









MobileNet
做图像算法最经常用的模型是restNet系列,但是训练好的模型太大。拿restNet50来说,训练好的模型有280M,参数7千万,运行起来非常慢。
MobileNet是一个基于depthwise separable convolutions的网络结构,优点是模型非常小,训练完模型11M,参数200多万,准确率比restNet下降的幅度很小,更适合于移动端。
depthwise separable convolutions
先看一个普通的CNN网络,这个操作进行了一次卷积并将channel增加一倍:
这个网络输入是2个channel,输出时4个channel,卷积核是3X3,需要的参数是2X3X3X4=72个。

图片来自于李宏毅老师的深度学习教程:https://www.bilibili.com/video/av48285039/?p=89
上面的卷积操作其实做了2件事情,1.进行了一次3X3的卷积,2:将channel扩大为2倍
用depthwise separable convolutions实现一个同样的操作分为两步:
1.只进行卷积,channel不变
2.第二步,使用1X1卷积核,channel翻倍

最终结果和上述方式一样,参数数量为2X3X3+4X2)=26个
和第一种方式的参数相比,得到比例为:
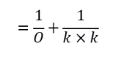
其中O为outchannel,k为kernel size。在实际应用中,O一般很大(例如512,1024),所以最终的参数数量大约等于:
![]()
如一般常用的3*3的卷积核,参数缩小为1/9,4*4的卷积核,则缩小为1/16
原理
为什么会出现这种情况,原因很简单,depthwise separable convolutions利用到了更多的权值共享(这跟CNN之所以如此优秀的原理一样)。第一个网络,共用了8个3*3的卷积核,但是后者只用了2个;若是output channel为256,则需要512个3X3的卷积核,但后者还是2个;这就是秘密所在。















 5629
5629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









