







上次我们已经登录进了首页,明白了爬虫的原理,这次我们看一下web界面是如何实现的.
项目地址 https://github.com/Nickqiaoo/go-webcrawler
程序目前的功能很简单一共四个函数.Welcone处理登录请求,Querycredit处理学分查询,Querygrade处理成绩查询.
func main() {
http.HandleFunc("/credit", controller.Querycredit)
http.HandleFunc("/login/", controller.Welcome)
http.HandleFunc("/static/", controller.Welcome)
http.HandleFunc("/grade", controller.Querygrade)
err := http.ListenAndServe(":9090", nil)
if err != (nil) {
log.Fatal("ListenAndServe:", err)
}
}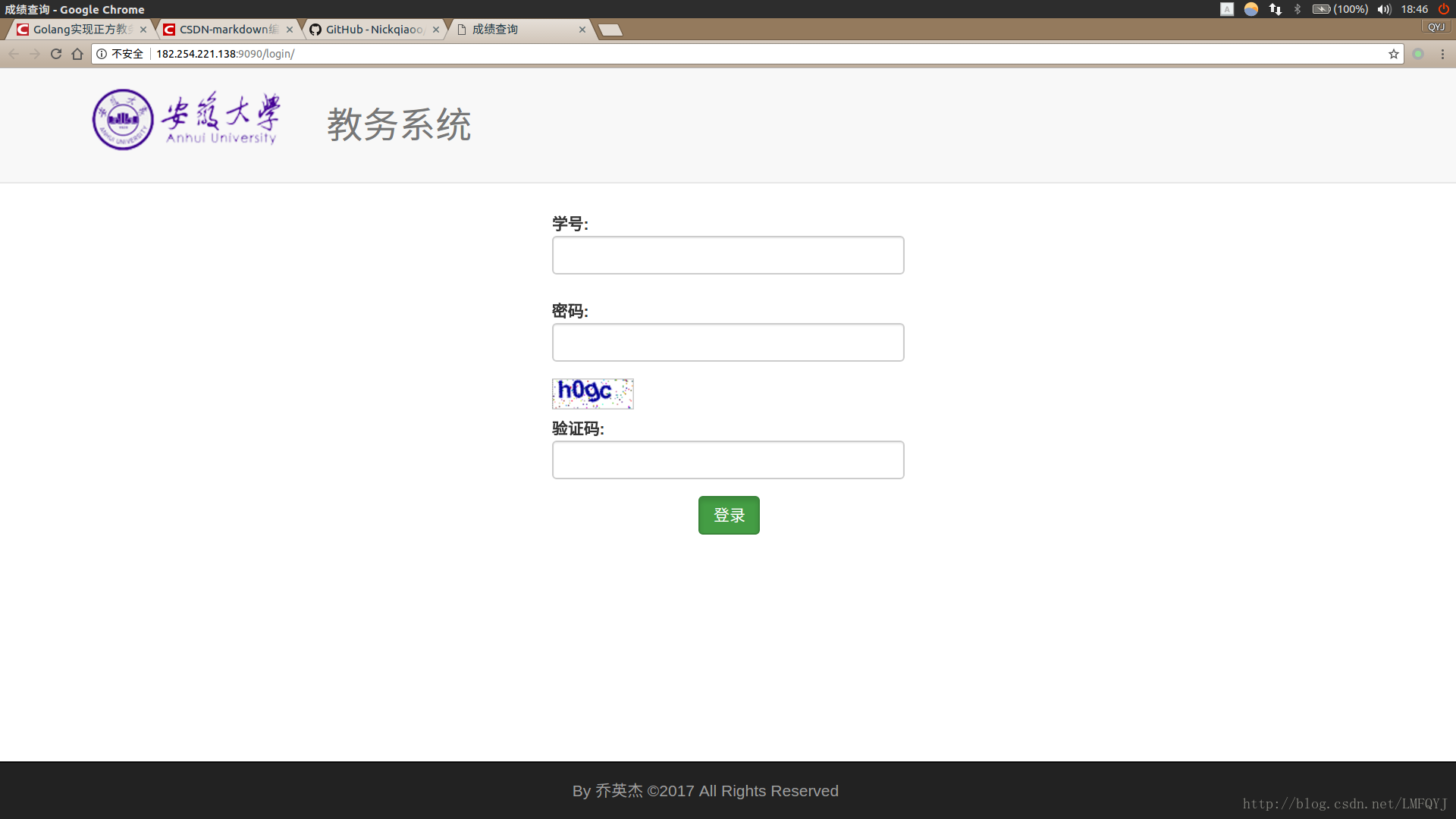
Welcome函数中判断请求方式,GET请求则返回login界面,POST请求处理登录返回welcome界面.
