






历史观点
Intel 处理器系列俗称 x86
程序编码
机器级代码
对于机器级编程来说,其中两种抽象尤为重要。第一种是由指令集体系结构或指令集架构来定义机器级程序的格式和行为,它定义了处理器状态、指令的格式,以及每条指令对状态的影响。第二种抽象是,机器级程序使用的内存地址是虚拟地址,提供的内存模型看上去是一个非常大的字节数组。存储器系统的实际实现是将多个硬件存储器和操作系统软件组合起来。
代码示例
要查看机器代码文件的内容,有一类称为反汇编器的程序非常有用。这些程序根据机器代码产生一种类似于汇编代码的格式。
1.x86-64 的指令长度从 15 个字节不等。常用的指令以及操作数较少的指令所需的字节数少,而那些不太常用或操作数较多的指令所需字节数较多。
2.设计指令格式的方式是,从某个给定位置开始 ,可以将字节唯一地解码成机器指令。例如,只有指令 pushq %rbx 以字节值 53 开头的。
3. 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码。它不需要访问该程序的源代码或汇编代码。
4. 反汇编器使用的指令命名规则与 GCC 生成的汇编代码使用的有些细微的差别我们的示例中,它省略了很多指令结尾的 ‘q’ 。这些后缀是大小指示符,在大多数情况中可以省略。相反,反汇编器给 call ret 指令添加了'矿后缀,同样,省略这些后缀也没有问题。
关于格式的注解
在C程序中插入汇编代码有两种方法。笫一种是,我们可以编写完整的函数,放进一个独立的汇编代码文件中,让汇编器和链接器把它和用 语言书写的代码合并起来。笫二种方法是,我们可以使用 GCC 的内联汇编特性,用 asm 伪指令可以在 程序中包含简短的汇编代码。这种方法的好处是减少了与机器相关的代码量。
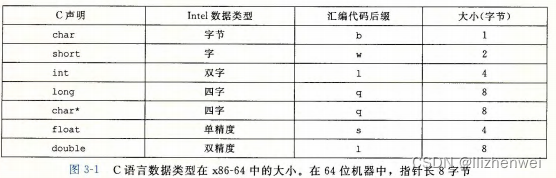
数据格式
访问信息
一个 x86-64 的中央处理单元 (CPU) 包含一组 16 个存储 64 位值的通用目的寄存器。
这些寄存器用来存储整数数据和指针。
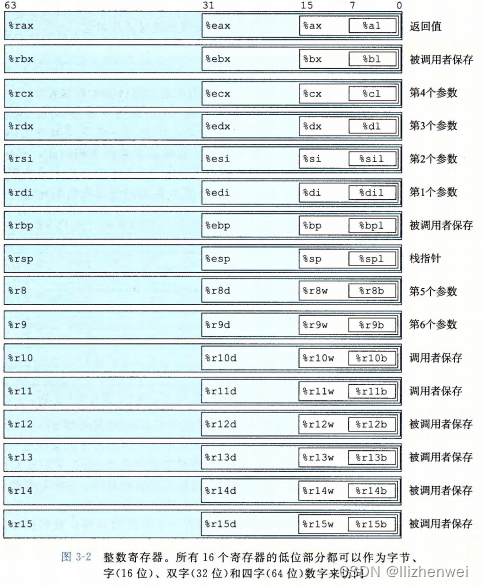
如图 3-2 中嵌套的方框标明的,指令可以对这 16 个寄存器的低位字节中存放的不同大小的数据进行操作。字节级操作可以访问最低的字节, 16 位操作可以访问最低的 个字节, 32 位操作可以访问最低的 个字节,而 64 位操作可以访问整个寄存器。
操作数指示符
