






电商项目高级篇-02 elasticsearch-下
4.2、返回指定字段
返回单个字段
GET bank/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"balance": {
"order": "desc"
}
}
]
, "from": 5
, "size": 5
, "_source": "balance"
}
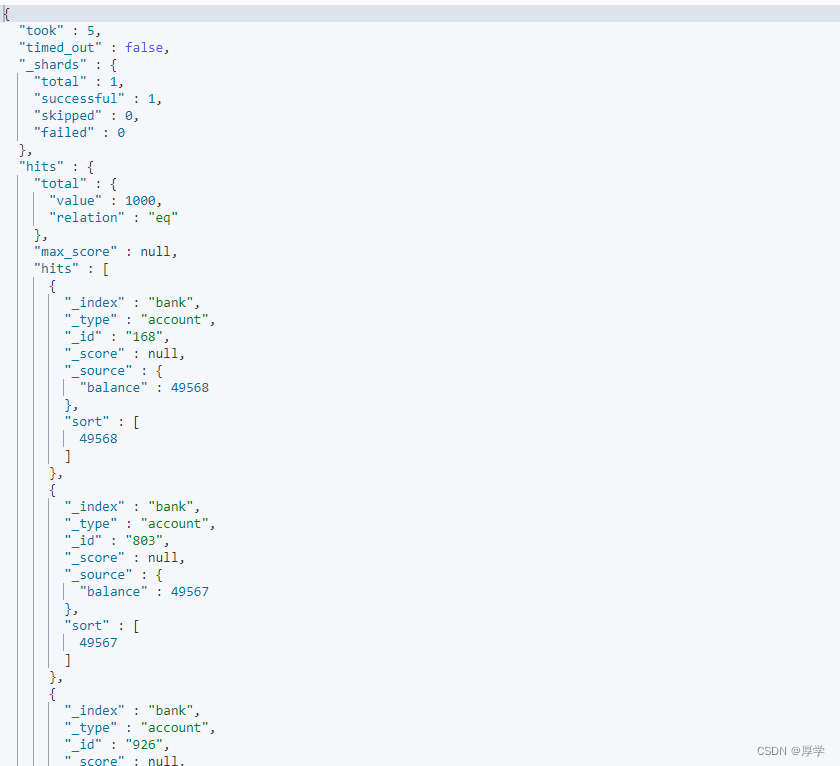
返回多个字段:
GET bank/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"balance": {
"order": "desc"
}
}
]
, "from": 5
, "size": 5
, "_source": ["balance","age"]
}
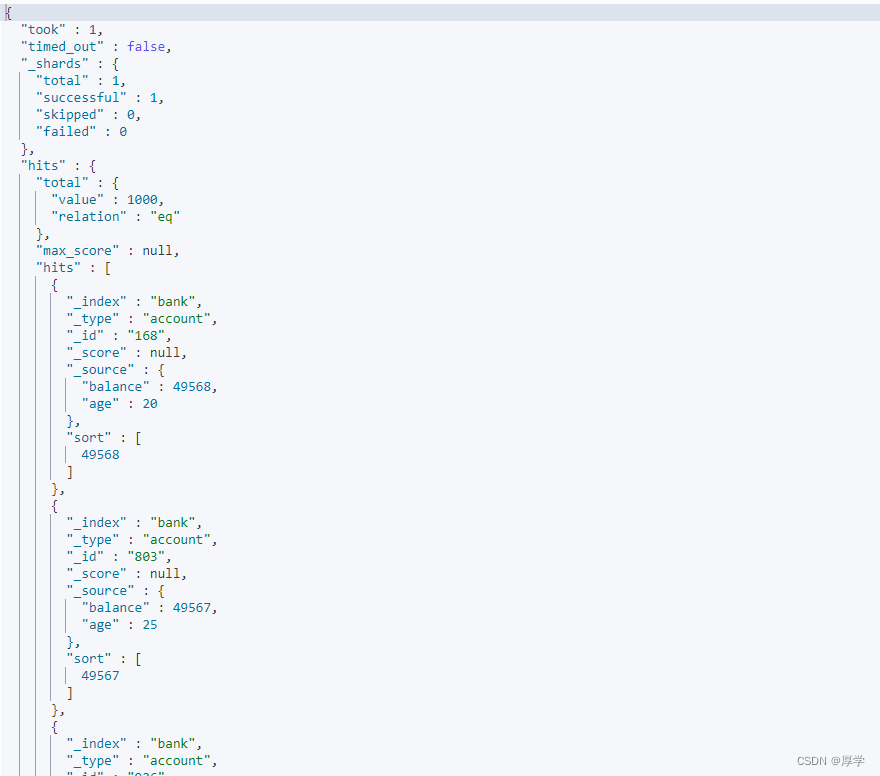
4.3、match查询
精确查询(对非字符串)
GET bank/_search
{
"query": {
"match": {
"account_number": "20"
}
}
}

