







检索增强生成(Retrieval-Augmented Generation,简称RAG)(RAG综述:探索检索增强生成技术的多样性与代码实践)技术已经成为构建高性能AI模型的重要基石。RAG通过结合先进的语言模型与外部知识检索,能够生成既准确又富含上下文的响应。然而,尽管RAG功能强大,但它也伴随着一系列挑战,如高令牌消耗(token consumption)、运营成本的增加以及响应时间的延长。这些问题限制了RAG模型的有效性,因此,解决这些问题对于释放RAG系统的真正潜力并实现顶级性能至关重要。今天我们聊一下如何通过语义缓存这一策略来提升RAG模型的性能。
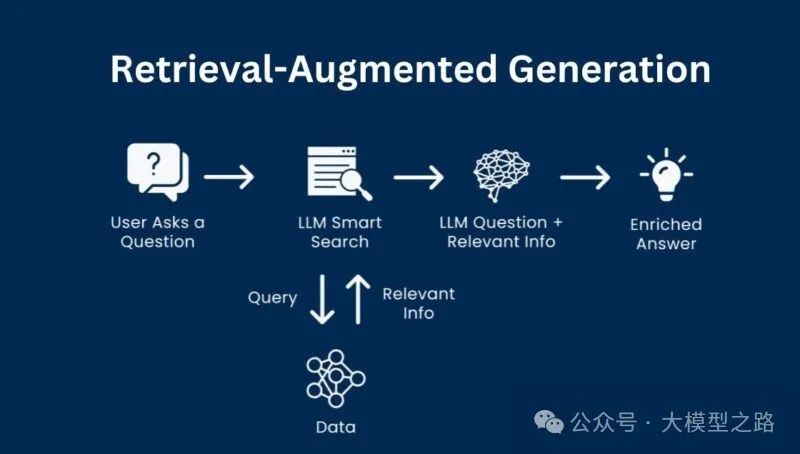
一、RAG模型简介
RAG是一种AI技术,它结合了从外部源检索相关信息与语言模型来处理这些信息以生成准确、上下文感知的响应。构建一个基于RAG(微软最新研究:RAG(Retrieval-Augmented Generation)的四个级别深度解析)的AI系统通常涉及以下步骤:
- 数据收集与存储
:首先,需要收集与特定主题或领域相关的数据,并将其存储在向量数据库中。在向量数据库中,信息以向量的形式存储,以便高效检索。
- 语言模型选择
:选择一个强大的语言模型,如GPT-4或Llama 3,来处理这些向量数据并生成响应。
- 系统集成
:使用工具如LangChain、LlamaIndex或LLMWare来无缝协调这些组件,确保系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