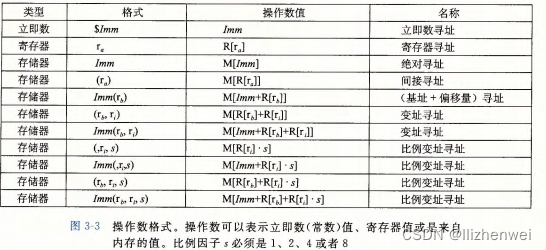
大多数指令有一个或多个操作数 , 指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。各种不同的操作数的可能性被分为三种类型,第一种类型是立即数 , 用来表示常数值,第二种类型是寄存器 (register) , 它表示某个寄存器的内容, 16 个寄存器的低位 1字节、 2字节、 4字节或8字节中的一个作为操作数,这些字节数分别对应于8位、 16 位、 32 位或 64 位。第三类操作数是内存引用,它会根据计算出来的地址(通常称为有效地址)访问某个内存位置。
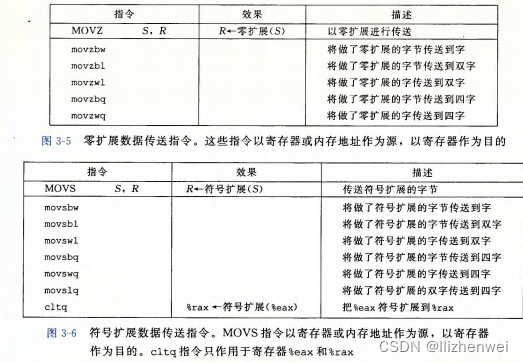
数据传送指令
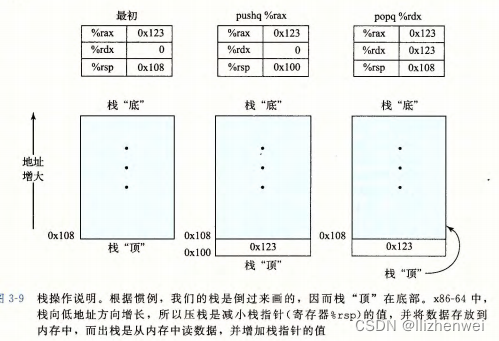
压入和弹出栈数据
栈是一种数据结构,可以添加或者删除值,不过要遵循”后进先出"的原则。通过 push 操作把数据压入栈中,通过 pop 操作删除数据,栈可以实现为一个数组,总是从数组的一端插入和删除元素。这一端被称为栈顶。

算术和逻辑操作
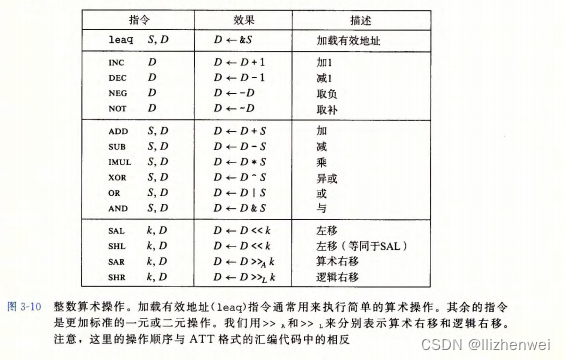
事实上,给出的每个指令类都有对这四种不同大小数据的指令。这些 操作被分为四组:加载有效地址、一元操作、二元操作和移位。二元操作有两个操作数,而一元操作有一个操作数。
加载有效地址
加载有效地址 Ooad effective address) 指令 leaq 实际上是 movq 指令的变形。它的指令形式是从内存读数据到寄存器,但实际上它根本就没有引用内存。它的第一个操作数看上去是一个内存引用,但该指令并不是从指定的位置读入数据,而是将有效地址写人到目的操作数。
一元和二元操作
一元操作,只有一个操作数,既是源又是目的。这个操作数可以是一个寄存器,也可以是一个内存位置。二元操作,第一个操作数可以是立即数、寄存器或是内存位置。第二个操作数可以是寄存器或是内存位置。注意,当第二个操作数为内存地址时,处理器必须从内存读出值,执行操作,再把结果写回内存。
移位操作
最后一组是移位操作,先给出移位量,然后第二项给出的是要移位的数。可以进行算术和逻辑右移。移位量可以是一个立即数,或者放在单字节寄存器% cl 中。
特殊的算术操作

控制
机器代码提供两种基本的低级机制来实现有条件的行为:测试数据值,然后根据测试的结果来改变控制流或者数据流。
条件码
