









目录
Tensor与Autograd
在神经网络中,一个重要内容就是进行参数学习,而参数学习离不开求导,那么PyTorch是如何进行求导的呢?
torch.autograd包就是用来自动求导的。Autograd包为张量上所有的操作提供了自动求导功能,而torch.Tensor和torch.Function为Autograd的两个核心类,它们相互连接并生成一个有向非循环图。
自动求导要点
为实现对Tensor自动求导,需考虑如下事项:
1)创建叶子节点(Leaf Node)的Tensor,使用requires_grad参数指定是否记录对其的操作,以便之后利用backward()方法进行梯度求解。requires_grad参数的缺省值为False,如果要对其求导需设置为True,然后与之有依赖关系的节点会自动变为True。
2)可利用requires_grad_()方法修改Tensor的requires_grad属性。可以调用.detach()或with torch.no_grad():,将不再计算张量的梯度,跟踪张量的历史记录。这点在评估模型、测试模型阶段中常常用到。
3)通过运算创建的Tensor(即非叶子节点),会自动被赋予grad_fn属性。该属性表示梯度函数。叶子节点的grad_fn为None。
4)最后得到的Tensor执行backward()函数,此时自动计算各变量的梯度,并将累加结果保存到grad属性中。计算完成后,非叶子节点的梯度自动释放。
5)backward()函数接收参数,该参数应和调用backward()函数的Tensor的维度相同,或者是可broadcast的维度。如果求导的Tensor为标量(即一个数字),则backward中的参数可省略。
