










softmax 回归模型,是logistic 回归模型在多分类问题上的推广。关于logistic回归算法的介绍,前面博客已经讲得很清楚,详情可以参考博客
机器学习实战ByMatlab(五)Logistic Regression
在logistic回归模型中,我们的激励函数sigmoid的输入为:
则可以得到假设函数为:
其中 g 为 sigmoid 函数。
因此,我们得到判断,当
z
的值大于0,
此时得到的代价函数为:
只要最小化代价函数
J
就能够得到最优的模型参数
对于二分类来说,我们只需要一组模型参数 θ 就可以对数据进行分类。
在多分类问题中,我们的 y(i) 值就不在只是0或者1,它可以是2,3,4等等,此时我们就得为每个模型都分配一组模型参数 θ1,θ2,...,θn ,假设现在依旧是2个分类,我们对假设函数改造一下:
其中,
θ1
代表分类1的模型参数,
θ2
代表分类2的模型参数, 那么此时我们的假设函数
h
得到的是
这就是softmax回归的最简单模式。
K个模型的softmax回归算法
对于输入训练集
此时的代价函数为:
代价函数的导数为:
该到一般用于我们对参数进行迭代求解。
自我学习
我们平常进行算法训练所需要的标注数据比较少,而未标注数据比价多。自学习算法就是一种能从大量的为标注数据中学习得到数据的特征,并与以标注数据结合进行算法训练,从而得到更加准确的分类效果。
在一些拥有大量未标注数据和少量的已标注数据的场景中,上述思想可能是最有效的。即使在只有已标注数据的情况下(这时我们通常忽略训练数据的类标号进行特征学习),以上想法也能得到很好的结果。
自我学习步骤
1.利用无标签数据进行非监督特征学习,训练稀疏编码器,得到参数
W
和
2.将有标签数据通过学习到的稀疏编码器,得到更加能够代表数据的激活量
a
3.用激活量替代
4.测试数据
xtest
经过稀疏编码器得到激活值
atest
,并将
atest
或者
(atest,xtest)
送到分类器中进行预测
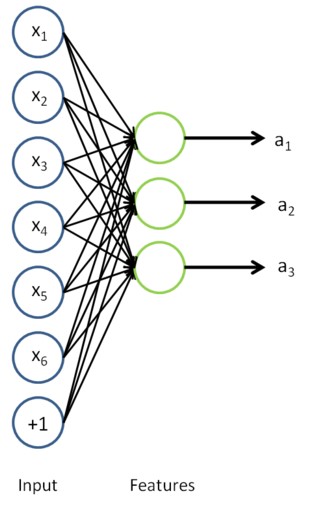
如下:输入数据为6维,运用自编码算法学习到3维特征,也就是激活值,再下面的网络后面再加上softmax回归模型,便组成了基于自学习网络的softmax回归。
手写数字识别
前面的博客
DeepLearning(二) 自编码算法与稀疏性理解与实战
中已经介绍了如何实现自编码算法从未标注数据中学习数据的内在特征。假如,我们现在有一个无标注的训练数据集,这里使用的是手写识别库 MNIST ,我们使用的5-9作为无标注的数据进行特征学习,训练我们的自动编码器,得到网络的模型参数 W(1),b(1),W(2),b(2) , 这部分属于无监督学习,目的就是学习得到网络模型参数,从而得到自编码学习网络。
上面说到,我们已经用无标签数据训练得到一个可以使用的自编码学习网络,接着我们将从有便签数据 0-4 (其中0作为10)中选取一部分作为softmax模型的训练数据,另外的部分作为模型测试数据。
这里我们选取一般的有标签数据作为训练数据,首先将训练数据输入到上面学习到的自编码算法网络进行前向传输,得到输入数据的特征,也就是我们自编码学习网络隐藏层的激活值
a
,然后我们将学习得到的特征替换原来的输入数据,即
测试模型时,同样将测试数据输入到自编码算法网络进行前向传输得到激活值,然后再将激活值输入到softmax回归模型,判断模型输输出值与标签值的差异即可判断模型误差。
Matlab 代码
自编码网络学习
首先,我们先要训练自编码网络,详细训练代码可以参考博客
DeepLearning(二) 自编码算法与稀疏性理解与实战
中的 sparseAutoencoderCost.m 这里调用这个代码进行训练,优化方法使用 lbfgs 算法。如下:
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 400;
options.display = 'on';
visibleSize = inputSize;
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
visibleSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, unlabeledData), ...
theta, options);前向传输
自编码网络学习完成之后,我们先进行前向传输,获得训练数据以及测试数据的学习特征:
trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
trainData);
testFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
testData);前向传输 feedForwardAutoencoder 的核心代码如下:
activation = sigmoid(bsxfun(@plus,W1 * data,b1)) ;这里的隐藏层神经元个数为200个。
softmax 回归模型训练
softmaxModel = struct;
options.maxIter = 100;
lambda = 1e-4;
numClasses = 5;
inputData = trainFeatures;
labels = trainLabels ;
inputSize = hiddenSize;
softmaxModel = softmaxTrain(inputSize, numClasses, lambda, inputData, labels, options);softmax 回归模型训练函数 softmaxTrain.m 需要实现 softmax 回归的代价函数 softmaxCost.m ,其核心代码如下:
M = theta * data;
M = exp(bsxfun(@minus,M,max(M,[],1)));
H = bsxfun(@rdivide,M,sum(M));
cost = - sum(sum((groundTruth .* log(H)))) / size(data,2) + lambda * sum(sum(theta.^2)) / 2 ;
thetagrad = - ((groundTruth - H)) * data' /size(data,2) +lambda * theta;这里解释下这段代码:
M = exp(bsxfun(@minus,M,max(M,[],1)));softmax 回归模型中的假设函数为:
其中,我们将输入数据
x
与模型参数
也就是说
eθT2x(i)−a
,其中
a
为常数,并不会由什么影响,所以将每一列的
模型测试
模型训练完之后,我们运用有标签数据进行测试,代码如下:
[Val , pred] = max(theta*data);如果单纯使用输入数据训练softmax回归模型,模型需要训练100次,而且最终的测试准确度为 : 93.27%。
如果先使用无标签数据训练自编码网络,再进行softmax回归模型训练,softmax回归算法只需迭代 54 次就收敛,而且测试准确度为 98.33%,因此可见我们的自编码网络学习到的特征比原来的输入数据更具代表性,这也就是传统训练方法与深度学习训练方法的差异。

