







 本文详细介绍了深度可分离卷积的目的、原理及其与普通卷积的区别。深度可分离卷积通过深度卷积和逐点卷积两步操作显著减少了计算量,并在参数量和FLOPs方面进行了具体对比。
本文详细介绍了深度可分离卷积的目的、原理及其与普通卷积的区别。深度可分离卷积通过深度卷积和逐点卷积两步操作显著减少了计算量,并在参数量和FLOPs方面进行了具体对比。
正文
Depthwise Separable Convolution 的目的是减少计算量,提高计算速度。
普通卷积
对于普通卷积,每个卷积核同时操作输入图像的每个通道。任意个与原图像同通道数的卷积核,对原图像进行卷积。生成图像通道数 = feature map数量 = 卷积核个数
深度可分离卷积
对于Depthwise Separable 卷积,将一个完整的卷积运算分解为两个步骤:Depth-wise卷积 + Point-wise 卷积。
- Depth-wise 卷积:一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
- 生成图像通道数 = feature map数量 = 输入层通道数
- 无法扩展feature map数量,每个通道独立进行卷积,难以有效利用不同通道在相同空间位置上的feature 信息,所以需要point-wise卷积来将这些feature map进行维度扩展,组合生成新的feature map。
- point-wise 卷积:与普通卷积运算相似。卷积核尺寸为1*1*M,M为上一层的通道数。
- 将上一步得到的feature map在深度方向上进行加权组合,生成新的feature map。(通道数扩展)
- 生成feature map数量 = M(卷积核个数)
举例说明
普通卷积
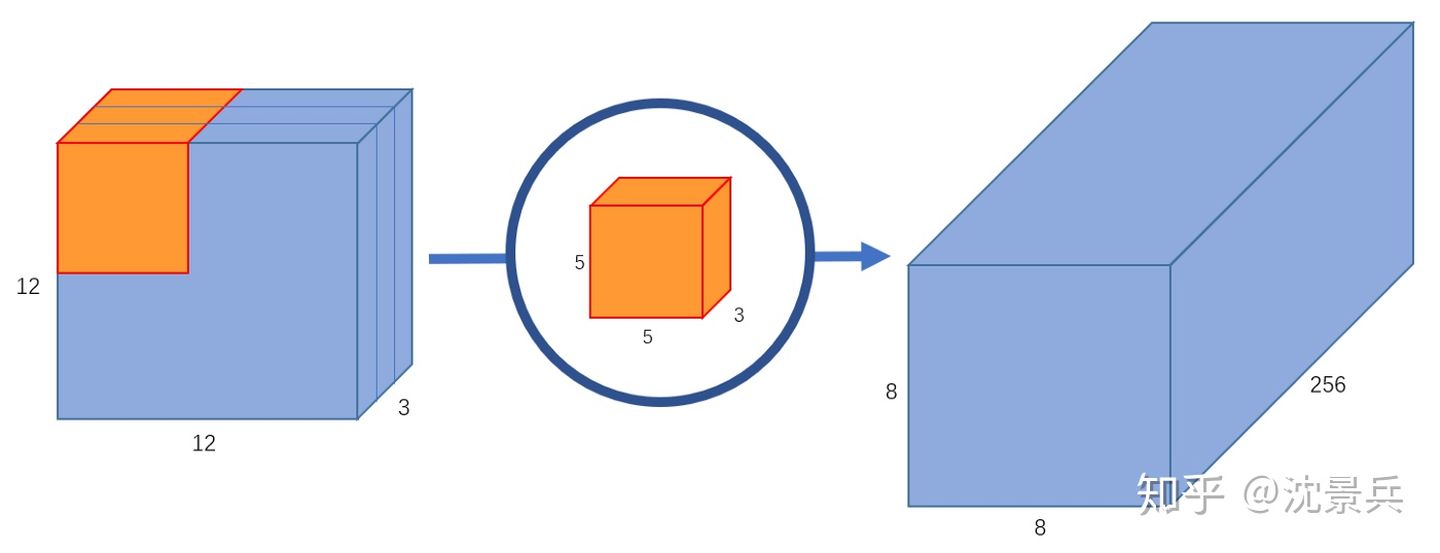
普通卷积:
- input feature map:[12,12,3]
- output feature map:[8,8,256]
