








专题:大数据单机学习环境搭建和使用
大数据单机学习环境搭建(1)Hadoop本地单节点安装
1.资源获取(免费下载)
apache官网下载hadoop
jdk安装包百度网盘下载 提取码:0u1v
2.Hadoop(本地模式)安装及文件配置
严格按照步骤走,不要跳,不要跳,不要跳
2.1安装java
# 2.1先安装java
cd /opt
tar -zxvf jdk-8-linux-x64.tar.gz
mv jdk1.8.0_301 jdk
# 配置环境变量/etc/profile在最后添加
#set java environment
export JAVA_HOME=/opt/jdk/
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 更新配置文件使其立即生效
source /etc/profile
2.2Hadoop安装与配置
# 2.2hadoop安装
tar -zxvf hadoop-3.3.2.tar.gz -C /opt
mv hadoop-3.3.2.tar.gz hadoop
# 2.2.1配置环境变量/etc/profile
vim /etc/profile
# 在最后添加
#HADOOP_HOME
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 更新配置文件使其立即生效
source /etc/profile
# 2.2.2编辑配置文件hadoop-env.sh
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
# 将JAVA_HOME设置为Java安装根路径
export JAVA_HOME="/opt/jdk"
# 2.2.3修改配置文件mapred-env.sh
vim /opt/hadoop/etc/hadoop/mapred-env.sh
# 将JAVA_HOME设置为Java安装根路径
export JAVA_HOME="/opt/jdk"
# 2.2.4修改配置文件yarn-env.sh
vim /opt/hadoop/etc/hadoop/yarn-env.sh
# 将JAVA_HOME设置为Java安装根路径
export JAVA_HOME="/opt/jdk"
