,左偏,负偏
偏态分布只有满足一定的条件(如样本例数够大等)才可以看做近似正态分布。
与正态分布相对而言,偏态分布有两个特点:
一是左右不对称(即所谓偏态);
二是当样本增大时,其均数趋向正态分布。
2、构建模型时为什么要尽量将偏态数据转换为正态分布数据?
数据整体服从正态分布,那样本均值和方差则相互独立。正态分布具有很多好的性质,很多模型假设数据服从正态分布。例如线性回归(linear regression),它假设误差服从正态分布,从而每个样本点出现的概率就可以表示成正态分布的形式,将多个样本点连乘再取对数,就是所有训练集样本出现的条件概率,最大化这个条件概率就是LR要最终求解的问题。这里这个条件概率的最终表达式的形式就是我们熟悉的误差平方和。总之, ML中很多model都假设数据或参数服从正态分布。
3、如何检验样本是否服从正态分布?
可以使用Q-Q图来进行检验,Q-Q图是一个散点图,点(x, y)表示数据x的某个分位数,y表示和x的分位数相同的分位数(即[Math Processing Error]FX(x)=FY(y)),如果说两个分布的QQ图在一条直线上,则说明每个[Math Processing Error][xi,xi+1],[yi,yi+1]区间所包含的数据在整个数据集中的比例相同,也就是说明如果对x或y进行放缩的话可以让它们。
所以,如果把未知数据和标准正态分布做Q-Q图的话,如果所有点在一条直线上则说明未知数据的分布服从正态分布。
4 、如果不是正态分布怎么办?
数据右偏的话可以对所有数据取对数、取平方根等,它的原理是因为这样的变换的导数是逐渐减小的,也就是说它的增速逐渐减缓,所以就可以把大的数据向左移,使数据接近正态分布。
如果左偏的话可以取相反数转化为右偏的情况。
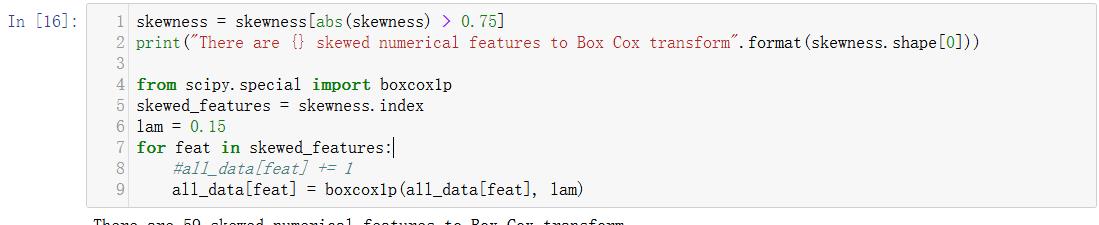
5、采用库函数skew进行数据偏态分析和数据处理
偏态系数以平均值与中位数之差对标准差之比率来衡量偏斜的程度,用SK表示偏斜系数。
偏态系数小于0时,平均数在众数之左,是一种左偏的分布,又称为负偏。
偏态系数大于0时,均值在众数之右,是一种右偏的分布,又称为正偏。
Cs=0称为正态分配,Cs>0称为正偏分配,Cs<0称为负偏分配。
例子:

相关参考:
https://www.cnblogs.com/gczr/p/6802998.html















 6690
6690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









