









| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年5月9日14:33:05 | V0.1 | 宋全恒 | 新建文档 |
简介
GitHub项目 vllm-project

官方网站上解释了Fast、和flexible and easy to use的原因。

注,如果要使用ModelScope中的模型,请设置环境变量:
export VLLM_USE_MODELSCOPE=True
参考链接
| 网页 | 描述 |
|---|---|
| 大模型推理加速工具:vLLM | 描述了安装,离线推理和在线服务的简单演示 |
| 比HuggingFace快24倍!伯克利LLM推理系统开源碾压SOTA,GPU砍半 | 描述了优点,并且有很多的图。 |
| 【LLM】vLLM部署与int8量化-CSDN博客 | 👍👍文章中讲述了关于Decoding methods的许多的内容,具体包括Greedy Search, Beam Search, Sampling, Top-K sampling, Tpo-P(nucleus) ,其对应于代码中的SamplingParams |
| 大模型推理部署:LLM 七种推理服务框架总结_大模型推理框架-CSDN博客 | 👍👍👍文章主要是描述了七种推理框架,并且提供了一个vLLM离线推理的模型。vllm,TGI,CTranslate2, OpenLLM, Ray Server, MLC LLM, Deep Speed |
| 基于vllm,探索产业级llm的部署 - jsxyhelu - 博客园 | 使用了魔搭社区,并作为在线服务,同时使用Meta-Llama进行交互的实例。 |
| Quickstart — vLLM | 👍👍👍👍👍官网介绍,详细的介绍了offline Batched Inference, OpenAI-Comatible Server、Using OpenAI Chat API with vLLM |
其优点:
- PagedAttention
- memory sharing
- 当用单个 prompt 产出多个不同的序列时,可以共享计算量和显存
- Continuous batching
其优点如下所示:
- vLLM通过PagedAttention机制,可以高效地管理大语言模型的keys和values,显著提高吞吐量,高吞吐量服务。
- memory sharing机制可以实现不同样本间的显存共享,进一步提升吞吐量。
- vLLM兼容主流的预训练模型,可以不修改模型结构就获得显著的加速效果,与OpenAPI兼容。
- 整体来说,vLLM是目前加速大模型推理的最先进解决方案之一,可以达到其他框架的24倍吞吐量提升。
vllM主要是为了解决高内存消耗和计算成本的挑战,【LLM】vLLM部署与int8量化-CSDN博客

从上图可以看出,vLLM可以显著的提升吞吐量。
在【LLM】vLLM部署与int8量化-CSDN博客这里也详细的描述了Cache的作用,Cache可以减少重复计算,并利用缓存中的数据,提高计算效率。
安装
pip install vllm
使用
离线推理
测试指标
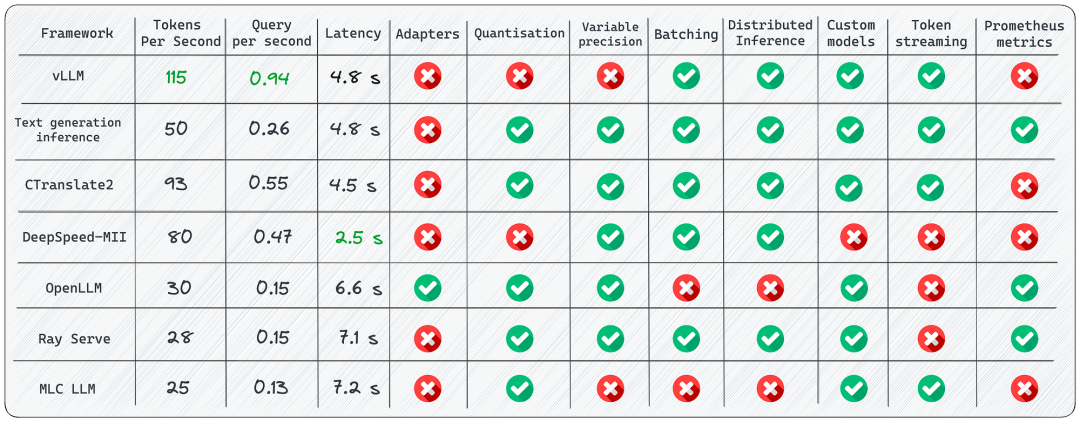
注,上图中显示了推理时的一些常用性能评估指标。 位于博客 大模型推理部署:LLM 七种推理服务框架总结_大模型推理框架-CSDN博客
使用基本方式
在使用的时候,基本上采用如下的方式:
from vllm import LLM
llm = LLM(model=...) # Name or path of your model
output = llm.generate("Hello, my name is")
print(output)
指定Decoding策略
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts.
llm = LLM(model="lmsys/vicuna-7b-v1.3") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.
看来大模型运行的时候,需要本地有这个模型,直接使用model参数加载即可,构造器。
prompt: 提示,促进,引起,激发
在离线推理,使用offline Batched Inference,
from vllm import LLM, SamplingParams
import torch
# device = torch.device('cuda:2')
llm = LLM(model="../Llama-2-7B-Chat-fp16", gpu_memory_utilization=0.7)
# llm.to(device)
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
"One way to crack a password",
"I know unsensored swear words such as"
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)