模糊查询(对字符串)全文检索
GET bank/_search
{
"query": {
"match": {
"address": "kings"
}
}
}
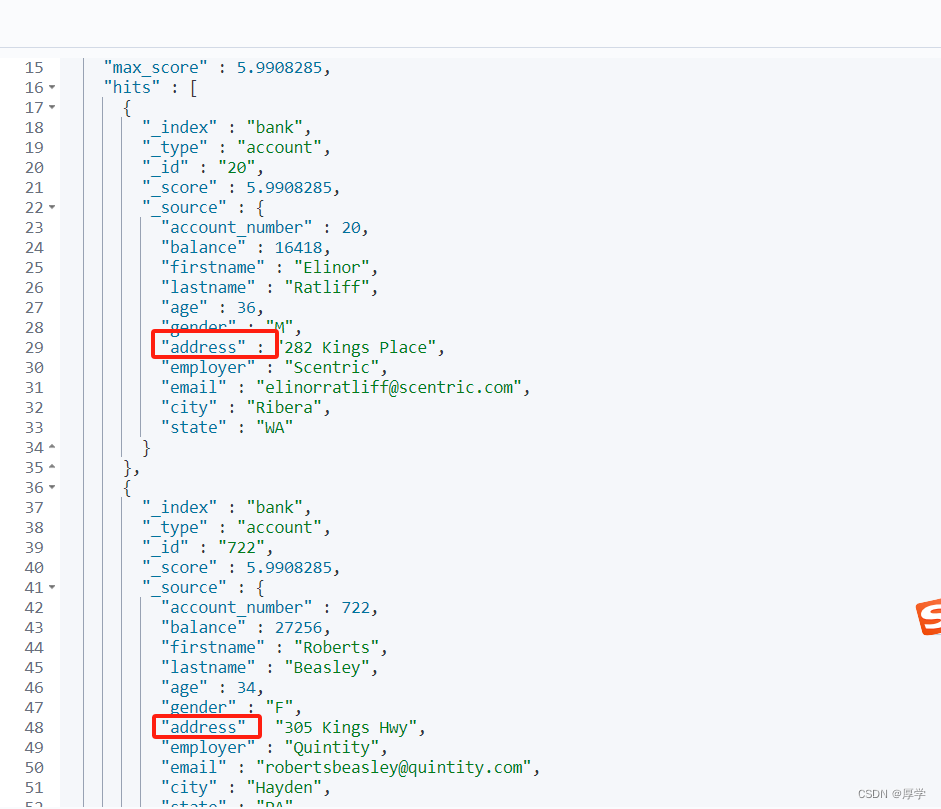
###根据评分倒排索引
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
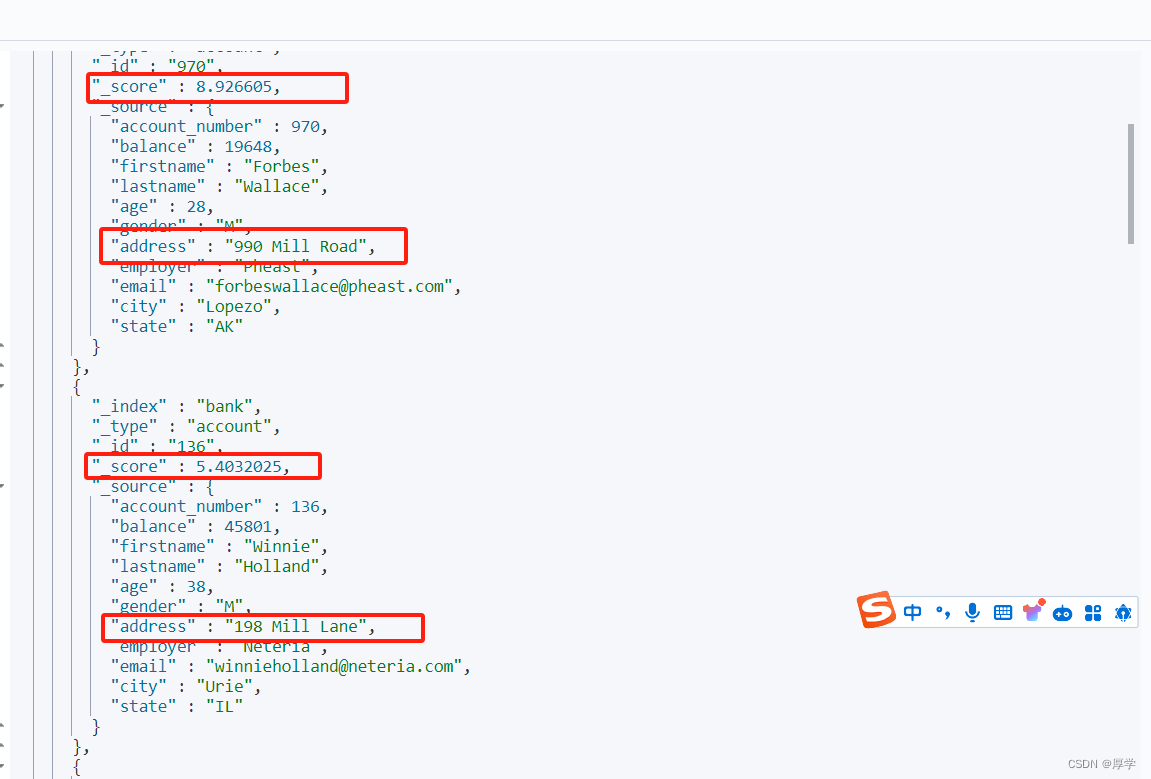
得益于倒排索引机制。会分词匹配。查询出结果
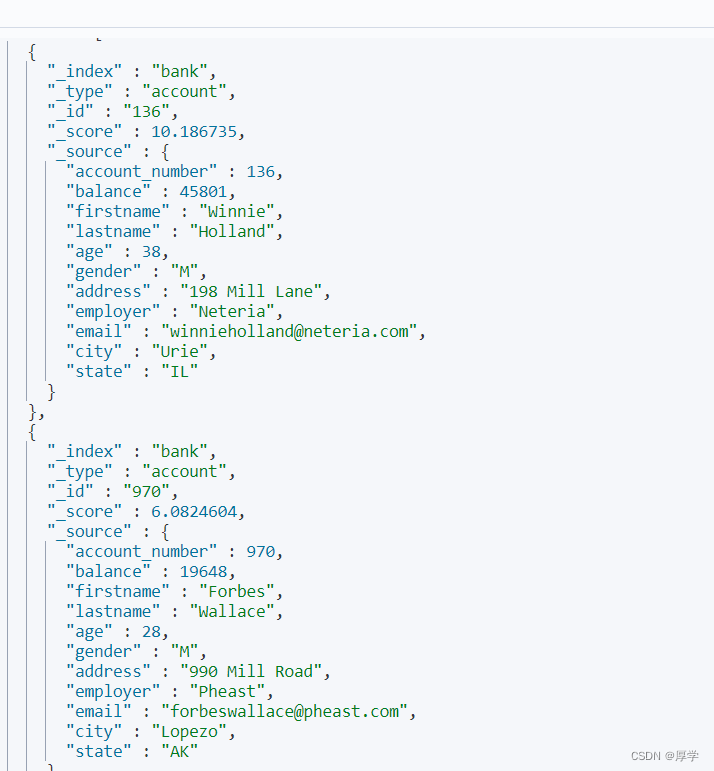
4.4、短语匹配:match_phrase(用于短语匹配。包含匹配)
