







在本次的博客当中,为了巩固关于链表技能的运用,我们先来看一些与链表有关的OJ题。
🌵反转链表
题目详情如下:
第一道题目从逻辑上看不难,我们只需要将链表进行拆分,将我们下一个节点进行一个类似于头插的操作即可。需要我们注意的是我们需要创建一个指针变量接收我们的下一个节点的地址之后才可以进行节点下一个位置的覆盖,否则就会造成节点的遗失。

所进行编写的代码如下:
struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)
return head;
if(head->next==NULL)
return head;
//接收头节点的指针
struct ListNode*next=head->next;
//接收拆下链表的节点
struct ListNode*prev=head;
//
struct ListNode*ret=next;
head->next=NULL;
while(next)
{
next=next->next;
ret->next=prev;
prev=ret;
if(next!=NULL)
{
ret=next;
}
}
return ret;
}

本题目需要我们使用一些小技巧,比如说快慢指针,我们需要设置两个指针,均从链表的头部开始。一个慢指针一次走一步,一个快指针一次走两步,我们最后得到的就是链表的中间节点。(当我们链表当中的数据为奇数个的时候,满指针所指向的是中间的节点,快指针指向的是中间靠后的一个节点)

 就像是我们上面的构思图所示,我们只需要判断我们fast节点的下一位是否为NULL就可以判断链表是否已经遍历结束。但是我们会发现当我们的链表节点个数为偶数的时候fast指针最后会指向NULL,如果这个时候将NULL作为地址判断next的话就会产生空指针的非法使用的问题。我们可以分开判断一次判断fast即可。所示的代码如下:
就像是我们上面的构思图所示,我们只需要判断我们fast节点的下一位是否为NULL就可以判断链表是否已经遍历结束。但是我们会发现当我们的链表节点个数为偶数的时候fast指针最后会指向NULL,如果这个时候将NULL作为地址判断next的话就会产生空指针的非法使用的问题。我们可以分开判断一次判断fast即可。所示的代码如下:
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode*before=head;
struct ListNode*next=head;
while(next)
{
next=next->next;
if(next==NULL)
{
return before;
}
else
{
next=next->next;
}
before=before->next;
}
return before;
}

这道题看起来很难可是思路却和我们判断链表的中间节点很类似。我们同样需要设置一个前后指针。我们想要寻找倒数第k个节点就可以先让一个指针走k-1步之后让另一个指针从开始的头节点开始走,最后当先走的那个指针指向NULL的时候,我们后走的指针得到的就是倒数第K个位置的指针。
 我们循环的结束条件可以设置为我们的first指针的next为NULL。按照我们上述思路可以书写出以下的代码:
我们循环的结束条件可以设置为我们的first指针的next为NULL。按照我们上述思路可以书写出以下的代码:
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
// write code here
//判断节点为空
if(pListHead==NULL)
{
return NULL;
}
struct ListNode*behind=pListHead;
struct ListNode*next=pListHead;
//后节点先走k-1步
k--;
while(k--)
{
if(next->next==NULL)
{
return NULL;
}
next=next->next;
}
while(next->next!=NULL)
{
behind=behind->next;
next=next->next;
}
return behind;
}

想要合并两个链表其实很简单我们只需要将我们两个链表进行分别的拆分,之后比较大小,将较小的一方拼接入新的链表当中。(为了是我们节点拼接更加方便,我们可以后才能构建一个头节点,将我们查下来的节点链接进入我们头节点的后面即可)所示代码如下:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode* ret1 = list1;
struct ListNode* ret2 = list2;
struct ListNode* newnode = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* first = newnode;
while (ret1 && ret2)
{
if (ret1->val >= ret2->val)
{
newnode->next = ret2;
ret2 = ret2->next;
newnode = newnode->next;
}
else
{
newnode->next = ret1;
ret1 = ret1->next;
newnode = newnode->next;
}
}
//将另一个没有处理完的链表链入我们的合并链表当中
if (ret1 == NULL)
{
newnode->next = ret2;
}
else
{
newnode->next = ret1;
}
struct ListNode* ret = first->next;
free(first);
first = NULL;
return ret;
}
🌵 链表分割

阅读我们题目中的要求我们可以知道,我们需要进行的操作就是将我们链表当中的数据进行分裂,大于等于特定值的归为一类,小于特定值的归为另一类。我们可以创建两个节点,将我们较小的放入lower节点后面,将我们较大的放入bigger节点后面。之后再将lower和bigger两个链表拼接即可得到我们目标的链表。