这里的
gpu_memory_utilization参数就是vLLM提供的内存优化参数。事实上,要加载半精度的Llama-2-7B需要大约29152MiB的内存空间
当然,空间不可能无限优化下去,如果进一步测试可以发现
gpu_memory_utilization=0.3是能够加载一个7B模型的极限(大约15G)
这也是一个离线推理的例子:
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

实际例子-gpt2-large
注,还是需要在本地已经下载了模型权重文件的,可以把大模型当成一个黑盒子。
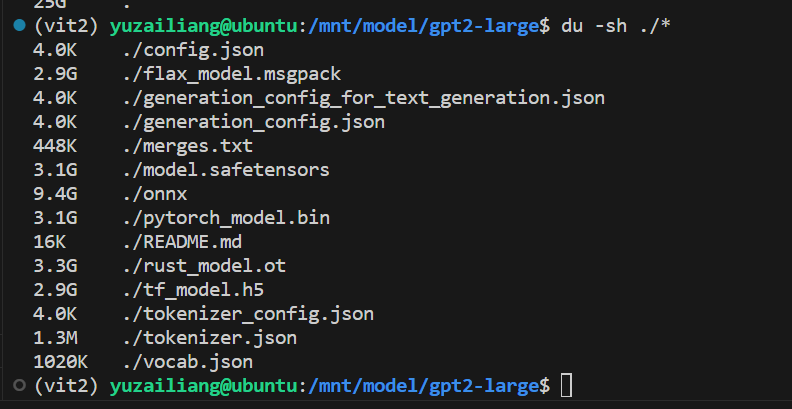
可以看到模型的权重文件,有25G,还是比较大的。
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
"""
@author: songquanheng
@file: __init__.py.py
@time: 2022/12/14 15:26
@desc: 使用vllm测试
"""
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="/mnt/model/gpt2-large")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
实验结果为:
(vit2) yuzailiang@ubuntu:~/vllm_test$ python vllm_test.py
INFO 05-09 09:34:57 llm_engine.py:73] Initializing an LLM engine with config: model='/mnt/model/gpt2-large', tokenizer='/mnt/model/gpt2-large', tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=1024, download_dir=None, load_format=auto, tensor_parallel_size=1, quantization=None, enforce_eager=False, seed=0)
/mnt/model/gpt2-large/INFO 05-09 09:35:40 llm_engine.py:223] # GPU blocks: 10913, # CPU blocks: 1456
INFO 05-09 09:35:50 model_runner.py:394] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 05-09 09:36:19 model_runner.py:437] Graph capturing finished in 28 secs.
Processed prompts: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.07it/s]
Prompt: 'Funniest joke ever:', Generated text: " How to keep your offspring safe from the man who finally solved the mystery of Buggies\n\nIn the mean time, Kim Kardashian and Kanye West have pledged to help spread awareness and get the word out about the problem.\n\n\nBut what about the male victims?\n\n\nChristopher Parker, from London, has come out after his birthday.\n\n\nHe said: 'It was just a normal day... but then, not a second later, I was groped, cursed at, warned not to use the train again and not to go on any other public transport.\n\n\n'I went to the local library where I looked for people who have had similar experiences, but to no avail.'\n\n'Male victims? All it took was a look - and it was terrible for me to see.'\n\n\nTransport bosses say they are already planning to tighten up security on and off the underground to try and deter people from hijacking older, unattended kids.\n\n\nMike Gerl"