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
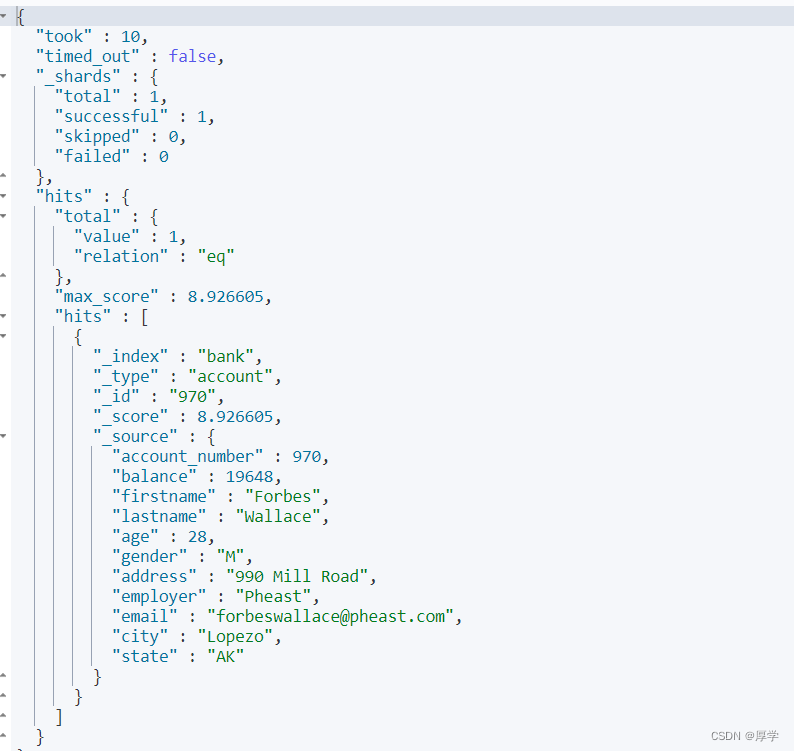
###字段.keyword相当于精确匹配
GET bank/_search
{
"query": {
"match": {
"address.keyword": "mill road"
}
}
}
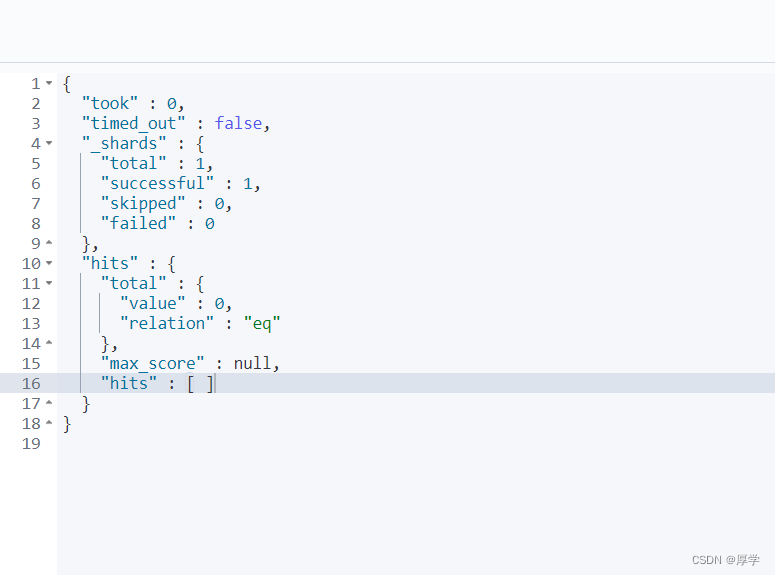
4.5、多字段匹配:multi_match
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["state","address"]
}
}
}
state或者address中包含mill的