经过上面的梳理我们可以写出以下的代码:
ListNode* partition(ListNode* pHead, int x)
{
// write code here
//开辟两个新的结构体变量
//将我们的大于或者小于定值的节点放到指定位置后面
struct ListNode*bigger=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode*lower=(struct ListNode*)malloc(sizeof(struct ListNode));
//创建三个结构体指针变量
//分别作为我们遍历链表,后面释放开辟好的节点进行使用
struct ListNode*HeadBigger=bigger;
struct ListNode*HeadLower=lower;
struct ListNode*ret=pHead;
//开始遍历链表
while(ret)
{
if(ret->val<x)
{
lower->next=ret;
lower=lower->next;
}
else
{
bigger->next=ret;
bigger=bigger->next;
}
ret=ret->next;
}
lower->next=HeadBigger->next;
bigger->next=NULL;
struct ListNode*retu=HeadLower->next;
free(HeadBigger);
free(HeadLower);
return retu;
}
🌵 链表的回文结构

要是学过栈结构的朋友们一看到这个题目都会想到,我们可以使用栈呀!就和我们括号的判断一样。但是对于栈我们还没有进行讲解,所以我们先来使用一些技巧进行进行本道题目的讲解:
要想判断我们的链表是否为回文结构,我们只需要从中间节点开始判断即可。因为假如符合我们的回文结构的话前面的节点的内容和我们后面节点当中的内容是完全逆置的。所以对于本题我们需要进行的操作为:先找到来链表当中的中间节点,之后将我们的后半部分链表进行逆序,最后在判断我们前后链表的结构是否相同(可以剩下一个节点不做判断,即当我们节点的个数为奇数个时,我们只需要知道一个链表为空即为链表的遍历结束。)

所编写的代码如下:
struct ListNode* reverseList(struct ListNode* head)
{
if(head==nullptr)
return head;
if(head->next==nullptr)
return head;
//接收头节点的指针
struct ListNode*next=head->next;
//接收拆下链表的节点
struct ListNode*prev=head;
//
struct ListNode*ret=next;
head->next=nullptr;
while(next)
{
next=next->next;
ret->next=prev;
prev=ret;
if(next!=nullptr)
{
ret=next;
}
}
return ret;
}
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode*before=head;
struct ListNode*next=head;
while(next)
{
next=next->next;
if(next==nullptr)
{
return before;
}
else
{
next=next->next;
}
before=before->next;
}
return before;
}
bool chkPalindrome(ListNode* phead)
{
// write code here
ListNode* mid = middleNode(phead);
ListNode* rmid = reverseList(mid);
while (phead && rmid)
{
if (phead->val != rmid->val)
{
return false;
}
phead = phead->next;
rmid = rmid->next;
}
return true;
}其中的查找中间节点的函数和逆序函数复用我们之前实现好的即可。

🌵 相交链表

这道题相比于我们之前的题目来说简单很多。我们观察一下相交链表的特点我们会发现:我们的链表一旦相交那么最后一个节点的地址一定相同,否则最后一个节点的值就不同。我们可以利用这一特点很简单的编写我们的代码。我们可以对这两个链表分别进行遍历,找到最后的节点,然后判断两个节点的地址是否相同即可。所示代码如下:
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB)
{
//count代表的是两个链表的节点个数之差
struct ListNode* s1 = headA;
struct ListNode* s2 = headB;
while (s1->next)
{
s1 = s1->next;
}
while (s2->next)
{
s2 = s2->next;
}
if (s1 != s2)
{
return NULL;
}
int count = 0;
struct ListNode* ret1 = headA;
struct ListNode* tmp1 = headA;
struct ListNode* ret2 = headB;
struct ListNode* tmp2 = headB;
while (ret1 && ret2)
{
ret1 = ret1->next;
ret2 = ret2->next;
}
if (ret1 == NULL)
{
while (ret2)
{
ret2 = ret2->next;
count++;
}
while (count--)
{
tmp2 = tmp2->next;
}
}
else
{
while (ret1)
{
ret1 = ret1->next;
count++;
}
while (count--)
{
tmp1 = tmp1->next;
}
}
while (tmp1 != tmp2)
{
tmp1 = tmp1->next;
tmp2 = tmp2->next;
}
return tmp1;
}
🌵 环形链表

