






香港中大-商汤科技联合实验室在2018 AAAI 会议上发表论文“Spatial Temporal Graph Convolutional Networks for Skeleton Based Action Recognition”,提出时空图卷积网络模型ST-GCN,用于解决基于人体骨架关键点的人类动作识别问题。

论文链接:https://arxiv.org/abs/1801.07455
代码链接:https://github.com/yysijie/st-gcn
一.介绍
近年来,人类动作识别已成为活跃的研究领域,因为它在视频理解中起着重要作用。一般而言,人类行为可以从多种形式中识别,例如外观、深度、 光流和人体骨架。在这些方式中,动态的人体骨架通常传达重要的信息,这些信息是其他信息的补充。但是,与外观和光流相比,动态骨架的建模受到的关注相对较少。
动态骨架模态可以由人类关节位置的时间序列,以2D或3D坐标的形式自然地表示,然后可以通过分析其动作模式来识别其动作。大多数现有方法都依靠手工制作的身体部位或规则来分析空间模式。结果,为特定应用设计的模型很难推广到其他应用。
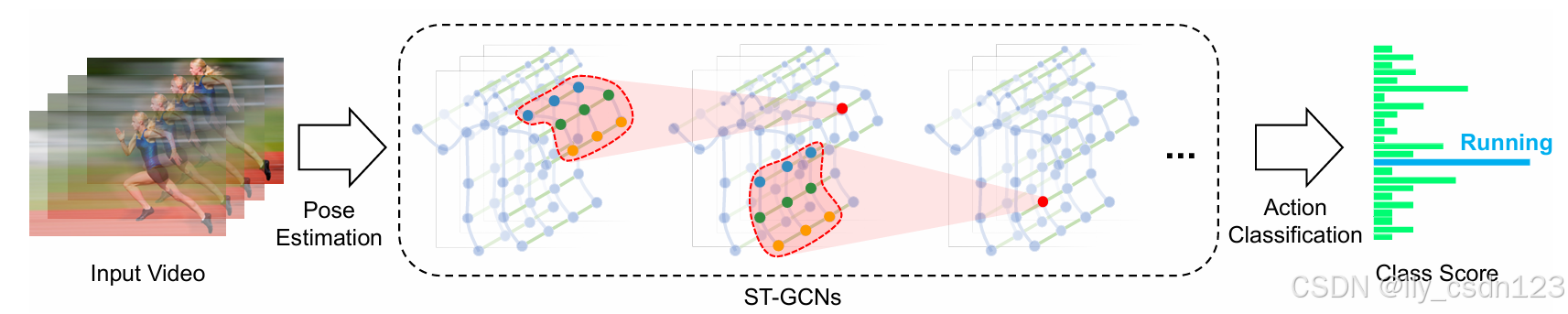
港中文团队提出通过将图神经网络扩展到称为时空图卷积网络(ST-GCN)的时空图模型,来设计用于动作识别的骨架序列的通用表示。如下图所示:
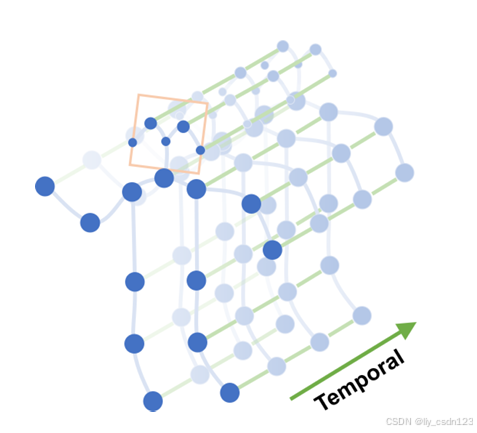
以骨架图序列为基础,其中每个节点对应于人体的一个关节。边有2种类型。
空间边:与关节的自然连通性相符的边;
时间边:在连续的时间步长上连接相同关节的边。
借助图结构可以构造多层的空间时间图卷积,允许沿空间和时间维度整合信息。
二.相关工作
应用于图的神经网络
构造GCN通常遵循2个方面:1)频谱视角,以频谱分析的形式考虑了图卷积的局部性;2)空间视角,将卷积滤波器直接应用于图的节点及其邻域。本文采用空间视角。通过将滤波器的作用于每个节点的1-neighbor,在空间域上构造CNN过滤器。
基于骨架的动作识别
人体的骨架和关节轨迹对于光照变化和场景变化具有鲁棒性,并且借助高精度的深度传感器或姿势估计算法,骨架和关节轨迹易于获得。因此,存在多种基于骨架的动作识别方法,这些方法可以分为基于手工特征的方法和深度学习方法。
基于手工特征的方法设计一些手工特征来捕获关节运动的动态信息,手工特征可能是关节轨迹的协方差矩阵,关节的相对位置或身体各部位之间的旋转和平移。基于深度学习的方法使用RNN和Temporal CNN,以端到端的方式学习动作识别模型。
三.ST-GCN
3.1 Pipeline