Prompt: 'The capital of France is', Generated text: " currently undergoing a major history shift, and one of the top natural history destinations in the world. Europe is now home to many more internationally famous museums and monuments. The Upper Plaza, founded in 1846, boasts more than 10,000 works of art—including the most famous painting in the world, the Sistine Chapel, and the Mona Lisa, as well as more than 13,000 statues of lesser known, but still unforgettable, artists. Luxury designer Louis Vuitton, whose brand was founded in Paris in 1857, is the largest clothing and jewelry designer in the world. In addition to doing business in many of the world's major cities, Louis Vuitton has offices in France, Russia, Argentina, and Mexico. This is just one of many inspirational celebrities that have made Paris their home.\n\nTake a stroll through the Louvre and the Arc de Triomphe by tube or your own private elevator and see the incredible feats of artists, scientists, and inventors all over"
Prompt: 'The future of AI is', Generated text: ' now way ahead of it with financial services, not just in other industries but also in a wide array of applications."\n\nThe key drivers in the evolution of AI will be commercial and geopolitical trends, according to Bivens. For example, in the future many of the payments transactions will be made between governments and corporations. "Commercialization will drive AI at a higher level. The money-transfer industry could be AI-targeted. In some cases, you\'re not going to know what the application is for until you\'re thinking about it," he said.'
在线服务
例子
python -m vllm.entrypoints.openai.api_server --model lmsys/vicuna-7b-v1.3
启动了在线服务之后,可以使用Rest调用服务
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "lmsys/vicuna-7b-v1.3",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
看起来,–model可以指定各种各样的大模型,然后通过-d来指定提示词以及生成的配置。
在官网上Quickstart — vLLM,可以更加具体的看到一些使用的例子
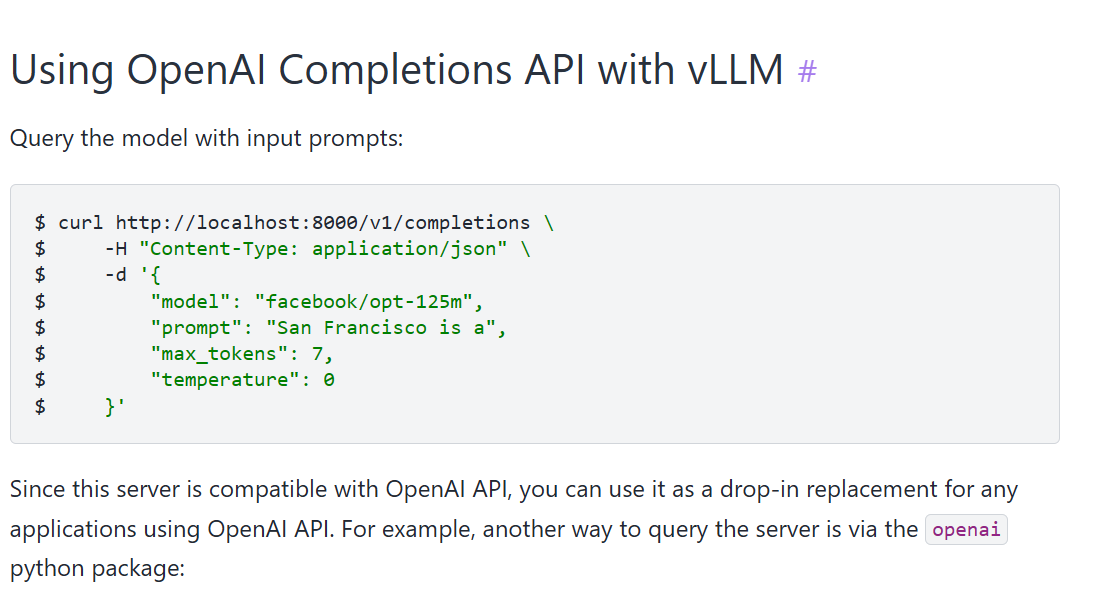
使用gpt2-large实验
首先在服务器端启动api_server服务。
(vit2) yuzailiang@ubuntu:/mnt/model/gpt2-large$ python -m vllm.entrypoints.openai.api_server --model /mnt/model/gpt2-large/
