







| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年5月28日15:03:49 | V0.1 | 宋全恒 | 新建文档 |
简介
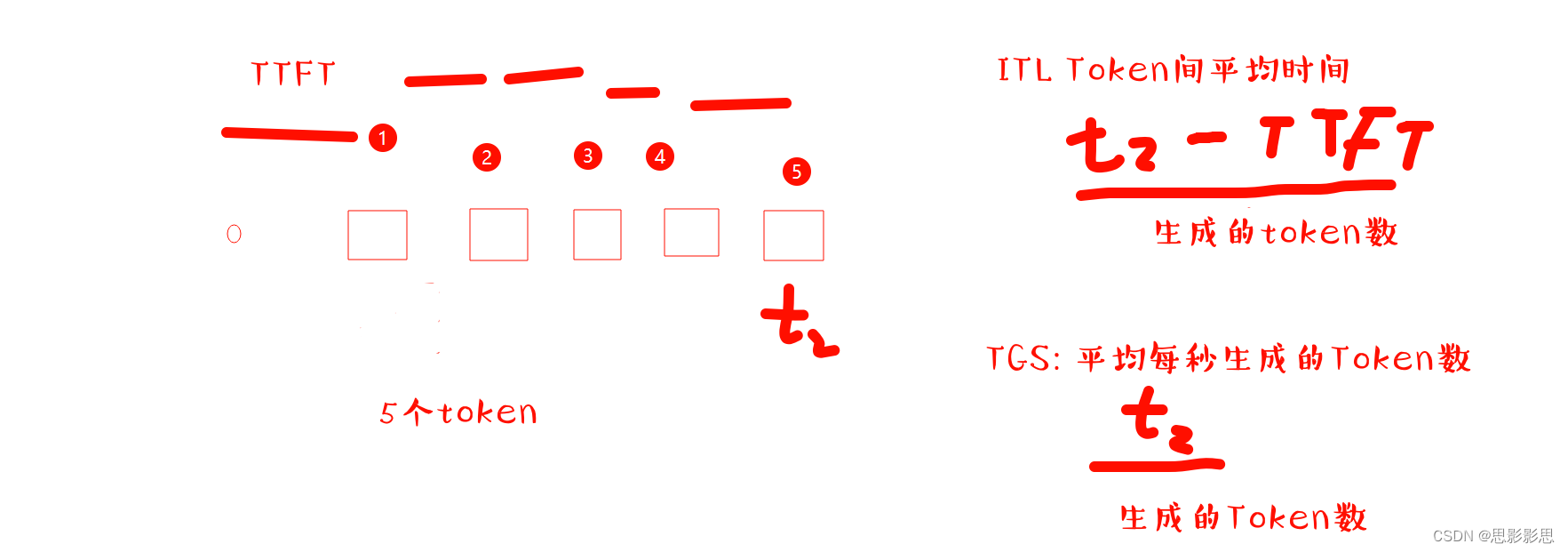
本文主要用于求解大模型推理过程中的几个指标:
主要是TTFT,ITL, TGS
代码片段
import os
data_dir = "/workspace/models/"
model_name = "Llama-2-7b-hf"
data_dir = data_dir + model_name
import transformers
from transformers import AutoTokenizer, AutoModel
from transformers import LlamaForCausalLM, LlamaTokenizer
import time
import torch
# from ixformer.inference.models.chatglm2_6b import ChatGLMForConditionalGeneration
# from torch.cuda import profiler
import argparse
import pickle
# from thop import profile
import json
from datetime import datetime
def main(args):
tokenizer = AutoTokenizer.from_pretrained(data_dir, trust_remote_code=True, device_map="auto")
model = transformers.AutoModelForCausalLM.from_pretrained(data_dir, trust_remote_code=True, device_map='auto')
INPUT_LEN = [32,64,128,256,512,1024,2048]
# INPUT_LEN = [1024, 2048]
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
res_file = "result_" + model_name + "_fp16_" + current_time + ".txt"
print("res_file {res_file}")
with open(res_file, "w") as f_result:
with open("input_request_list","rb") as f:
input_request_list = pickle.load(f)
for input_request in input_request_list:
print(input_request)
test_len = input_request[1]
if test_len not in INPUT_LEN:
continue
print("testing len:{}...".format(test_len))
query, prompt_len, output_len = input_request
inputs = tokenizer(query, return_tensors='pt').to('cuda')
geneate_ids = model.generate(inputs.input_ids, max_new_tokens=1, max_length=None, do_sample=False)
# response, _ = model.chat(tokenizer, query, max_new_tokens=1, do_sample=False, history=[])
#torch.cuda.synchronize()
print("start TTFT test...")
TTFT_list = []
for _ in range(2):
start_time = time.time()
geneate_ids = model.generate(inputs.input_ids, max_new_tokens=1, max_length=None, do_sample=False)
# response, _ = model.chat(tokenizer, query, do_sample=False, max_new_tokens=1,max_length=None, history=[])
#torch.cuda.synchronize()
end_time = time.time()
TTFT = (end_time - start_time) * 1000
print(TTFT)
TTFT_list.append(TTFT)
TTFT = sum(TTFT_list)/len(TTFT_list)
print("time to first token:{:2f} ms".format(TTFT))
print("start ITL test...")
ITL_list = []
out_tokens_num = 0
for _ in range(2):
start_time = time.time()
geneate_ids = model.generate(inputs.input_ids, max_new_tokens=50, max_length=None, do_sample=False)
outputs = geneate_ids.tolist()[0][len(inputs["input_ids"][0]):]
# response, _ = model.chat(tokenizer, query, max_new_tokens=50, do_sample=False, history=[])
#torch.cuda.synchronize()
end_time = time.time()
# out_tokens_num = len(tokenizer(response).input_ids)
out_tokens_num = len(outputs)
print("out_tokens_num:{}".format(out_tokens_num))
ITL = ((end_time - start_time) * 1000 - TTFT) / out_tokens_num
print(ITL)
ITL_list.append(ITL)
ITL = sum(ITL_list) / len(ITL_list)
print("inter-token latency:{:2f} ms".format(ITL))
f_result.write("In len:{}\n".format(test_len))
f_result.write("Out len:{}\n".format(out_tokens_num))
f_result.write("TTFT:{:.2f}\n".format(TTFT))
f_result.write("ITL:{:.2f}\n".format(ITL))
f_result.write("\n")
f_result.flush()
if __name__ == "__main__":
main()
调试过程
vscode配置调试代码
具体可以参见, 05-16 周四 vscode 搭建远程调试环境
launch.json配置
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "LLaMa2 推理",
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2812
2812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