骨架数据可以从运动捕获设备中获取,也可以从视频中通过姿势估计算法获取。通常,数据是帧序列,每个帧有1组关节坐标集合。给定2D或3D坐标形式的人体关节序列,构建一个时空图以关节为图(Graph)节点,以身体部位结构间的自然连通性和时间作为图的边。
ST-GCN的输入是图节点上的关节坐标矢量。输入数据经过多层时空图卷积操作在图上生成更高级别的特征图。然后,通过的SoftMax分类器分类为相应的动作类别。整个模型通过反向传播,以端到端的方式进行训练。
3.2 Skeleton Graph Construction
利用时空图来形成骨架序列的层次表示。具体地,在具有N个关节的T帧的骨架序列上构造无向时空图 G =(V, E),T帧骨架同时具有体内和帧间连接。
在G中,节点集合包括骨架序列中的所有关节。作为ST-GCN的输入,节点上的特征矢量
包括帧t上第i个关节的坐标矢量以及估计置信度。
分2步在骨架序列上构建时空图。首先,根据人体结构的连通性,将1帧内的关节采用边进行连;然后,在连续帧中,每个关节将连接到与其相同的关节。
正式地,边集合 E 由2个子集组成:第1个子集描述每个帧的骨架内连接,表示为 ,其中 H 是自然连接的人体关节的集合;第2个子集包含帧与帧之间的边,这些边将连续的帧中相同的关节连接为
。因此,随着时间的推移,对于每个特定关节i,
中对应的所有边都将代表其轨迹。
3.3 Spatial Graph Convolutional Neural Network
首先,从单帧图像的图卷积网络入手。对处于时刻,包含N个关节点
和骨骼边
的单帧图像,给定输入特征映射
,通道数c,k*k的卷积核,空间位置x处的输出为:
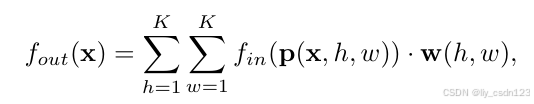
其中,采样函数p:枚举位置x的邻域,在图像卷积的情况下,也可以表示为:
。权重函数
,提供1个c维的权重向量,用于计算与输入的c维特征向量的内积。
将上面公式扩展到作用于空间图上的图卷积操作,即
。首先,重新定义采样函数p和权重函数w。
采样函数
定义节点的邻域集为
,
表示
到
的最小路径长度,采样函数
定义如下:
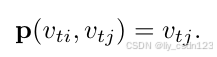
D设置为1。
权重函数
将节点的邻域集
划分为K个子集,每个子集有1个数字标签。映射函数
将邻域集中的节点转换为子集标签。权重函数定义如下:
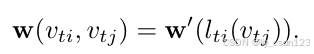
空间图卷积
基于改进的采样函数和权重函数,空间图卷积的公式如下:
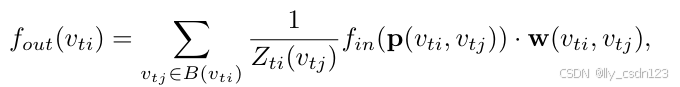