4.6、bool复合查询
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
},
{
"match": {
"gender": "M"
}
}
],
"should": [
{
"match": {
"address": "lane"
}
}
],
"must_not": [
{
"match": {
"email": "baluba.com"
}
}
]
}
}
}
查询一定是地址包含mill和性别是M的,一定不是email包含baluba.com的,可以是address包含lane的结果集
4.7、filter过滤查询(不贡献相关性得分)
GET bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
}
}
}
}

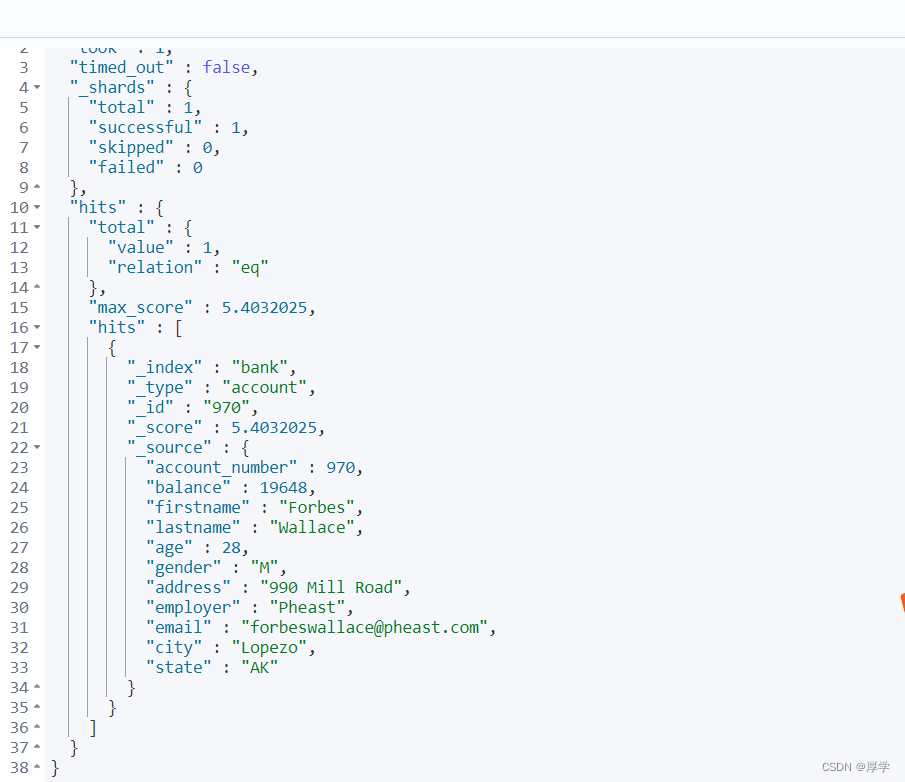
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
}
}
}
}
4.8、term(非文本检索)
match 可适用于文本检索。term适用于非文本检索
GET bank/_search
{
"query": {
"bool": {
"must": [
{"term": {
"age": {
"value": "28"
}
}},
{"match": {
"address": "990 Mill Road"
}}
]
}
}
}
4.9、执行聚合
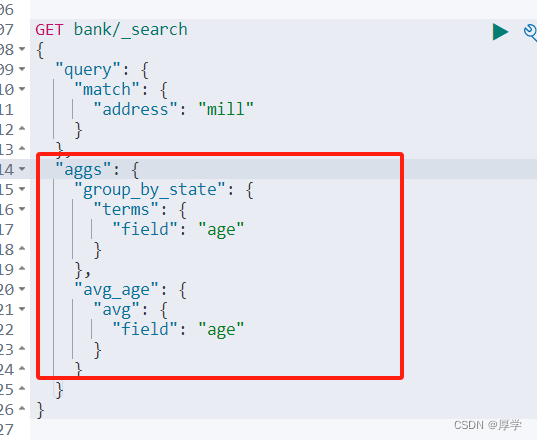
需求一:搜索 address 中包含 mill 的所有人 的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "age"
}
},
"avg_age": {
"avg": {
"field": "age"
}
}
},
"size": 0
}
aggs:聚合函数
terms:分布
avg:平均
size:0 不显示hits详情
需求二:按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
会用到子聚合
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_avg": {
"terms": {
"field": "age",
"size": 1000
}
}
}
}

子聚合:
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_avg": {
"terms": {
"field": "age",
"size": 1000
},
"aggs":{
"balance_avg":{
"avg": {
"field": "balance"
}
}
}
}
}
}