除了整数寄存器, CPU 还维护着一组单个位的条件码 寄存器,它们描述了最近的算术或逻辑操作的属性。可以检测这些寄存器来执行条件分支指令。

访问条件码
条件码通常不会直接读取,常用的使用方法有三种:1) 可以根据条件码的某种组合,将一个字节设置为0或者 1, 2) 可以条件跳转到程序的某个其他的部分, 3) 可以有条件地传送数据。
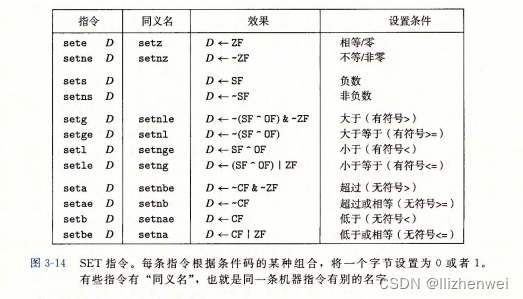
大多数情况下,机器代码对 于有符号和无符号两种情况都使用一样的指令,这是因为许多算术运算对无符号和补码算术都有一样的位级行为。有些情况需要用不同的指令来处理有符号和无符号操作,例如,使用不同版本的右移、除法和乘法指令,以及不同的条件码组合。
跳转指令
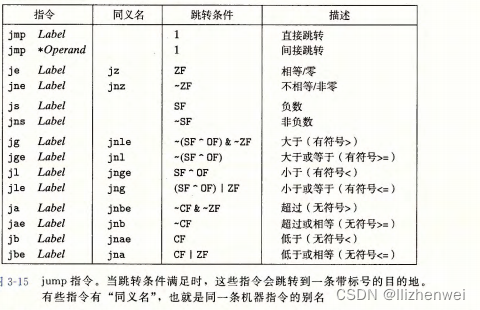
跳转 (jump) 指令会导致执行切换到程序中一个全新的位置。在汇编代码中,这些跳转的目的地通常用一个标号指明。
用条件控制来实现条件分支
将条件表达式和语句从 语言翻译成机器代码,最常用的方式是结合有条件和无条件跳转。

用条件传送来实现条件分支
实现条件操作的传统方法是通过使用控制的条件转移 。当条件满足时,程序沿着一条执行路径执行,而当条件不满足时 ,就走另一 条路径。这种机制 简单而通用,但是在现代处理器上,它可能会非常低效条件数据传送提供了一种用条件控制转移来实现条件操作的替代策略。它们只能用于非常受限制的情况,但是这些情况还是相当常见的,而且与现代处理器的运行方式更契合。
循环
汇编中用条件测试和跳转组合起来实现循环的效果。
switch 语句
跳转表是一个数组,表项 是一个代码段的地址,这个代码段实现当开关索引值等千 时程序应该采取的动作。程序代码用开关索引值来执行一个跳转表内的数组引用,确定跳转指令的目标。和使用一组很长的江-else 语句相比,使用跳转表的优点是执行开关语句的时间与开关情况的数量无关。
过程
过程是软件中一种很重要的抽象。它提供了一种封装代码的方式,用一组指定的参数和一个可
选的返回值实现了某种功能。然后,可以在程序中不同的地方调用这个函数。过程的形式多样:函数(function) 、方(method) 、子例程(subroutine) 、处理函数(handler) 等等
运行时栈
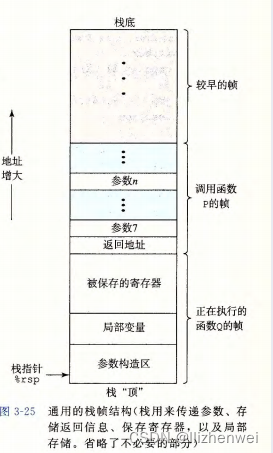
当x86-64 过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个部分称为过程的栈帧 (stack fram) 。