其中,归一化项用于平衡不同子集对输出的贡献。
将采样和权重函数代入上式,得到:
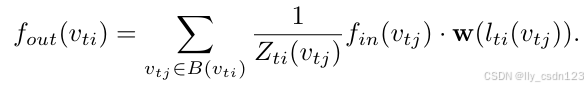
时空建模
在定义空间图卷积后,开始对骨架序列中的时空动态信息进行建模。将邻域的概念扩展到时间连接点:
![]()
其中,参数划定邻域图中的时间范围,也被称为时间核尺寸。
以关节点为根节点的时空邻域
定义如下:
![]()
其中,是单帧图像中
处的标签映射。
3.4 Partition Strategies
考虑分区策略来实现标签映射,先从单帧图像讨论,后面扩展到时空域。
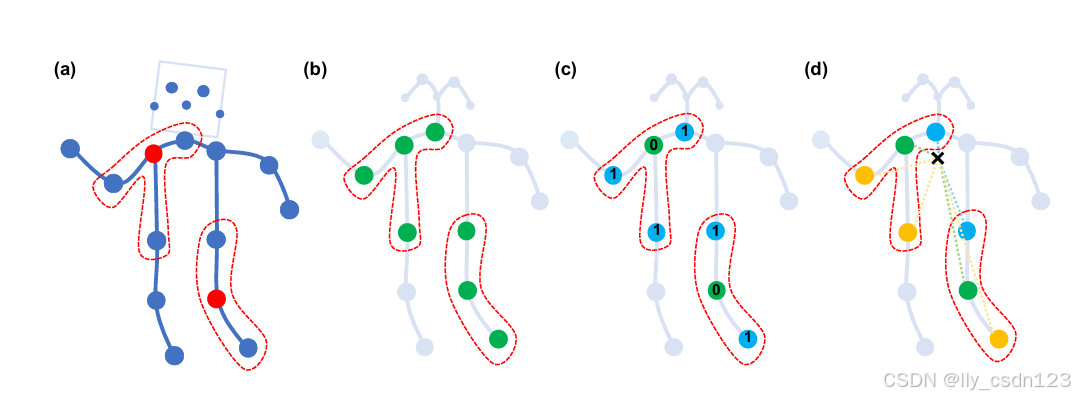
统一标签
最简单和直接地分区策略是子集是整个邻域集本身,即K=1,,会丢失局部微分属性。
距离分区
根据节点到根节点的距离
划分邻域集。在本文中,设置D=1,邻域集被划分为2个子集。其中,d=0为根节点本身,其余节点在d=1的子集中,产生2个不同的权重向量,可以模拟局部微分属性,如关节点之间的相对平移。具体地,K=2,
。
空间配置分区
利用身体骨架的特性,将邻域集划分为3各子集:1)根节点本身; 2)向心集:比根节点更靠近身体重心的节点; 3)其他。分区策略的灵感来自于身体部位的运动大致可以分为向心运动和离心运动。
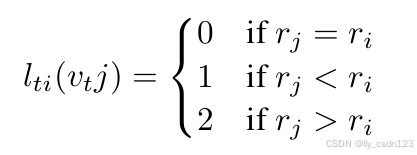
其中,是训练集中所有帧从重心到关节点i的平均距离。
3.5 Learnable edge importance weighting
人在做动作时,关节是成组运动的,1个关节可以出现在身体的多个部位上。因此,在建模身体部位的动态信息是,权重应该有所区分。在时空图卷积的每一层上添加1个可学习的掩码M,掩码根据中每个空间图的边的学习到的重要性权重来衡量节点特征对相邻节点的贡献。
3.6 Implementing ST-GCN
单个帧内关节的体内连接由邻接矩阵A和单位矩阵I表示。在单帧情况下,执行第1个分区策略的ST-GCN表示如下:
![]()
其中,。多个输出通道的权重向量被堆叠形成权重矩阵W。扩展到时空域上,输入特征图为(C,V,T)维度的张量,图卷积是通过执行
的2D卷积和与归一化邻接矩阵
相乘实现的。
对于距离分区和空间配置分区策略,邻接矩阵被分解为若干个矩阵,
。例如,在距离分区策略中,
。上面公式变为:
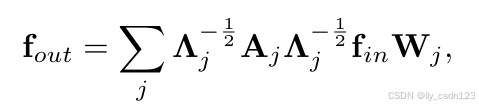
其中,,设置
避免
中出现空行。
对于每个邻接矩阵都伴随着1个可学习的权重矩阵M。
网络架构和训练