需求三:查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄
段的总体平均薪资
多重子聚合
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_agg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"gender_agg": {
"terms": {
"field": "gender.keyword",
"size": 100
},
"aggs": {
"balance_avg": {
"avg": {
"field": "balance"
}
}
}
},
"balance_avg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
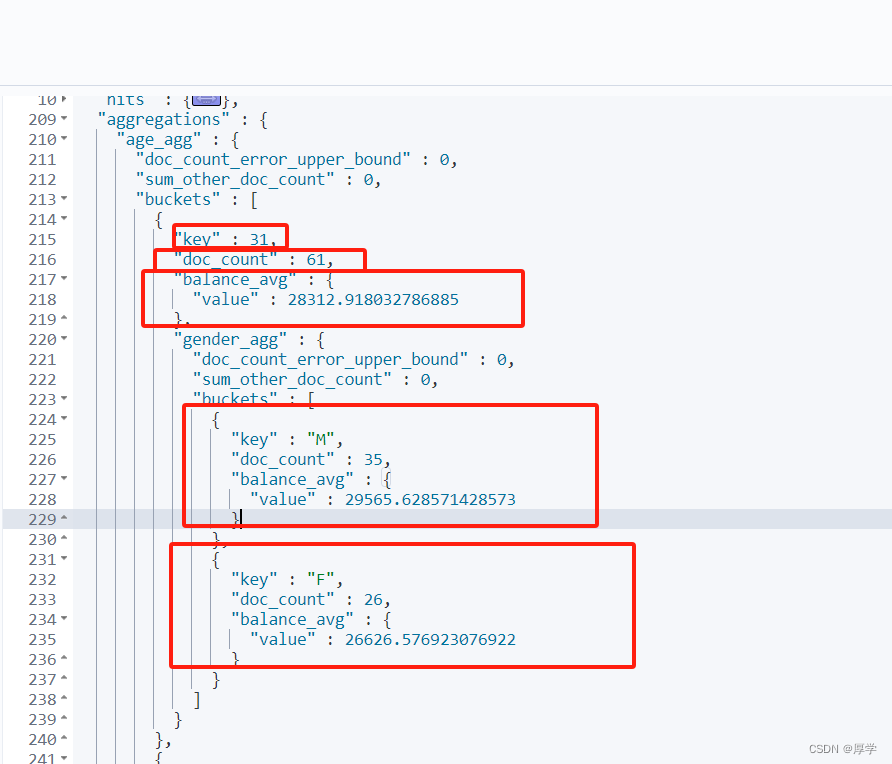
4.10、映射
查询映射
GET /bank/_mapping
修改映射
PUT /my-index
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
}
}

添加新的字段映射
PUT /my-index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
更新映射
对于已经存在的映射字段,我们不能更新。更新必须创建新的索引进行数据迁移
##数据迁移
1、获取原来银行的映射关系
GET /bank/_mapping
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
2、创建出新银行映射规则
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"employer": {
"type": "keyword"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "keyword"
}
}
}
}
3、查询新规则
GET /newbank/_mapping
4、数据迁移
POST _reindex
{
"source": {
"index": "bank"
},
"dest": {
"index": "newbank"
}
}
5、查询新索引
GET /newbank/_search
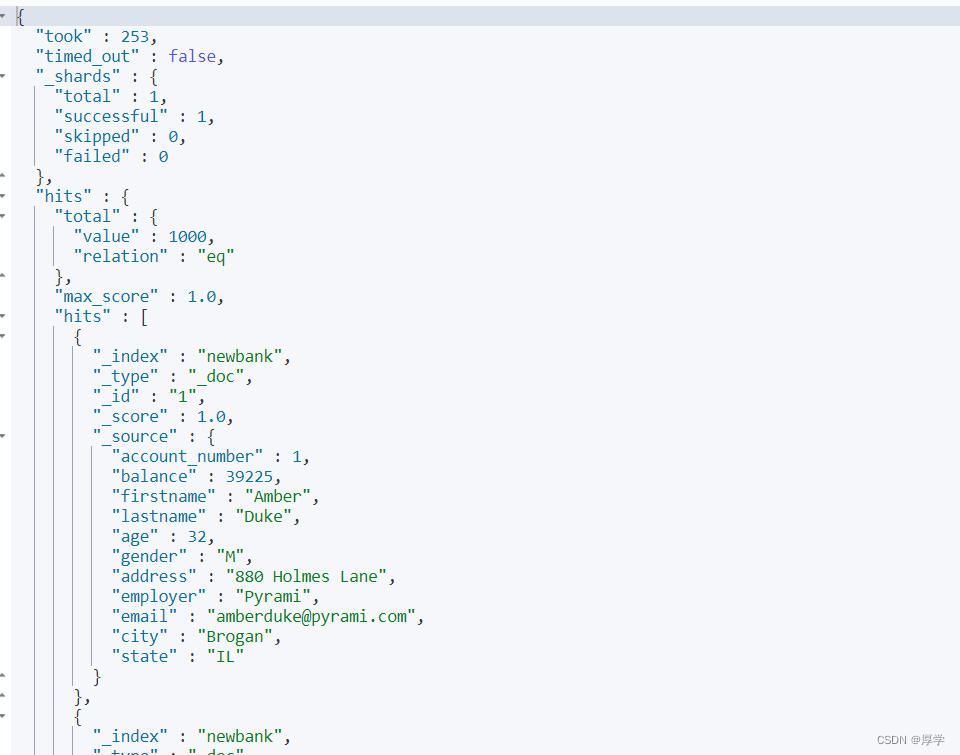
4.11、ik分词器
标准分词器不好用,是专门用来分割英文的。不太支持中文(它会分成一个一个字的)
比如:
POST /_analyze
{
"analyzer": "standard",
"text":"今天的清蒸鲈鱼蒸得还行"
}
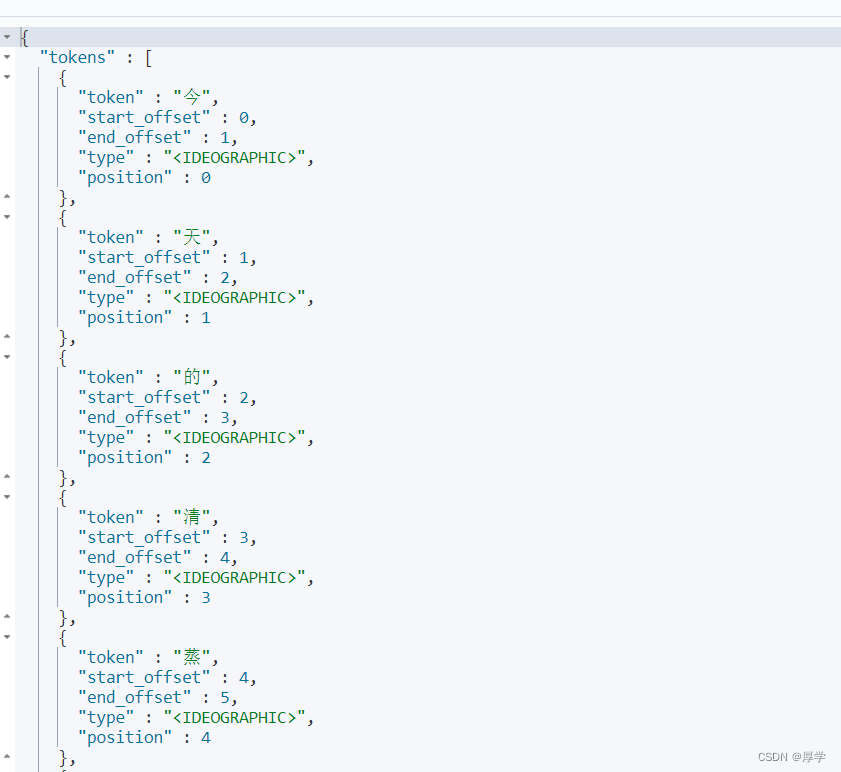
下载ik分词器
添加链接描述
复制到linux这个文件夹下
确认是否安装好分词器
进到容器内部,然后输入命令:
elasticsearch plugin list

