







OpenAI的o1模型是经过强化学习训练的。这种训练方式使得o1模型在面对需要多层次推理的任务时,能够展现出与人类专家相当的表现。通过强化学习,o1模型学会了如何完善自己的思维过程,尝试不同策略,并认识到自己的错误,从而不断提升其推理能力。今天我们一起探讨强化学习的基本原理、算法、应用实例以及面临的挑战,希望对大家有所帮助。
强化学习(Reinforcement Learning,RL)作为人工智能领域中备受瞩目的分支,其灵感源自于动物在与环境交互中通过不断试错来学习最优行为的过程。就像幼儿学步,每一步的尝试与调整都是在积累经验,以实现稳定行走的目标。强化学习的核心在于让智能体(agent)(Multi-Agent架构:探索AI协作的新纪元)在环境中通过不断尝试不同的行动,根据所获得的奖励反馈来学习最优决策策略,以最大化长期累积奖励。这一独特的学习方式使其在众多领域展现出巨大的潜力,从复杂的棋类游戏到现实世界中的电力系统运营等。
一、强化学习的基本原理
(一)核心概念
-
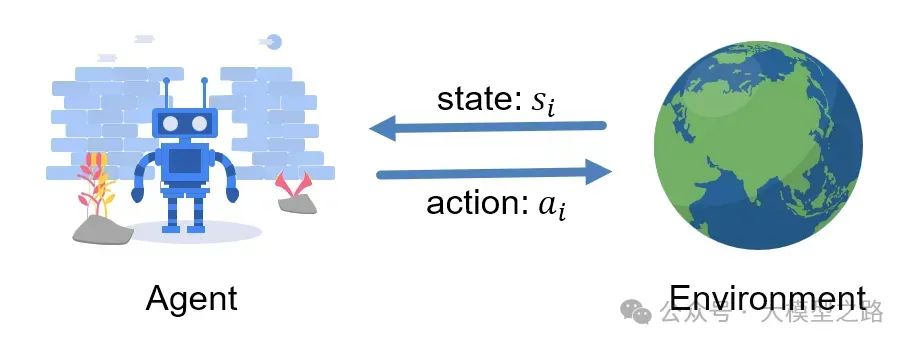
智能体(Agent):强化学习中的决策主体,负责在环境中采取行动。例如,在自动驾驶汽车中,智能体就是控制汽车行驶决策的系统。
-
环境(Environment):智能体所处的外部系统,智能体的行动会改变环境状态并获得相应奖励。以机器人在迷宫中导航为例,迷宫就是机器人的环境。
-
状态(State):环境在某一时刻的特定情况,是智能体决策的依据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