# 2.2.5修改配置文件core-site.xml
vim /opt/hadoop/etc/hadoop/core-site.xml
# 配置
<property>
<name>fs.defaultFS</name>
<!-- ip填自己的,端口号默认 -->
<value>hdfs://192.168.0.107:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- tmp为namenode数据存放目录 -->
<value>/opt/hadoop/tmp</value>
</property>
# 2.2.6修改配置文件hdfs-site.xml
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
# 配置
<property>
<name>dfs.replication</name>
<!-- 伪分布式环境只有一个节点,所以这里设置为1 -->
<value>1</value>
</property>
<!--设置默认端口,这段是我后来加的,如果不加上会导致启动hadoop-3.1.0后无法访问50070端口查看HDFS管理界面,hadoop-2.7.7可以不加-->
<property>
<name>dfs.http.address</name>
<value>192.168.0.107:9870</value>
</property>
# 2.2.7修改配置文件mapred-site.xml
vim /opt/hadoop/etc/hadoop/mapred-site.xml
# 配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# 2.2.8修改配置文件yarn-site.xml
vim /opt/hadoop/etc/hadoop/yarn-site.xml
# 配置
<!-- ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.107</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2.3设置ssh免密登录
# 2.3设置ssh免密登录
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
cd # 退到开始位置