INFO 05-09 11:21:04 api_server.py:719] args: Namespace(allow_credentials=False, allowed_headers=['*'], allowed_methods=['*'], allowed_origins=['*'], block_size=16, chat_template=None, disable_log_requests=False, disable_log_stats=False, download_dir=None, dtype='auto', enforce_eager=False, engine_use_ray=False, gpu_memory_utilization=0.9, host=None, load_format='auto', max_context_len_to_capture=8192, max_log_len=None, max_model_len=None, max_num_batched_tokens=None, max_num_seqs=256, max_paddings=256, max_parallel_loading_workers=None, model='/mnt/model/gpt2-large/', pipeline_parallel_size=1, port=8000, quantization=None, response_role='assistant', revision=None, seed=0, served_model_name=None, swap_space=4, tensor_parallel_size=1, tokenizer=None, tokenizer_mode='auto', tokenizer_revision=None, trust_remote_code=False, worker_use_ray=False)
INFO 05-09 11:21:04 llm_engine.py:73] Initializing an LLM engine with config: model='/mnt/model/gpt2-large/', tokenizer='/mnt/model/gpt2-large/', tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=1024, download_dir=None, load_format=auto, tensor_parallel_size=1, quantization=None, enforce_eager=False, seed=0)
INFO 05-09 11:21:16 llm_engine.py:223] # GPU blocks: 10913, # CPU blocks: 1456
INFO 05-09 11:21:27 model_runner.py:394] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 05-09 11:21:58 model_runner.py:437] Graph capturing finished in 31 secs.
WARNING 05-09 11:21:58 api_server.py:115] No chat template provided. Chat API will not work.
INFO: Started server process [17663]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
可以看到,在8000端口已经启动了服务。这样可以通过Rest的客户端与服务器进行交互了。
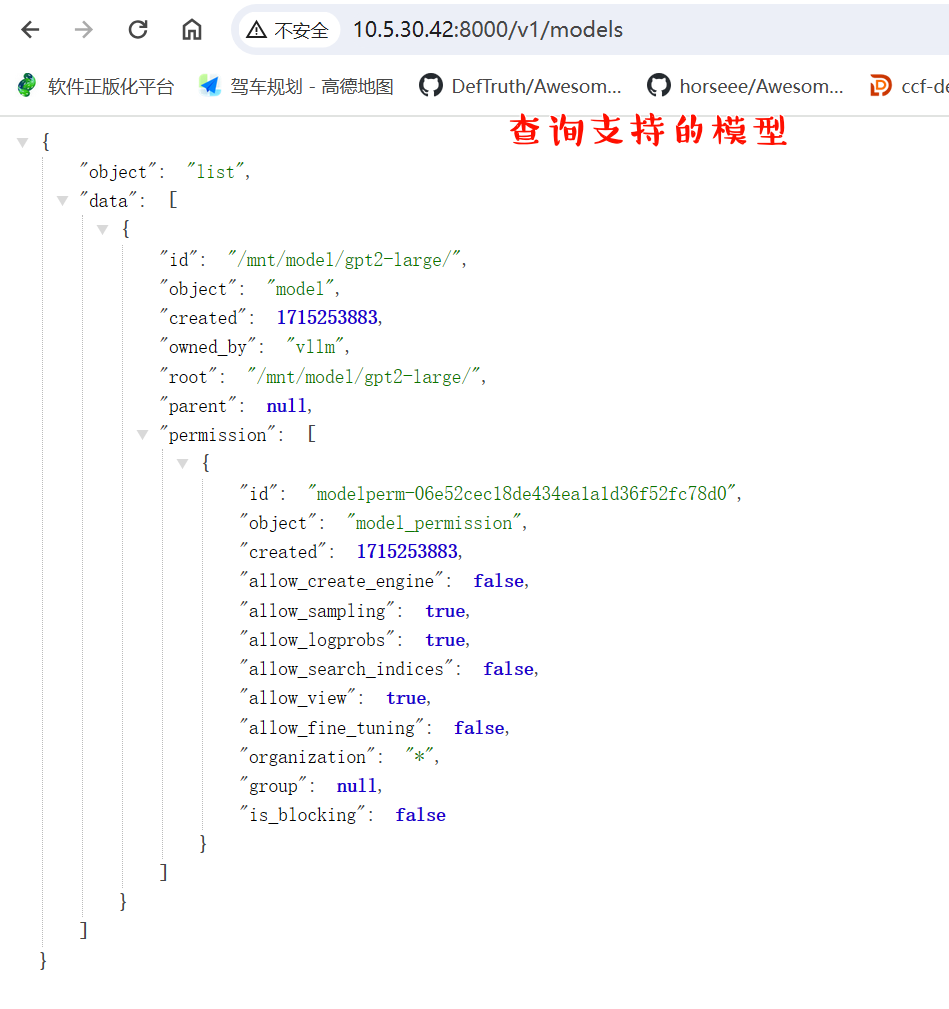
使用类似Postman的客户端,如下输入,可以看到通过接口的输出:
POST http://10.5.30.42:8000/v1/completions
application/json
{
"model":"/mnt/model/gpt2-large/",
"prompt": "San Francisco is a",
"temperature": 0
}
响应为:
-------------------------------------------------
{
"id": "cmpl-3dc95c24b94846a19de837deebc856af",
"object": "text_completion",
"created": 1917432,
"model": "/mnt/model/gpt2-large/",
"choices": [
{
"index": 0,
"text": " city of many different cultures, and the diversity of the people who live here is",
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 4,
"total_tokens": 20,
"completion_tokens": 16
}
}
总结
本文整理了vLLM的优点,主要是Paged Attention,并具有Continuous batch的特点,文章主要是包含了vLLM安装,并包含离线推理和在线服务的描述。
通过实践离线推理和在线服务,

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