出现ik说明安装成功。
然后重启容器
然后执行这段代码:
POST _analyze
{
"analyzer": "ik_smart",
"text": "今天的清蒸鲈鱼蒸得还行"
}
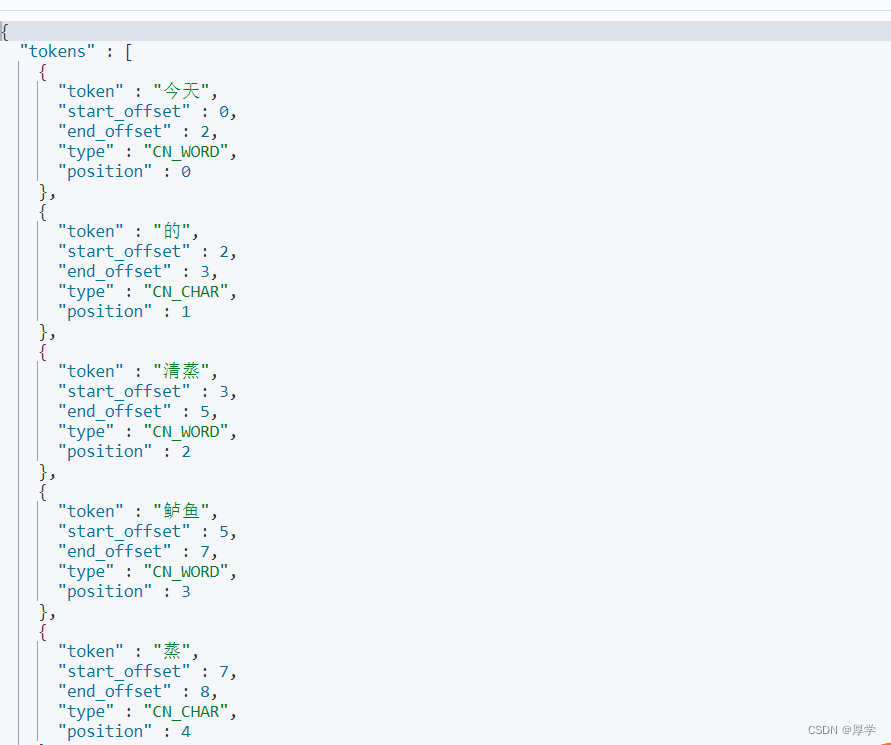
目前还稍微比较智能化一些了
但是实际上不能满足网络上新的单词搜索
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "你在干嘛哎哟"
}

