






YOLOv7于2022年发布的,由YOLOv4团队的原班人马提出,在YOLOv5的基础上改进了网络结构,使网络更加高效。
 论文链接:https://arxiv.org/abs/2207.02696
论文链接:https://arxiv.org/abs/2207.02696
代码链接:https://github.com/WongKinYiu/yolov7
论文做出的贡献如下:
1. 设计几种可训练的bag-of-freebies,使实时检测器可以在不提高推理成本的情况下大大提高检测精度;
2. 提出动态的模型结构重参化高效替代原始模块;以及coarse-to-fine引导标签分配策略处理好不同输出层的分配。
3. 为实时检测器提出了“扩展”(extend)和“复合缩放”(compound scaling)方法,可以更加高效地利用参数和计算量,同时,可以有效地减少实时检测器50%的参数,并且具备更快的推理速度和更高的检测精度。
一. 模型设计架构
1.1 高效的聚合网络
在大多数关于设计高效网络的论文中,主要考虑的因素是参数量、计算量和计算密度。但从内存访存的角度出发出发,还可以分析输入/输出通道比、架构的分支数和元素级操作对网络推理速度的影响(shufflenet论文提出)。在执行模型缩放时还需考虑激活函数,即更多地考虑卷积层输出张量中的元素数量。
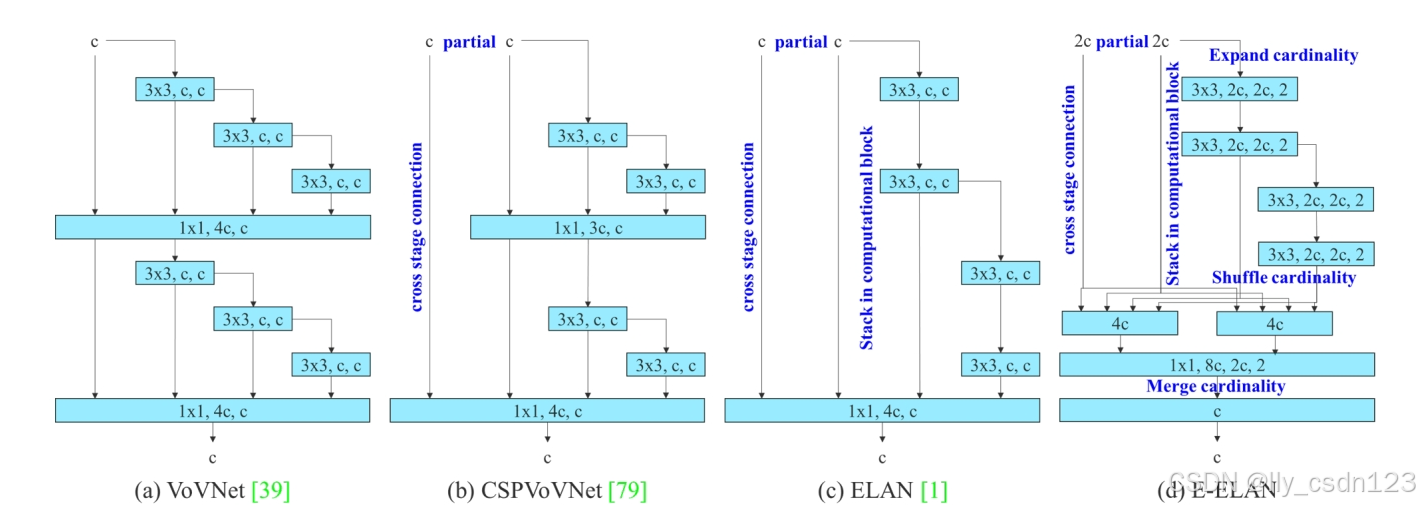
图(b)CSPVoVNet是VoVNet的1种变体,不仅从模型的参数量、计算量、内存访问次数、输入输出的通道比、element-wise操作等方面分析参数的数量、计算量和计算密度,还分析梯度在模型中的流动路径,使得不同层得权重可以学习更加多样化的特征,可显著提升推理的速度与精度。
图(c)中的ELAN出于以下设计考虑——“如何设计一个高效的网络?”得出结论是:通过控制最短最长梯度路径,更深的网络可以有效地进行学习并更好地收敛。