2.4开启hadoop
# 2.4开启hadoop
# 2.4.1格式化namenode,格式化之前清空 tmp 和 logs文件
rm -rf tmp/*
rm -rf logs/*
hdfs namenode -format
# 验证
ls /opt/hadoop/tmp/dfs/name/current
# fsimage是NameNode元数据在内存满了后,持久化保存到的文件。
# fsimage*.md5 是校验文件,用于校验fsimage的完整性。
# seen_txid 是hadoop的版本
# vession文件里保存:
# namespaceID:NameNode的唯一ID。
# clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群。
# 2.4.2使用start-all开启所有进程
start-all.sh
# 2.5.3用jps验证,6个进程都有就ok了,前面是进程号
104224 Jps
44242 ResourceManager
44535 NodeManager
43256 DataNode
43739 SecondaryNameNode
42924 NameNode
2.6访问应用
# 2.6访问应用
# 2.6.1关闭防火墙
# 防火墙会阻止非本机对服务发起的请求,所以,如果要让外界访问到hadoop服务一定要配置防火墙,如果是在虚拟机上,就可以直接关闭了。
systemctl stop firewalld # 临时关闭
systemctl disable firewalld # 永久关闭
# 网页访问2.6.2访问
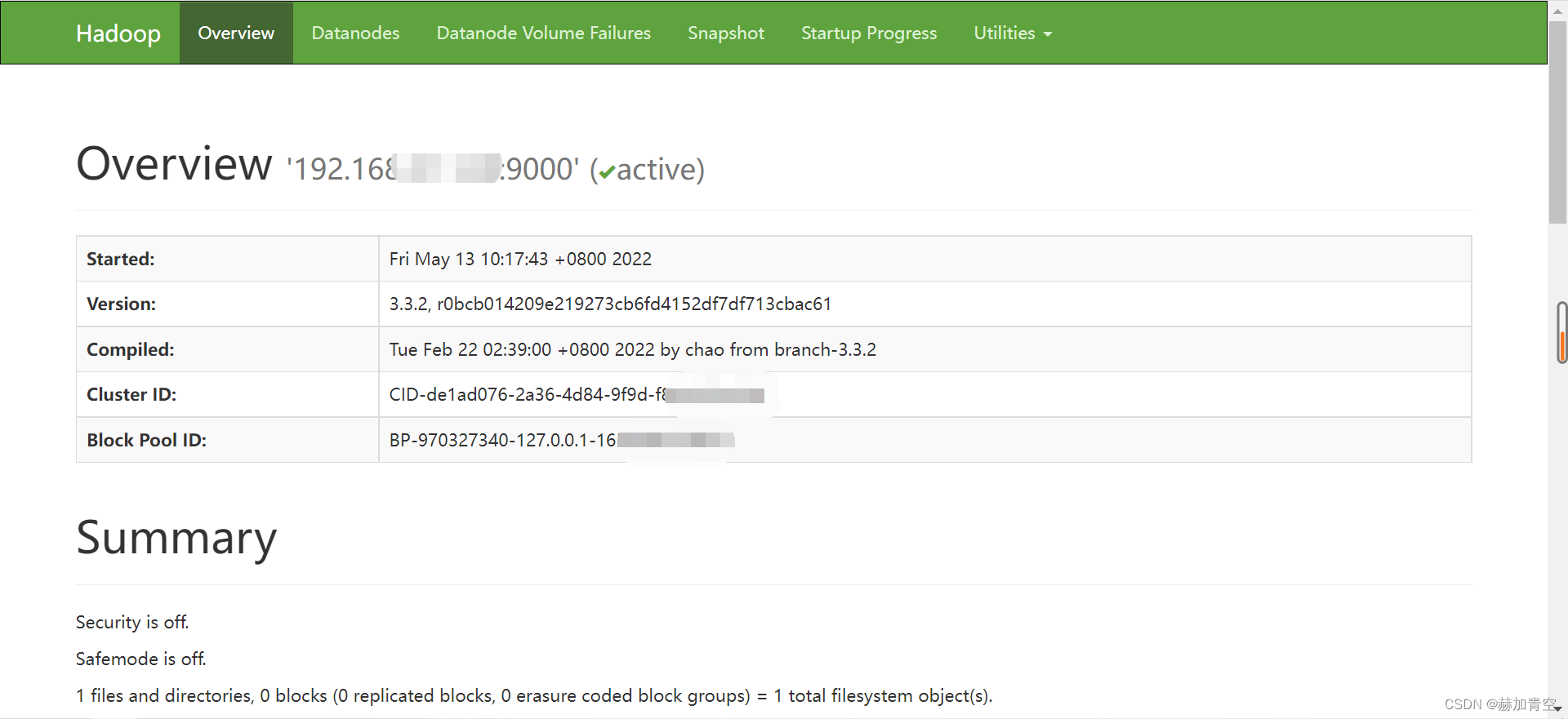
http://192.168.0.107:9870
能访问到下图界面即安装和配置已成功
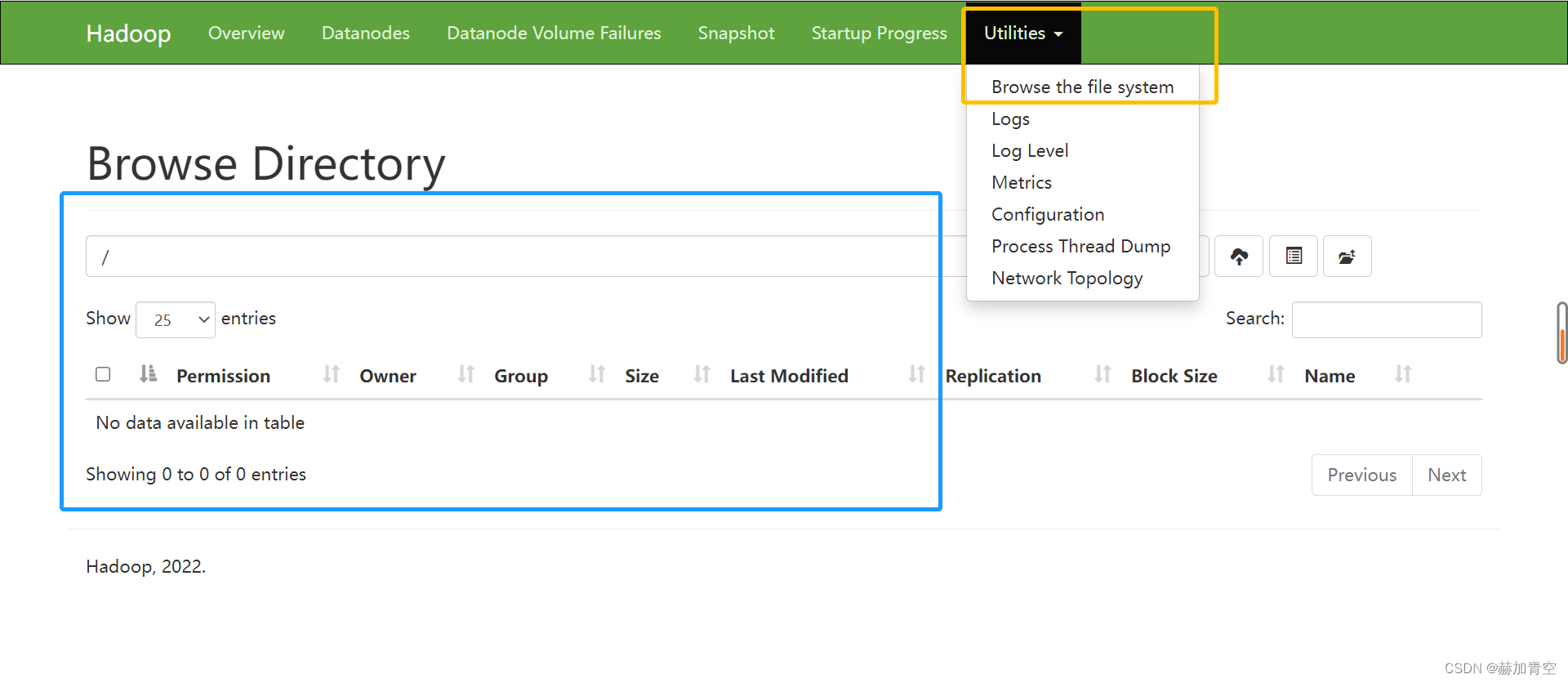
下方图片所示位置即HDFS文件所在位置,例如Hive、Spark访问时即要访问这里。
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,如有雷同纯属巧合。















 1811
1811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