6)反向传播的中间缓存会被清空,如果需要进行多次反向传播,需要指定backward中的参数retain_graph=True。多次反向传播时,梯度是累加的。
7)非叶子节点的梯度backward调用后即被清空。
8)可以通过用torch.no_grad()包裹代码块的形式来阻止autograd去跟踪那些标记为.requesgrad=True的张量的历史记录。这步在测试阶段经常使用。
计算图
计算图是一种有向无环图像,用图形方式来表示算子与变量之间的关系,直观高效。
- 模型正向计算
- 梯度反向计算
![]()
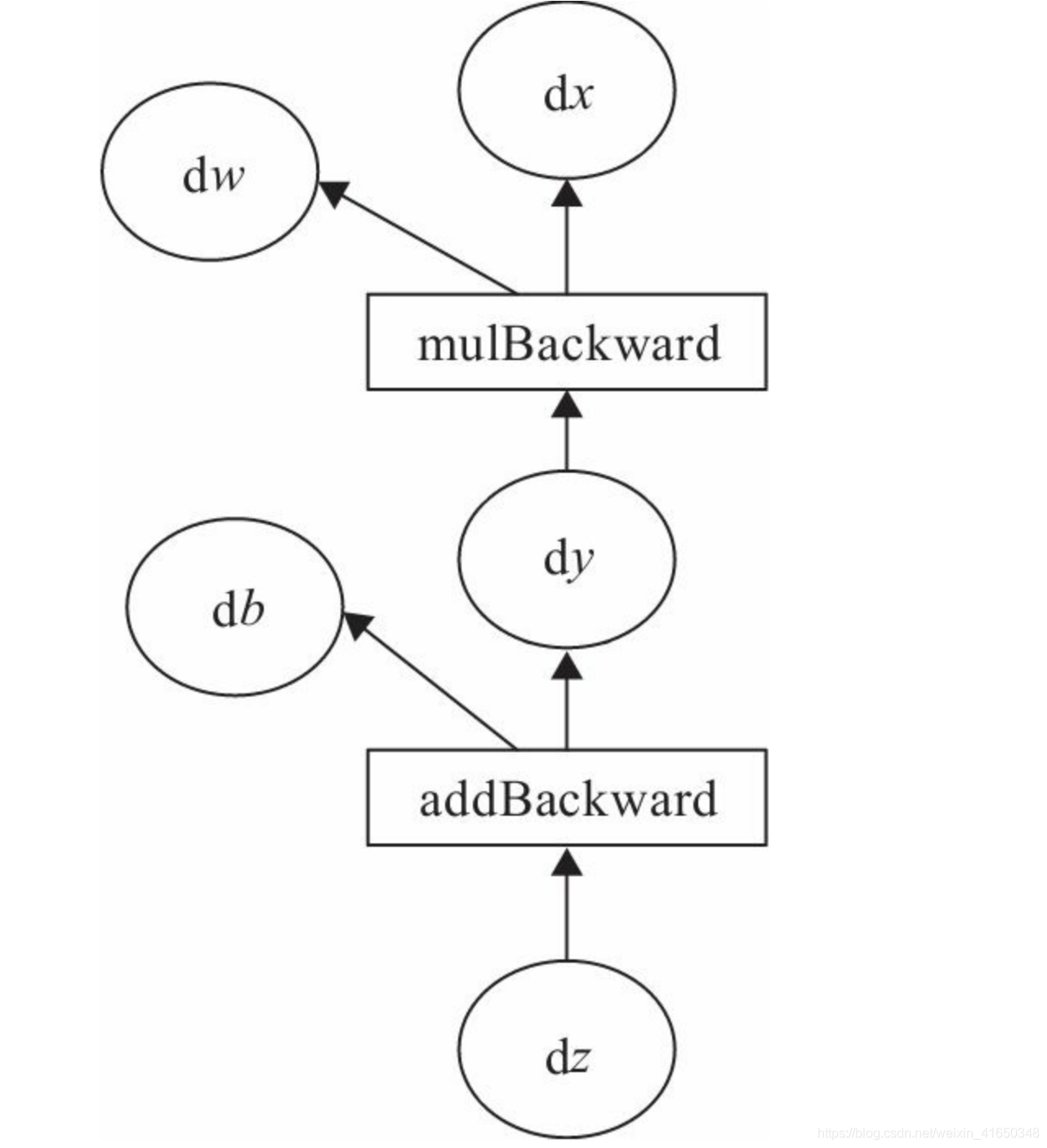
我们的目标是更新各叶子节点的梯度,根据复合函数导数的链式法则,不难算出各叶子节点的梯度。

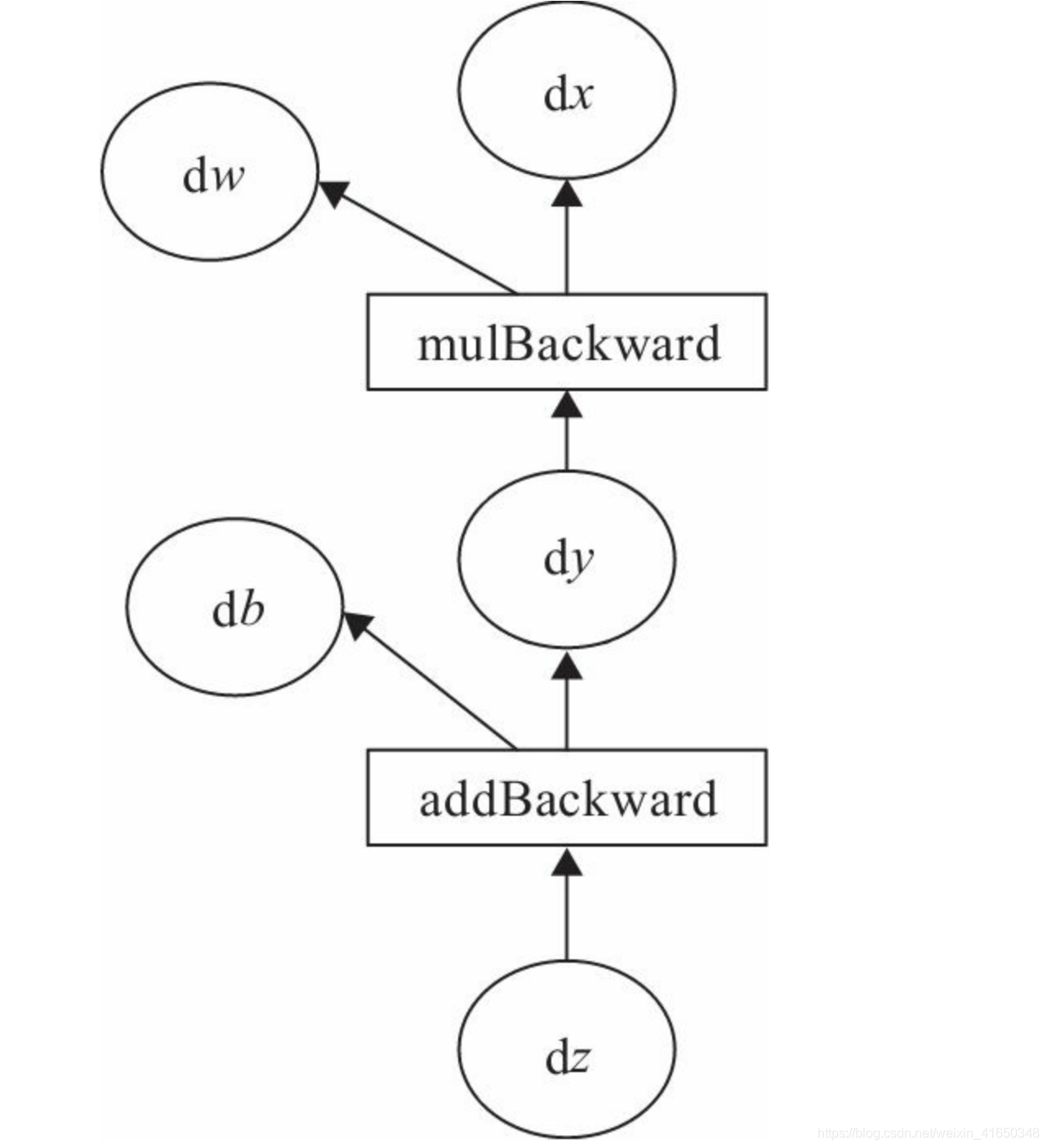
Note:PyTorch调用backward()方法,将自动计算各节点的梯度,这是一个反向传播过程。且在反向传播过程中,autograd从当前根节点z反向溯源,利用导数链式法则,计算所有叶子节点的梯度,其梯度值将累加到grad属性中。对非叶子节点的计算操作(或Function)记录在grad_fn属性中,叶子节点的grad_fn值为None。
标量反向传播
![]()
x = torch.Tensor([2])
w = torch.randn((1,),requires_grad=True)
b = torch.randn((1,),requires_grad=True)
print(x)
print(w)
print(b)
tensor([2.])
tensor([-0.6382], requires_grad=True)
tensor([0.4559], requires_grad=True)
实现前向传播
- w,b节点是需要计算梯度的,需要指定