首先,将输入骨架提供给batch normalization layer,对数据进行归一化。ST-GCN模型由9层ST-GCN units组成。前3层输出通道为64,中间3层输出通道为128,最后3层输出通道为256。这些层有9个时间核尺寸,每个ST-GCN units都具有resnet机制,且每个ST-GCN units之后以0.5的概率随机丢弃特征避免过拟合。第4个和第7个时间卷积层的步幅为2,然后,对生成的张量进行全局池化,得到256维的特征向量,并送入Softmax分类器。
模型采用SGD策略,学习率=0.01,每10个epoch,学习率下降0.1。为避免过拟合,在Kinetics数据集上训练时,执行2种策略替换Dropout Layer。策略1:为了模拟相机运动,对所有帧的骨架序列进行随机仿射变换;具体地:从第1帧到最后1帧,选择固定的角度、平移和缩放因子作为候选,然后随机选择3个因子的2个组合生成仿射变换,并插值到中间帧。策略2:在训练时,从原始骨架序列中抽取片段,并在测试时使用所有帧。网络顶部的Global pooling是的网络能够处理无限长度的输入序列。
四.实验
4.1 Dataset & Evaluation Metrics
Kinetics
包括从YouTube检索的大约300,000个视频片段,涵盖从日常活动、运动场景到具有交互属性的动作类别总计400个,每个视频切片的持续时间为10s。
Kinetics数据集不提供骨架信息。为了获取骨架信息,首先,将分辨率调整为340*256,帧率为30 FPS。然后,使用OpenPose估计人体18个关节的位置(X,Y)和置信度C。对于多人情况,选择每个切片中具有最高平均关节点置信度的2个人。
NTU-RGB+D
NTU-RGB+D是包含3D关节注释的用于人体动作识别任务的数据集。数据集包括56,000个动作切片,涵盖60个动作类别,由3个摄像机同时记录,具有3D关节位置信息(X,Y,Z),关节点数量为25。
4.2 Ablation Study
在Kinetics数据集上对时空图卷积、分区策略及可学习的边缘重要性权重3个方面进行消融研究,结果如下:
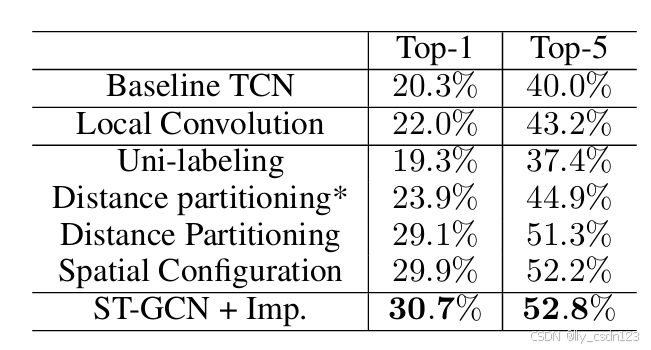
验证时空图卷积、空间配置分区策略及可学习的边缘重要性权重的有效性。
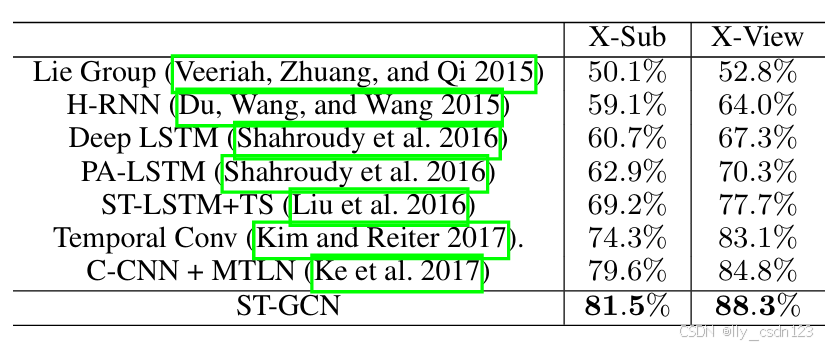
4.3 Comparison with State of the Arts
Kinetics

NTU-RGB+D

















 3309
3309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