在文章中,作者提出了基于ELAN的扩展版本E-ELAN,其主要架构如图(d)所示。使用expand、 shuffle、 merge cardinality来实现在不破坏原有梯度路径的情况下,提升网络的学习能力。
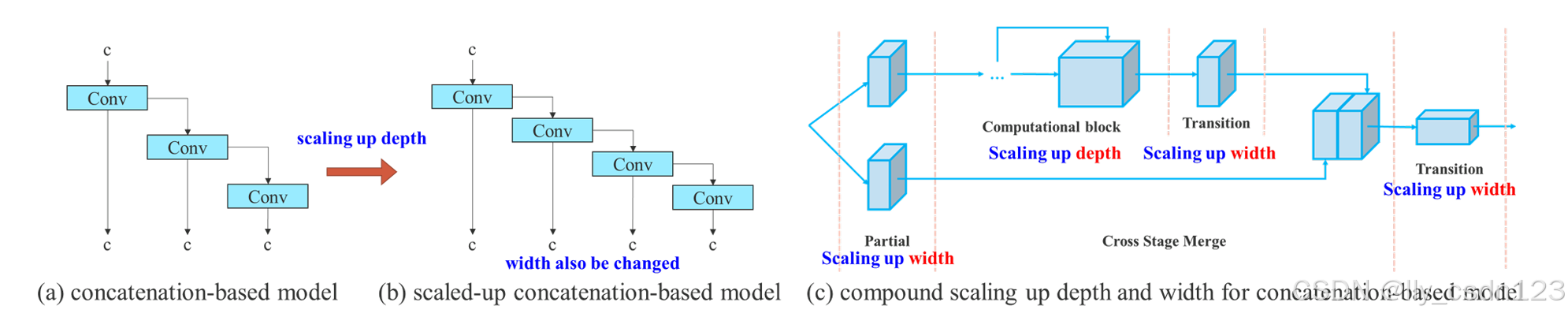
1.2 基于concatenate的模型缩放
模型缩放是调整模型的大小来生成不同尺度的模型,主要的缩放因子有input size 、depth、width、stage。基于concatenate的模型缩放在缩放1个计算块的深度因子时,必须结合计算块的输出通道的变化进行计算,在过渡层用相同的变化量进行宽度因子缩放。
二. 可训练的bag-of-freebies
2.1 卷积重参化
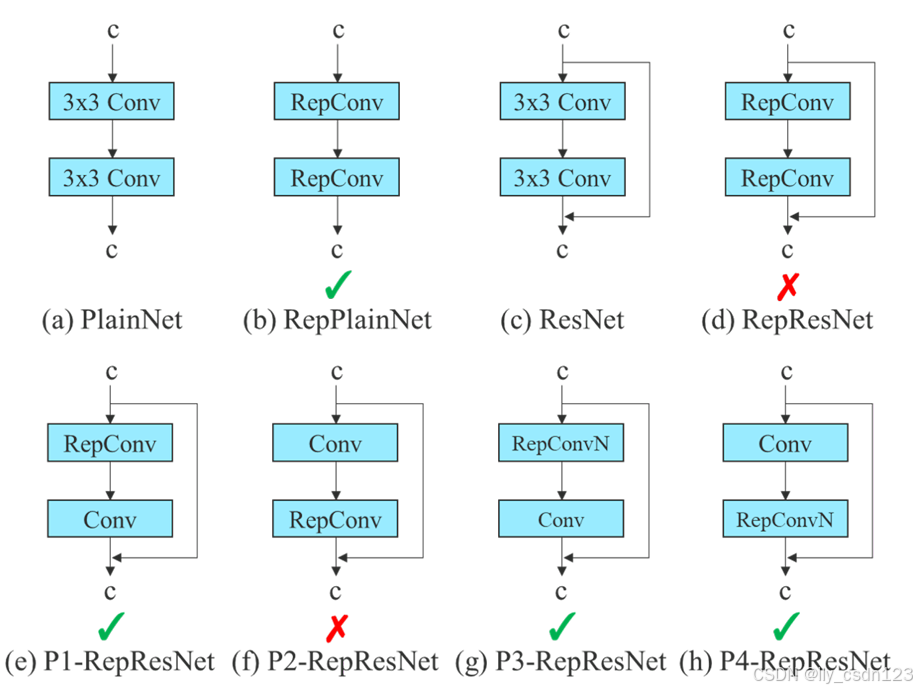
RepConv中的identity破坏了ResNet中的残差结构和DenseNet中的跨层连接,这为不同的特征图提供了梯度的多样性。因此,使用没有identity连接的RepConv结构。下图显示了作者在PlainNet和ResNet中使用的“计划型重参化卷积”的一个示例。
2.2 辅助训练模块
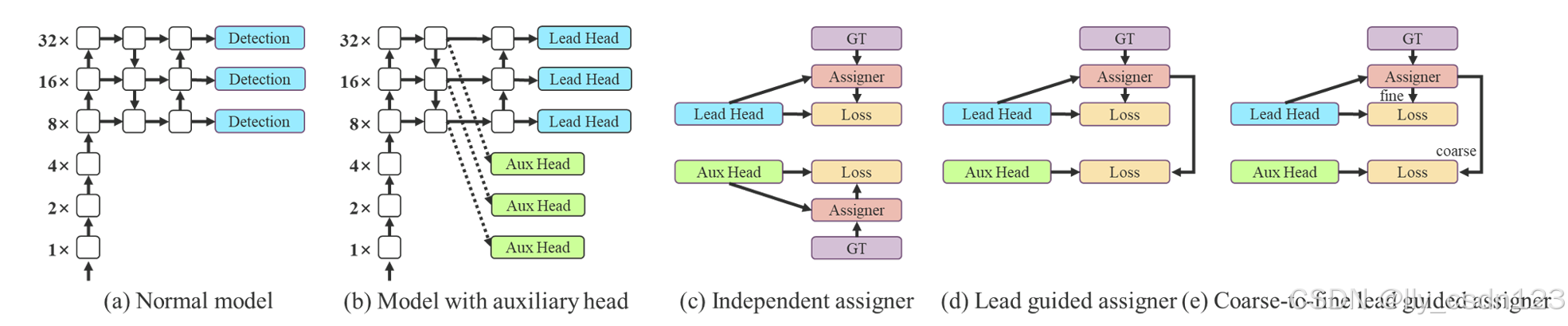
下图(a)和(b)分别显示了“没有”和“有”深度监督的目标检测器架构,在文章中,作者将负责最终的输出头称为引导头,将用于辅助训练的头称为辅助头。
接下来讨论标签分配的问题。在过去,在深度网络的训练中,标签分配通常直接指的是ground truth,并根据给定的规则生成hard label(未经过softmax)。
在文章中,作者将网络预测结果与ground truth一起考虑后再分配软标签的机制称为“标签分配器”。无论辅助头或引导头,都需要对目标进行深度监督。目前最常用的方法如上图(c)所示,即将辅助头和引导头分离,然后利用它们各自的预测结果和ground truth执行标签分配。