- 相应的,由w,b计算得来的y z也是需要计算梯度的
- grad_fn叶子节点才为none,y,z非空
y = w.mul(x)
z = y.add(b)
print(y)
print(z)
tensor([-1.2764], grad_fn=<MulBackward0>)
tensor([-0.8205], grad_fn=<AddBackward0>)
print(x.requires_grad)
print(w.requires_grad)
print(b.requires_grad)
print(y.requires_grad)
print(z.requires_grad)
False
True
True
True
True
print(x.grad_fn) #叶子节点为none,后面计算得到的是非叶子节点
print(w.grad_fn)
print(b.grad_fn)
print(y.grad_fn)
print(z.grad_fn)
None
None
None
<MulBackward0 object at 0x7fe8d694f518>
<AddBackward0 object at 0x7fe8d694f5c0>
反向传播
- 只有wb这两个最初创建的需要计算梯度的叶子节点梯度grad非空
- x,y z都是空
z.backward()
print(x.grad)
print(w.grad)
print(b.grad)
print(y.grad)
print(z.grad)
None
tensor([2.])
tensor([1.])
None
None
非标量反向传播
目标张量一般都是标量,如我们经常使用的损失值Loss,一般都是一个标量。但也有非标量的情况,后面将介绍的Deep Dream的目标值就是一个含多个元素的张量。那如何对非标量进行反向传播呢?