转移控制
将控制从函数P转移到函数Q,只需要简单地把程序计数器 (PC) 设置为Q的代码的起始位置

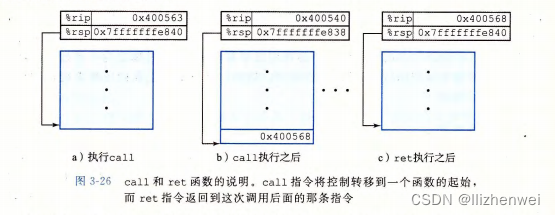
这种把返回地址压入栈的简单的机制能够让函数在稍后返回到程序中正确的点,C语言(以及大多数程序语言)标准的调用/返回机制刚好 与栈提供的后 进先出的内存管理方法吻合。
数据传送
x86-64 中,大部分过程间的数据传送是通过寄存器实现的。
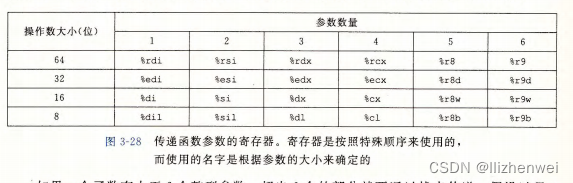
如果一个函数有大于6个整型参数,超出6个的部分就要通过栈来传递 。
栈上的局部存储
以下情况,局部数据必须放在内存中
• 寄存器不足够存放所有的本地数据。
• 对一个局部变量使用地址运算符'&',因此必须能够为它产生一个地址。
• 某些局部变量是数组或结构,因此必须能够通过数组或结构引用被访问到 。
寄存器中的局部存储空间
根据惯例,寄存器 %rbx %rbp %r12~%r15 被划分为被调用者保存寄存器,当过程P
调用过程Q时, Q必须保存这些寄存器的值,保证它们的值在Q返回到P时与Q被调用时
是一样的。所有其他的寄存器,除了栈指针 %rsp, 都分类为调用者保存寄存器。
递归过程
每个过程调用在栈中都有它自己的私有空间,因此多个未完成调用的局部变量不会相互影响此外,栈的原则很自然地就提供了适当的策略,当过程被调用时分配局部存储,当返回时释放存储。
数组分配和访问
基本原则
对于数据类型 和整型常数 N, 声明如下:
T A[N];
起始位置表示为XA这个声明有两个效果。首先,它在内存中分配 L• N字节的连续区域,这里L是数据类型T的大小(单位为字节)。其次,它引入了标识符 A, 可以用作为指向数组开头的指针,这个指针的值就是XA。可以用 0~N-1 的整数索引来访问该数组元素。数组元素i会被存放在地址为 XA +L•i 的地方。
指针运算
C语言允许对指针进行运算,而计算出来的值会根据该指针引用的数据类型的大小进行伸缩。
嵌套的数组
当我们创建数组的数组时,数组分配和引用的一般 则也是成立的。
定长数组
C语言编译器能够优化定长多维数组上的操作代码
变长数组
历史上, 语言只支持大小在编译时就能确定的多维数组(对第一维可能有些例外)。程序员需要变长数组时不得不用 malloc calloc 这样的函数为这些数组分配存储空间,而且不得不显式地编码,用行优先索引将多维数组映射到一维数组.