链表带环问题其实就是一个追击相遇问题。我们只需要使用我们前面说到过的快慢指针的方法即可。 我们可以让我们的一个指针每次先走一步,另一个指针每次走两步。如果链表带环的话那么我们的快指针最后一定会追上我们的慢指针。我们利用上述的思路可以编写如下的代码:
bool hasCycle(struct ListNode* head)
{
if (head == NULL)
{
return false;
}
if (head->next == head)
{
return true;
}
struct ListNode* before = head;
struct ListNode* behind = head;
while (behind)
{
before = before->next;
behind = behind->next;
if (behind == NULL)
{
return false;
}
else
{
behind = behind->next;
}
if (behind == before)
{
return true;
}
}
return false;
}
🌵 循环链表2

我们本道链表带环问题可以说是我们上一道题目的plus版。我们不仅需要判断链表是否带环,还需要返回我们刚进入环内的节点。对于本题我们可以采用一些数学上的逻辑来进行推断:
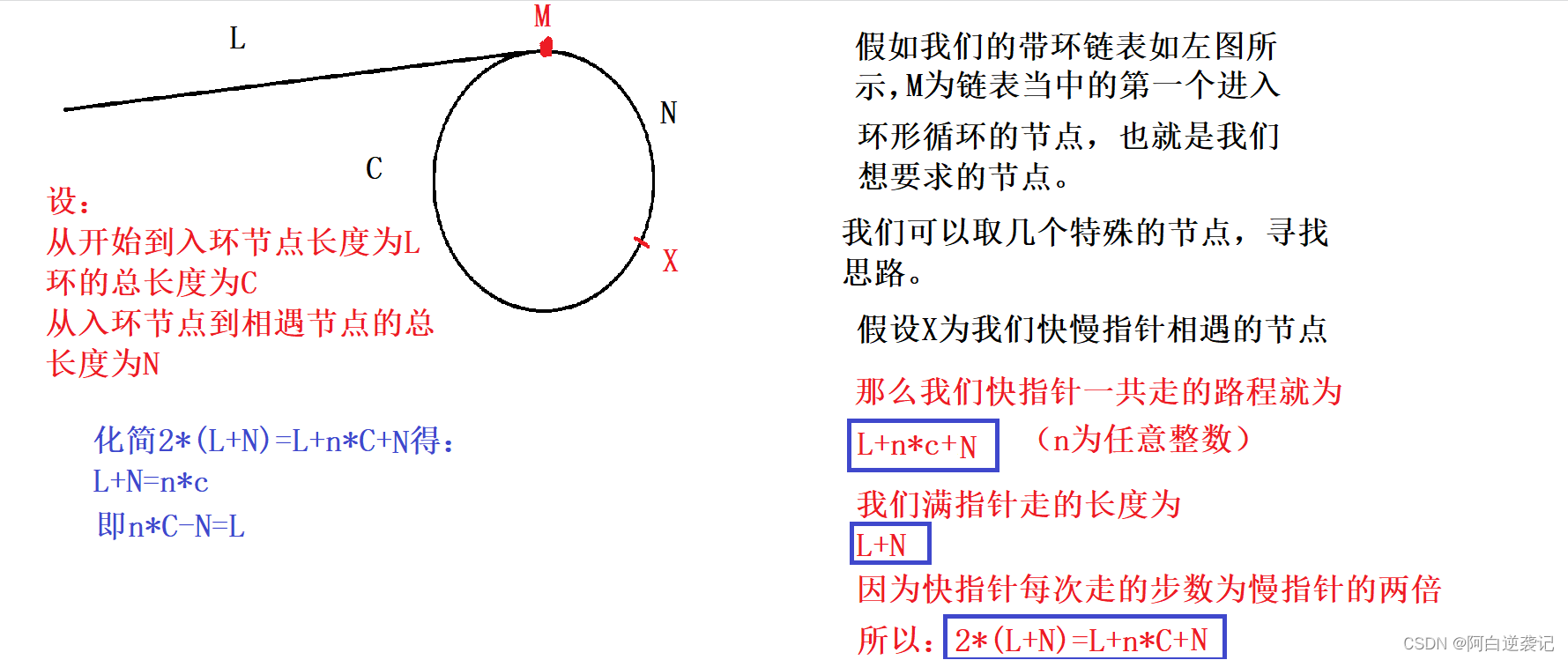 经过我们上面的推导之后我们就得出了n*C-N=L,也就是说我们从开始到循环节点的路程等于我们走整圈的数量减去我们从开始循环节点到我们相遇节点的距离。那么假如我们提前将这个N走完了,也就是说只要我们从相遇节点出发两个指针一旦相遇那么相遇节点一定就是我们进入循环的节点了呢?根据我们上面所推得的结论我们可以编写以下代码:
经过我们上面的推导之后我们就得出了n*C-N=L,也就是说我们从开始到循环节点的路程等于我们走整圈的数量减去我们从开始循环节点到我们相遇节点的距离。那么假如我们提前将这个N走完了,也就是说只要我们从相遇节点出发两个指针一旦相遇那么相遇节点一定就是我们进入循环的节点了呢?根据我们上面所推得的结论我们可以编写以下代码:
struct ListNode *detectCycle(struct ListNode *head)
{
//判断相遇的节点
struct ListNode*fast=head;
struct ListNode*slow=head;
struct ListNode*meetnode=NULL;
struct ListNode*retu=NULL;
if(head==NULL)
{
return NULL;
}
while(fast&&slow)
{
fast=fast->next;
if(fast==NULL)
{
return NULL;
}
else
{
fast=fast->next;
}
slow=slow->next;
if(fast==slow)
{
meetnode=fast;
break;
}
}
//一个节点从头开始走,一个节点从相遇节点开始走,最后在循环节点相遇
struct ListNode*begin=head;
if(head==meetnode)
{
return head;
}
while(begin&&meetnode)
{
begin=begin->next;
meetnode=meetnode->next;
if(begin==meetnode)
{
retu=begin;
return begin;
}
}
return NULL;
}