- PyTorch有个简单的规定,不让张量(Tensor)对张量求导,只允许标量对张量求导,
- 因此,如果目标张量对一个非标量调用backward(),则需要传入一个gradient参数,该参数也是张量,而且需要与调用backward()的张量形状相同。
![]()
使用Numpy实现机器学习
使用numpy硬撸。。。
- 首先,给出一个数组x,然后基于表达式y =3x^2+2,加上一些噪音数据到达另一组数据y。
- 然后,构建一个机器学习模型,学习表达式y = wx^2+by的两个参数w、b。利用数组x,y的数据为训练数据。
- 最后,采用梯度梯度下降法,通过多次迭代,学习到w、b的值。
import numpy as np
import matplotlib.pyplot as plt
生成训练数据
x = np.linspace(-1,1,100).reshape(100,1)
y = 3*np.power(x,2)+2+0.2*np.random.rand(100,1)
print(x.shape)
print(y.shape)
(100, 1)
(100, 1)
plt.scatter(x,y)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fa6K46ha-1605945971803)(output_78_0.png)]](https://img-blog.csdnimg.cn/2020112116143599.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY1MDM0OA==,size_16,color_FFFFFF,t_70#pic_center)
初始化权重参数
w = np.random.rand(1,1)
b = np.random.rand(1,1)
训练(梯度下降法)
lr = 0.001
for i in range(800):
y_pred = w*np.power(x,2)+b
#计算损失
loss = 0.5*np.power(y_pred-y,2)
loss = np.sum(loss,axis=0)
#计算梯度
grad_w = np.sum((y_pred-y)*np.power(x,2),axis=0)
grad_b = np.sum((y_pred-y),axis=0)
#更新参数
w -= lr*grad_w
b -= lr*grad_b
展示结果
print(w)
print(b)
[[2.99219404]]
[[2.09981455]]
print(loss)
[0.16740311]
plt.plot(x,y_pred,'r-',label='predict')
plt.scatter(x,y,color='g',label='real')
plt.legend()
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fyYlzbSE-1605945971803)(output_86_0.png)]](https://img-blog.csdnimg.cn/20201121161446852.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY1MDM0OA==,size_16,color_FFFFFF,t_70#pic_center)
使用Tensor和Autograd实现机器学习
- 和Nump梯度计算方式不同
- 现在自动计算,只需要调用loss.backward()
- 参数更新方式略有不同,现在需要添加with torch.no_grad():
- 还需要梯度清零w.grad.zero_() +b.grad.zero_()
- 想要plt可视化需要将数据转换为numpy才可以
- 某些函数计算略有效改动,但是函数名同
import torch
import matplotlib.pyplot as plt
x = torch.linspace(-1,1,100).view(100,1)
y = 3*x.pow(2)+2+0.2*torch.rand(100,1)
print(x.shape)
print(y.shape)
torch.Size([100, 1])
torch.Size([100, 1])
plt.scatter(x,y)
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cfADCG0y-1605945971804)(output_91_0.png)]](https://img-blog.csdnimg.cn/20201121161457255.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY1MDM0OA==,size_16,color_FFFFFF,t_70#pic_center)
w = torch.rand((1,1),requires_grad=True)
b = torch.rand((1,1),requires_grad=True)
lr = 0.001
for i in range(800):
y_pred = w*x.pow(2)+b
#计算损失
loss = 0.5*(y_pred-y).pow(2)
loss = loss.sum(axis=0)
#计算梯度
loss.backward() #和使用numpy的区别,不需要手动计算梯度了
#更新参数
with torch.no_grad():
w -= lr*w.grad
b -= lr*b.grad
#梯度清零
w.grad.zero_()
b.grad.zero_()
print(w)
print(b)
tensor([[2.9757]], requires_grad=True)
tensor([[2.1031]], requires_grad=True)
print(loss)
tensor([0.1612], grad_fn=<SumBackward1>)
plt.plot(x.numpy(),y_pred.detach().numpy(),'r-',label='predict')
plt.scatter(x.numpy(),y.numpy(),color='g',label='real')
plt.legend()
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JSGf78k6-1605945971804)(output_96_0.png)]](https://img-blog.csdnimg.cn/20201121161510473.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY1MDM0OA==,size_16,color_FFFFFF,t_70#pic_center)
小结
主要介绍了PyTorch的基础知识,是后面章节的重要支撑。
















 2134
2134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