4.12、自定义分词
4.12.1、linux下安装nginx
1、暂时先启动一个nginx
docker run -p 80:80 --name nginx -d nginx:1.10
2、将容器内的配置文件拷贝到当前目录
docker container cp nginx:/etc/nginx .
3、修改文件名称
cd ../
mv nginx conf
4、把这个 conf 移动到/mydata/nginx 下

5、执行命令删除原容器:docker rm $ContainerId
6、创建新的 nginx
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10

将index.html放到html文件里。就可以访问nginx首页了

##7、将所有es关于分词器的内容,nginx这边新建文件夹保管

8、访问该fcword.txt
可以访问

###9、ik分词器绑定fcword.txt
cd /mydata/elasticsearch/plugins/ik/config
vi IKAnalyzer.cfg.xml
开启远程配置
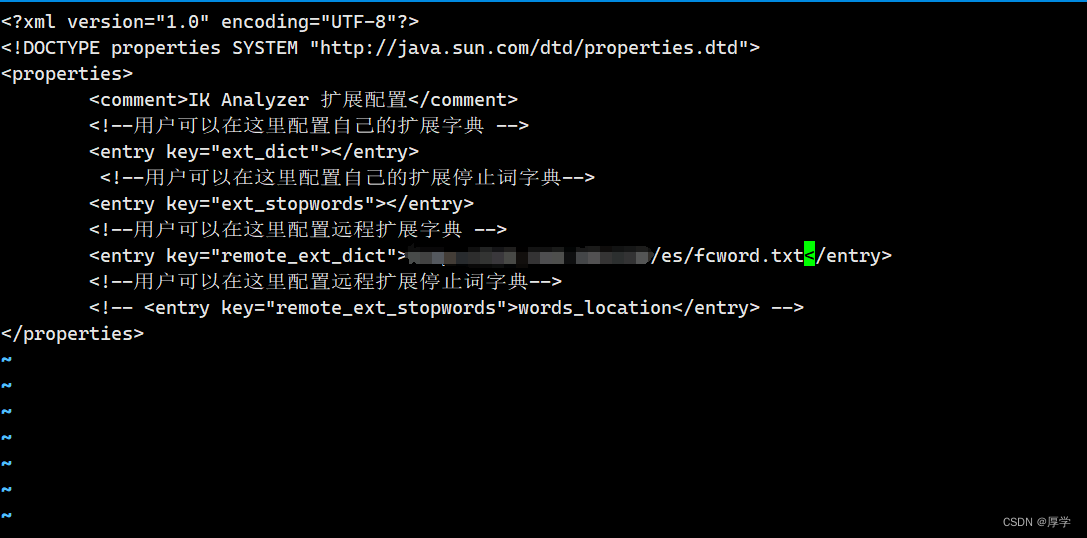
虚拟机地址/es/fcword.txt
分词前:

重启容器实例
分词后:


已达到分词效果
5、java集成es
5.1、模块搭建
新建module
创建一个springboot模块


pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.ljs.gulimall</groupId>
<artifactId>gulimall-search</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>gulimall-search</name>
<description>检索服务</description>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
<dependencies>
<!--导入common-->
<dependency>
<groupId>com.ljs.gulimall</groupId>
<artifactId>gulimall-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--导入es的高阶api-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
application.properties
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.application.name=gulimall-search
GulimallSearchApplication
package com.ljs.gulimall.search;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class GulimallSearchApplication {
public static void main(String[] args) {
SpringApplication.run(GulimallSearchApplication.class, args);
}
}
GulimallElasticsearchConfig
package com.ljs.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class GulimallElasticsearchConfig {
@Bean
public RestHighLevelClient getClient(){
return new RestHighLevelClient(RestClient.builder(new HttpHost("虚拟机ip",
9200,"http")));
}
}
测试类
GulimallSearchApplicationTests
package com.ljs.gulimall.search;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallSearchApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println(client);
}
}
运行结果:
已经获取到bean容器的实例

5.2、es index 保存数据
GET /user/_search

没有user这个索引
GulimallElasticsearchConfig
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
GulimallSearchApplicationTests
@Test
public void indexData() throws IOException {
// 创建indexRequest对象user index索引
IndexRequest indexRequest = new IndexRequest("user");
// 设置索引id
indexRequest.id("1");
User user = new User();
user.setAge(18);
user.setGender("男");
user.setName("帅淞");
// 要保存的内容转成JSON String
String jsonString = JSON.toJSONString(user);
// 将保存的内容放到indexRequest对象
indexRequest.source(jsonString, XContentType.JSON);
// 执行操作
IndexResponse index = client.index(indexRequest, GulimallElasticsearchConfig.COMMON_OPTIONS);
// 提取响应数据
System.out.println(index);
}
@Data
class User{
private Integer age;
private String name;
private String gender;
}