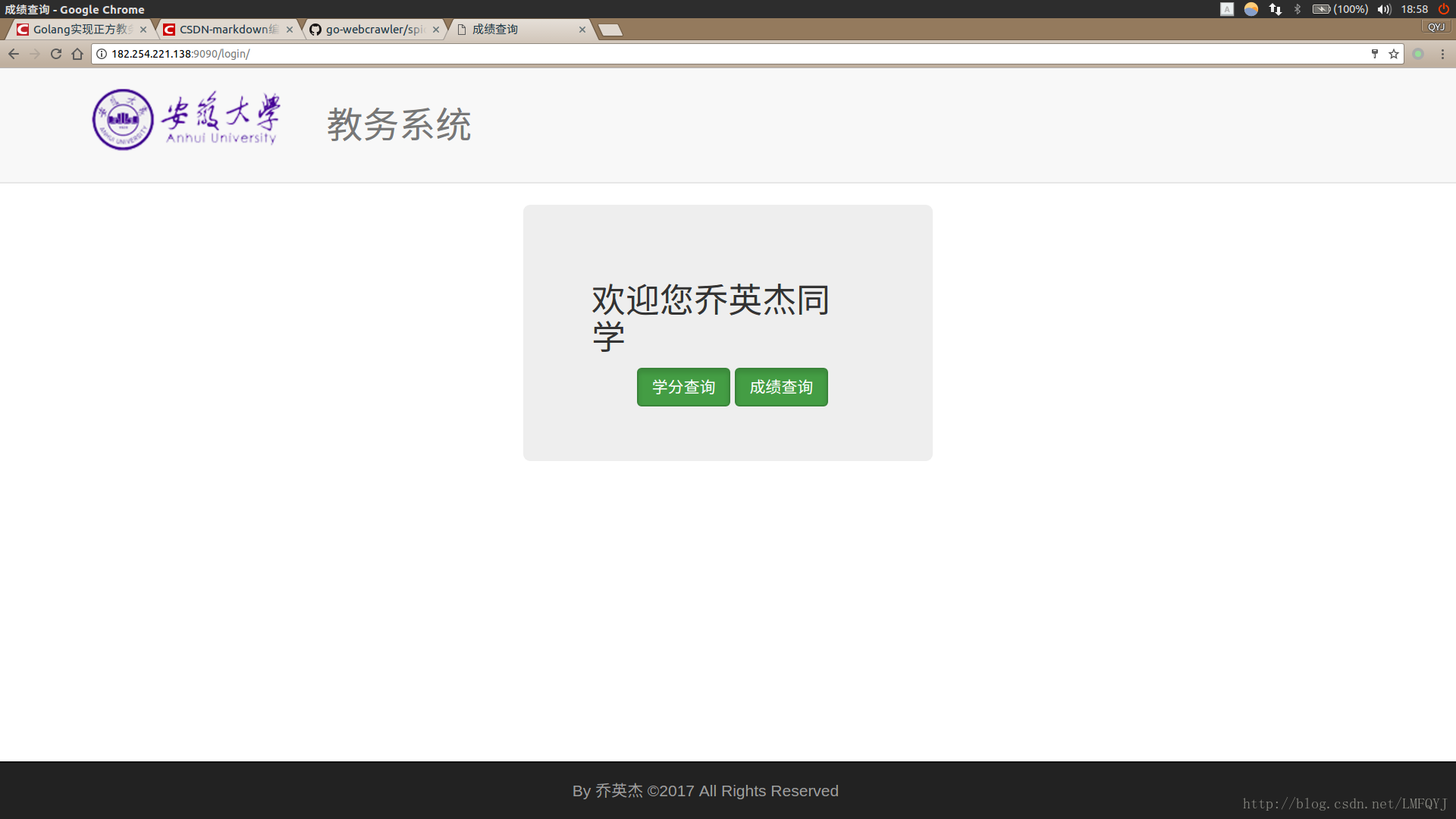
welcome界面做了一些处理,第一为了两个按钮提交到不同的处理函数,这里提交是用js实现的,第二这里用了两个hidden标签记录姓名和学号,直接POST给查询函数,因为后面查询的URL需要用这两个参数进行拼接,这样服务端无需对用户信息作保存.
这里重点说一下cookie策略
对每一个用户,我们要保证他每次提交到教务系统的cookie都一样,我一开始的思路是向获取教务系统的cookie,再生成用户cookie将两个cookie关联,后来发现其实可以直接将教务系统的cookie直接给用户作为用户cookie,这样服务端什么都不用存.
req, err := c.Get(Url2)
cook := c.Jar.Cookies(u)
cookie := http.Cookie{Name: cook[0].Name, Value: cook[0].Value, Path: "/", MaxAge: 800}
http.SetCookie(w, &cookie)之后的查询就和之前一样了,拼接查询的url地址,POST请求.这里我们如何从返回的html里提取我们需要的信息呢?一种思路是正则,我觉得太麻烦.这里我们用一个goquery库
doc := decoder.NewReader(response.Body)
result, _ := goquery.NewDocumentFromReader(doc)
view, _ := result.Find("#__VIEWSTATE").Attr("value")
event, _ := result.Find("#__EVENTVALIDATION").Attr("value")直接获取DOM节点的值,很方便.














 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