异质的数据结构
C语言提供了两种将不同类型的对象组合到一起创建数据类型的机制:结构 , 用关键字struct 来声明,将多个对象集合到一个单位中;联合, 用关键union 来声明,允许用几种不同的类型来引用一个对象。
结构
C语言的 struct 声明创建 个数据类型,将可能不同类型的对象聚合到一个对象中。用名字来引用结构的各个组成部分。结构的所有组成部分都存放在内存中一段连续的区域内,而指向结构的指针就是结构第 个字节的地址。
联合
在一些 下上 文中,联合十分有用。但是, 它也能引起一些讨厌的错误 ,因为它们 绕过C语言类型系统提供的安全措施 。一 种应用情况是,我们 先知道对一个数据结构中的两个不同字段的使用是互斥的,那么将这两个字段声明为联 合的 部分 ,而不是结构的一部分,会减小分配空间的总量
数据对齐
许多计算机系统对基本数据类型的合法地址做出了 些限制,要求某种类型对象的地址必须是某个值 K( 通常是 8) 的倍数 这种对齐限制简化了形成处理器和内存系统之间接口的硬件设计。
在机器级程序中将控制与数据结合起来
理解指针
每个指针都对应一个类型。这个类型表明该指针指向的是哪一类对象。
每个指针都有一个值。这个值是某个指定类型的对象的地址。特殊的 NULL(0) 值表示该指针没有指向任何地方。
指针用"δ运算符创建。
*操作符用于间接引用指针。
数组与指针紧密联系。
将指针从一种类型强制转换成另一种类型,只改变它的类型,而不改变它的值。
指针也可以指向函数。
内存越界引用和缓冲区溢出
C对于数组引用不进行任何边界检查,而且局部变量和状态信息都存在栈中,这两种情况结合到一起就能导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。当程序使用这个被破坏的状态,试图重新加载寄存器或执行 ret 指令时,就会出现很严 的错误。
缓冲区溢出:通常,在栈中分配某个字符数组来保存 个字符串,但是字符串的长度超出了为数组分配的间。
对抗缓冲区溢出攻击
栈随机化
栈破坏检测
限制可执行代码区域
支持变长栈帧
浮点代码
处理器的浮点体系结构包括多个方面,会影响对浮点数据操作的程序如何被映射到机器上,包括:
• 如何存储和访问浮点数值 通常是通过某种寄存器方式来完成。
• 对浮点数据操作的指令
• 向函数传递浮点数参数和从函数返回浮点数结果的规则。
• 函数调用过程中保存寄存器的规则 例如,一些寄存器被指定为调用者保存,而其他的被指定为被调用者保存
浮点传送和转换操作
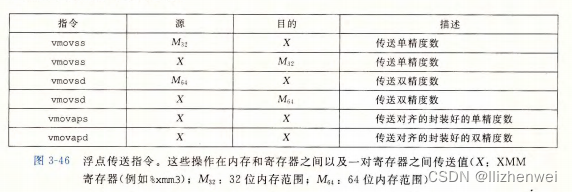
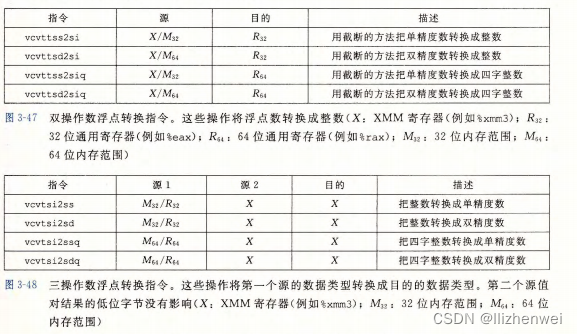
过程中的浮点代码
XMM 寄存器 %xmm0~ %xmm7 最多可以传递 个浮点参数。按照参数列 出的顺序使用
这些寄存器。可以通过栈传递额外的浮点参数
函数使用寄存器 %xmm0 来返回浮点值。
所有的 XMM 寄存器都是调用者保存的。被调用者可以不用保存就覆盖这些寄存器中任意一个。
浮点运算操作
















 1920
1920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