文章中提出的方法是一种新的标签分配方法,通过引导头的预测来引导辅助头以及自身。换句话说,首先使用引导头的prediction作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习,具体可看上图(d)和(e)。
Lead head guided label assigner
引导头引导“标签分配器”预测结果和ground truth进行计算,并通过优化生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型。
Coarse-to-fine lead head guided label assigner
Coarse-to-fine引导头使用到了自身的prediction和ground truth来生成软标签,引导标签进行分配。然而,在这个过程中,作者生成了2组不同的软标签,即粗标签和细标签,其中细标签与引导头在标签分配器上生成的软标签相同,粗标签是通过降低正样本分配的约束,允许更多的网格作为正目标。原因是一个辅助头的学习能力并不需要强大的引导头,为了避免丢失信息,作者将专注于优化样本召回的辅助头。对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。
2.3 其他可训练的bag-of-freebies
(1)Batch normalization:目的是在推理阶段将批归一化的均值和方差整合到卷积层的偏差和权重中。
(2)YOLOR中的隐式知识结合卷积特征映射和乘法方式:YOLOR中的隐式知识可以在推理阶段将计算值简化为向量。这个向量可以与前一层或后一层卷积层的偏差和权重相结合。
(3)EMA Model:EMA 是一种在mean teacher中使用的技术,作者使用 EMA 模型作为最终的推理模型。

















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