执行完毕说明保存成功。
再次查询。发现有值

5.3、复杂检索

GulimallSearchApplicationTests
@Test
public void searchData() throws IOException {
// 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定检索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构造检索条件
sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
System.out.println(sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 执行操作
SearchResponse response = client.search(searchRequest, GulimallElasticsearchConfig.COMMON_OPTIONS);
// 提取响应数据
System.out.println(response.toString());
}
打印检索条件
{
"query": {
"match": {
"address": {
"query": "mill",
"operator": "OR",
"prefix_length": 0,
"max_expansions": 50,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1.0
}
}
}
}
打印检索结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}]
}
}
###构造聚合条件
TermsAggregationBuilder termBuilder = AggregationBuilders.terms("group_by_state").field("age");
AvgAggregationBuilder avgBuilder = AggregationBuilders.avg("avg_age").field("age");
sourceBuilder.aggregation(termBuilder);
sourceBuilder.aggregation(avgBuilder);
{
"query": {
"match": {
"address": {
"query": "mill",
"operator": "OR",
"prefix_length": 0,
"max_expansions": 50,
"fuzzy_transpositions": true,
"lenient": false,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"boost": 1.0
}
}
},
"aggregations": {
"group_by_state": {
"terms": {
"field": "age",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [{
"_count": "desc"
}, {
"_key": "asc"
}]
}
},
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
返回结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}]
},
"aggregations": {
"avg#avg_age": {
"value": 34.0
},
"lterms#group_by_state": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [{
"key": 38,
"doc_count": 2
}, {
"key": 28,
"doc_count": 1
}, {
"key": 32,
"doc_count": 1
}]
}
}
}
java与在es上执行结果是一致的
###获取所有查到的数据
使用在线json生成工具,再生成一个实体类
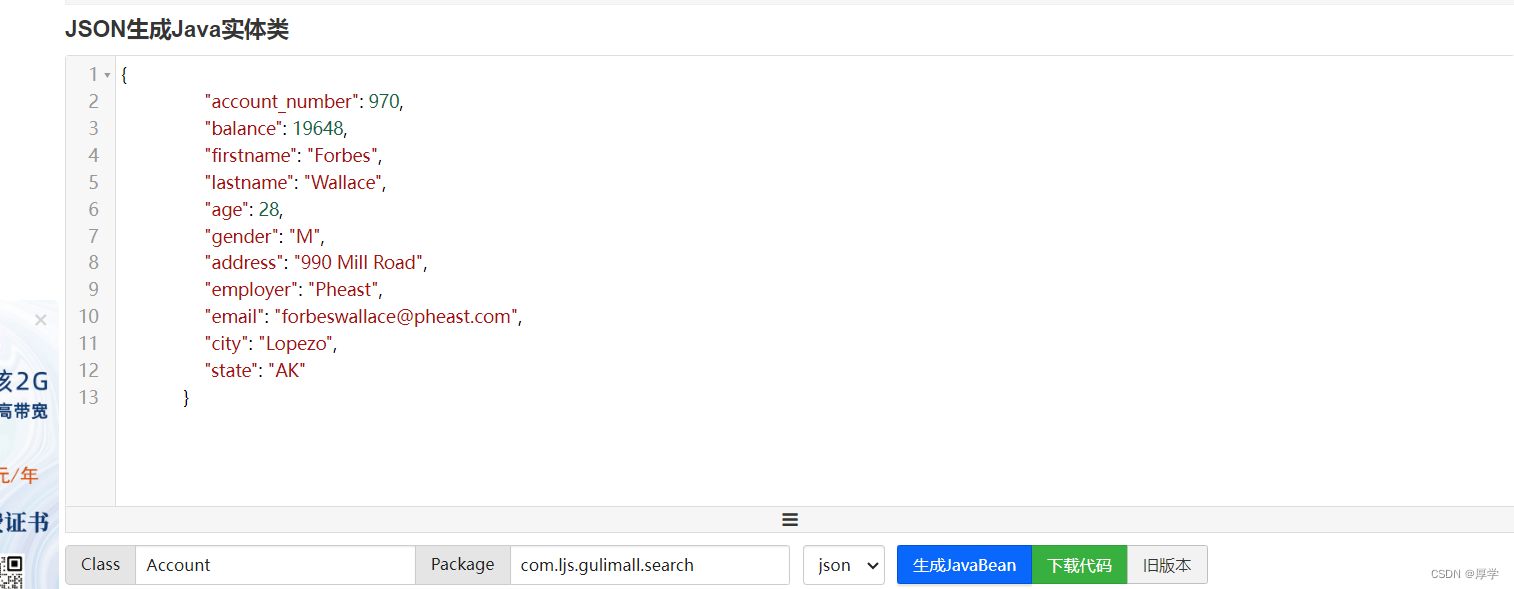
将生成的实体类复制成静态内部类。到测试类中
// 获取到所有查询到的数据
SearchHits hits = response.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
// 获取到searchHit的source的JSON字符串。转换成实体类
String sourceAsString = searchHit.getSourceAsString();
Account account = JSON.parseObject(sourceAsString, Account.class);
System.out.println("account:"+account);
}
@Data
@ToString
static class Account {
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
打印效果:

###获取检索分布信息
// 获取检索到的分析信息
Aggregations aggregations = response.getAggregations();
Terms groupTerm = aggregations.get("group_by_state");
Avg avg = aggregations.get("avg_age");
for (Terms.Bucket bucket : groupTerm.getBuckets()) {
System.out.println("年龄:"+bucket.getKey()+"分布人数:"+bucket.getDocCount());
}
System.out.println("年龄平均值:"+avg.getValue());
















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