训练过程的代码如下:
clc
clear
inputSize = 28 * 28;
numLabels = 5;
hiddenSize = 200;
sparsityParam = 0.1; % desired average activation of the hidden units.
% (This was denoted by the Greek alphabet rho, which looks like a lower-case "p",
% in the lecture notes).
lambda = 3e-3; % weight decay parameter
beta = 3; % weight of sparsity penalty term
maxIter = 400;
% Load MNIST database files
mnistData = loadMNISTImages('train-images.idx3-ubyte');
mnistLabels = loadMNISTLabels('train-labels.idx1-ubyte');
% Set Unlabeled Set (All Images)
% Simulate a Labeled and Unlabeled set
labeledSet = find(mnistLabels >= 0 & mnistLabels <= 4);
unlabeledSet = find(mnistLabels >= 5);
numTrain = round(numel(labeledSet)/2);
trainSet = labeledSet(1:numTrain);
testSet = labeledSet(numTrain+1:end);
unlabeledData = mnistData(:, unlabeledSet);
trainData = mnistData(:, trainSet);
trainLabels = mnistLabels(trainSet)' + 1; % Shift Labels to the Range 1-5
testData = mnistData(:, testSet);
testLabels = mnistLabels(testSet)' + 1; % Shift Labels to the Range 1-5
% Output Some Statistics
fprintf('# examples in unlabeled set: %d\n', size(unlabeledData, 2));
fprintf('# examples in supervised training set: %d\n\n', size(trainData, 2));
fprintf('# examples in supervised testing set: %d\n\n', size(testData, 2));
% Randomly initialize the parameters
theta = initializeParameters(hiddenSize, inputSize);
addpath minFunc/
options.Method = 'lbfgs';
options.maxIter = 400;
options.display = 'on';
visibleSize = inputSize;
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
visibleSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, unlabeledData), ...
theta, options);
% Visualize weights
W1 = reshape(opttheta(1:hiddenSize * inputSize), hiddenSize, inputSize);
display_network(W1');
trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
trainData);
testFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ...
testData);
%% STEP 4: Train the softmax classifier
softmaxModel = struct;
options.maxIter = 100;
lambda = 1e-4;
numClasses = 5;
inputData = trainFeatures;
labels = trainLabels ;
inputSize = hiddenSize;
softmaxModel = softmaxTrain(inputSize, numClasses, lambda, inputData, labels, options);
%%======================================================================
%% STEP 5: Testing
[pred] = softmaxPredict(softmaxModel, testFeatures);
% Classification Score
fprintf('Test Accuracy: %f%%\n', 100*mean(pred(:) == testLabels(:)));















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









