









问题描述
实现类似Photoshop的基于透明元素裁切图片
1.png

2.jpg

3.png

4.png

5.png

6.png

解决方案
遍历图像数组找出裁切图片的左上角、右下角坐标
import cv2
from PIL import Image
def cv2_crop(im, box):
'''cv2实现类似PIL的裁剪
:param im: cv2加载好的图像
:param box: 裁剪的矩形,(left, upper, right, lower)元组
'''
return im.copy()[box[1]:box[3], box[0]:box[2], :]
def get_transparency_location(image):
'''获取基于透明元素裁切图片的左上角、右下角坐标
:param image: cv2加载好的图像
:return: (left, upper, right, lower)元组
'''
# 1. 扫描获得最左边透明点和最右边透明点坐标
height, width, channel = image.shape # 高、宽、通道数
assert channel == 4 # 无透明通道报错
first_location = None # 最先遇到的透明点
last_location = None # 最后遇到的透明点
first_transparency = [] # 从左往右最先遇到的透明点,元素个数小于等于图像高度
last_transparency = [] # 从左往右最后遇到的透明点,元素个数小于等于图像高度
for y, rows in enumerate(image):
for x, BGRA in enumerate(rows):
alpha = BGRA[3]
if alpha != 0:
if not first_location or first_location[1] != y: # 透明点未赋值或为同一列
first_location = (x, y) # 更新最先遇到的透明点
first_transparency.append(first_location)
last_location = (x, y) # 更新最后遇到的透明点
if last_location:
last_transparency.append(last_location)
# 2. 矩形四个边的中点
top = first_transparency[0]
bottom = first_transparency[-1]
left = None
right = None
for first, last in zip(first_transparency, last_transparency):
if not left:
left = first
if not right:
right = last
if first[0] < left[0]:
left = first
if last[0] > right[0]:
right = last
# 3. 左上角、右下角
upper_left = (left[0], top[1]) # 左上角
bottom_right = (right[0], bottom[1]) # 右下角
return upper_left[0], upper_left[1], bottom_right[0], bottom_right[1]
if __name__ == '__main__':
image = cv2.imread('1.png', cv2.IMREAD_UNCHANGED) # 读取图片
# image = cv2.imread('2.jpg')
# image = cv2.imread('3.png', cv2.IMREAD_UNCHANGED)
# image = cv2.imread('4.png', cv2.IMREAD_UNCHANGED)
# image = cv2.imread('5.png', cv2.IMREAD_UNCHANGED)
# image = cv2.imread('6.png', cv2.IMREAD_UNCHANGED)
cv2.imshow('1', image)
# 保存裁剪后图片
box = get_transparency_location(image)
result = cv2_crop(image, box)
cv2.imshow('result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('result.png', image)
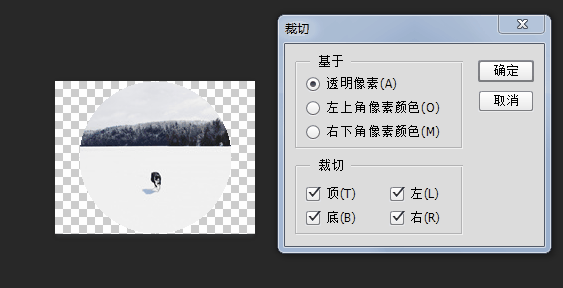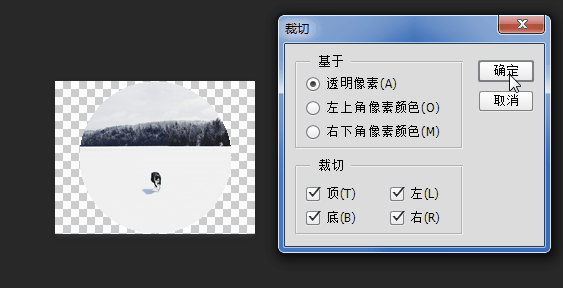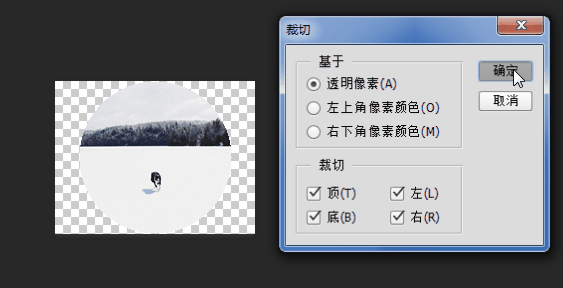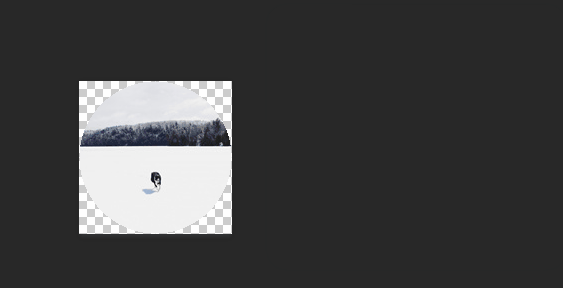
效果



















 8099
8099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