- 需要256个[5,5,3]的卷积核。
参数量:256 x 5 x 5 x 3 = 19200,
FLOPs:256 x 5 x 5 x 3 x 8 x 8 = 1228800。
Depthwise Separable Convolution
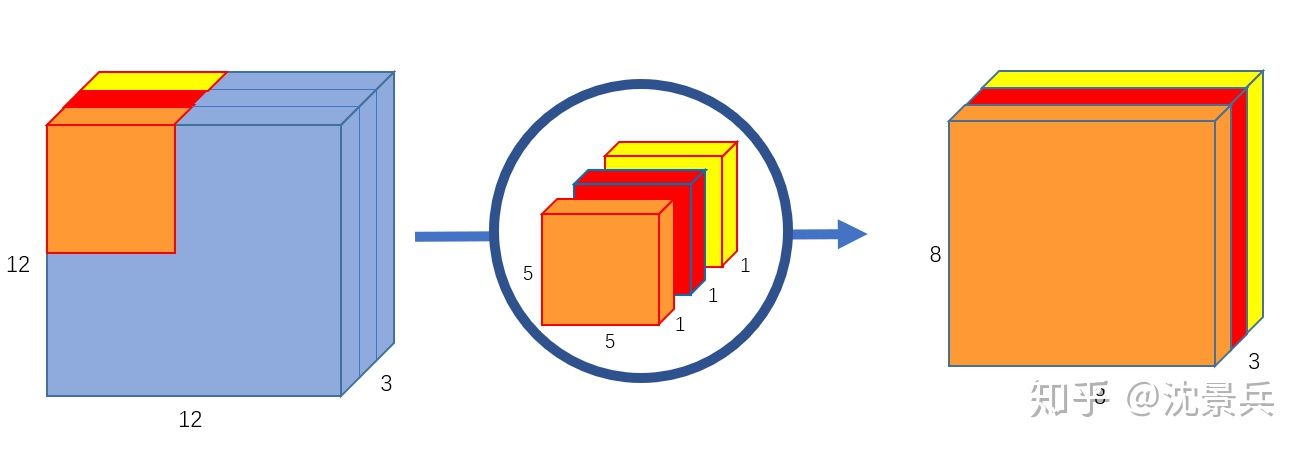
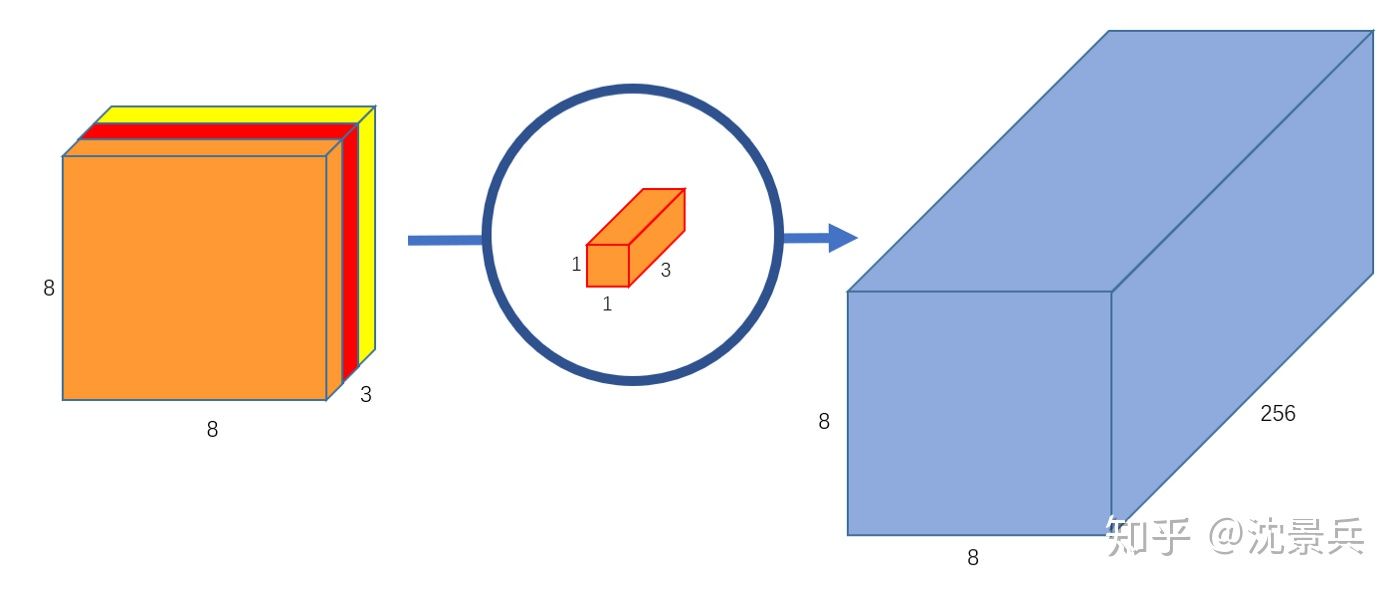
分为2部分:depth-wise卷积 + point-wise 卷积
先用depth-wise卷积进行深度分离(一个卷积核负责一个通道),再使用point-wise卷积实现特征图维度扩展。
- 深度分离,
- input feature map:[12,12,3]
- output feature map:[8,8,3]
- 需分别使用3个[5,5,1]的卷积核
- 进行维度扩展
- input feature map:[8,8,3]
- output feature map:[8,8,256]
- 需使用256个[1,1,3]的卷积核
参数量 :3 x 5 x 5 x 1 + 256 x 1 x 1 x 3 = 843
FLOPs: 3 x 5 x 5 x 1 x 8 x 8 + 256 x 1 x 1 x 3 x 8 x 8 = 53952
Depthwise Separable Convolution的FLOPs只有普通卷积的~4.4%,计算量大大降低。
但相同FLOPs条件下,深度可分离卷积的IO读取次数是普通卷积的100倍,其速度瓶颈为IO速度。
大部分时候,对于GPU,算力瓶颈在于访存带宽。而同种计算量,访存数据量差异巨大。
参考博客
什么是depthwise separable convolutions_猫猫与橙子的博客-CSDN博客_depthwise什么意思

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