最后两道题可能是我们本次博客最难的两道题目了,只要掌握好了这两道题相信我们对于链表的理解已经很深刻了。接下来我们来攻破最后一道难关。
对于这一道题目如果没有一个清晰的思路我们会感到很头疼,接下来我来向大家介绍一种思路:
我们想要复制上面的代码可以尝试着创建相等数量的节点,最后将我们每一个节点链接到我们相应节点的后面,之后将我们的random指针指向我们原链表当中节点的下一个即可。
 唯一需要我们特别注意的是我们需要特别判断我们的random指向null的情况,因为指向空在进行next引用的话就会产生空指针的非法引用的问题。
唯一需要我们特别注意的是我们需要特别判断我们的random指向null的情况,因为指向空在进行next引用的话就会产生空指针的非法引用的问题。
当我们来链接好我们的新建链表之后我们只需要在再进行链表拆分,拆下我们拼接上的节点即可。经过我们上面的思路我们可以编写如下的代码:
struct Node* BuyNewNode(int data)
{
struct Node* newnode = (struct Node*)malloc(sizeof(struct Node));
newnode->val = data;
newnode->next = NULL;
return newnode;
}
struct Node* copyRandomList(struct Node* head) {
//在每一个节点的后面创建一个新的节点,用于生成新的链表
if (head == NULL)
{
return NULL;
}
if (head->next == NULL)
{
struct Node* ret1 = (struct Node*)malloc(sizeof(struct Node));
if(head->random==NULL)
{
ret1->random=NULL;
}
else
{
ret1->random=ret1;
}
ret1->val = head->val;
ret1->next = head->next;
return ret1;
}
struct Node* tmp = head;
while (tmp)
{
struct Node* newnode = BuyNewNode(tmp->val);
//保存链表当中下一个节点的地址
struct Node* ret = tmp->next;
tmp->next = newnode;
newnode->next = ret;
tmp = ret;
}
//将节点中的随机值复制进入新的节点
tmp = head;
while (tmp)
{
if (tmp->random==NULL)
{
tmp->next->random = NULL;
}
else
{
tmp->next->random = tmp->random->next;
}
tmp = tmp->next->next;
}
//将创建好的新的链表进行拆解
//跳过原链表当中的节点
tmp = head->next;
struct Node* retu = head->next;
struct Node* newlist = tmp;
while (tmp)
{
newlist->next = newlist->next->next;
tmp = newlist->next->next;
newlist = newlist->next;
}
newlist->next = NULL;
return retu;
}
以上就是我们本次博客的主要内容了,感谢您的观看,再见。
















 3225
3225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











