







 本文深入探讨了Linux内核的源码结构,包括内核核心、非核心代码和辅助文件。重点讲解了内核中的链表和红黑树数据结构,以及它们在内存管理和进程调度中的应用。CFS调度器通过虚拟运行时间实现公平调度,而虚拟内存管理利用红黑树高效管理进程的虚拟地址空间。此外,还介绍了无锁环形缓冲区KFIFO在内核中的使用,它是生产者消费者模型的一种实现。
本文深入探讨了Linux内核的源码结构,包括内核核心、非核心代码和辅助文件。重点讲解了内核中的链表和红黑树数据结构,以及它们在内存管理和进程调度中的应用。CFS调度器通过虚拟运行时间实现公平调度,而虚拟内存管理利用红黑树高效管理进程的虚拟地址空间。此外,还介绍了无锁环形缓冲区KFIFO在内核中的使用,它是生产者消费者模型的一种实现。
一、内核源码目录结构
1、Linux 内核源代码包括三个主要部分
1)内核核心代码:包括linux内核整体架构分析笔记描述的各子系统和子模块,以及其他支撑子系统,如:电源管理、linux初始化等。
2)非核心代码:例如库文件(因为 Linux 内核是一个自包含的内核,即内核不依赖其它的任何软件,自己就可以编译通过)、固件集合、 KVM(虚拟机技术)等。
3)编译脚本、配置文件、帮助文档、版权说明等辅助性文件。
2、内核源代码顶层目录结构:

- include/ :内核头文件,需要提供给外部模块(例如用户空间代码)使用。
- kernel/ : Linux 内核的核心代码,包含了 进程调度子系统,以及和进程调度相关的模块。
- mm/ :内存管理子系统
- fs/ ---- VFS 子系统。
- net/ ---- 不包括网络设备驱动的网络子系统。
- ipc/ ---- IPC(进程间通信)子系统。
- arch// ---- 体系结构相关的代码,例如 arm, x86 等等。
- arch//mach- ---- 具体的 machine/board 相关的代码。
- arch//include/asm ---- 体系结构相关的头文件。
- arch//boot/dts ---- 设备树( Device Tree)文件。
- init/ ---- Linux 系统启动初始化相关的代码。
- block/ ---- 提供块设备的层次。
- sound/ ---- 音频相关的驱动及子系统,可以看作“音频子系统”。
- drivers/ ---- 设备驱动
- lib/ ---- 实现需要在内核中使用的库函数,例如 CRC、 FIFO、 list、 MD5 等。
- crypto/ ----- 加密、解密相关的库函数。
- security/ ---- 提供安全特性( SELinux)。
- virt/ ---- 提供虚拟机技术( KVM 等)的支持。
- usr/ ---- 用于生成 initramfs 的代码。
- firmware/ ---- 保存用于驱动第三方设备的固件。
- samples/ ---- 一些示例代码。
- tools/ ---- 一些常用工具,如性能剖析、自测试等。
- Kconfig, Kbuild, Makefile, scripts/ ---- 用于内核编译的配置文件、脚本等。
- COPYING ---- 版权声明。
- MAINTAINERS ----维护者名单。
- CREDITS ---- Linux 主要的贡献者名单。
- REPORTING-BUGS ---- Bug 上报的指南。
- Documentation, README ---- 帮助、说明文档。
二、内核常用数据结构
Linux 内核代码中广泛使用了数据结构和算法,其中最常用的两个是链表和红黑树。
2.1 链表
链表是在解决数组不能动态扩展这个缺陷而产生的一种数据结构。
链表所包含的元素可以动态创建并插入和删除。
链表的每个元素都是离散存放的,因此不需要占用连续的内存。
链表通常由若干节点组成,每个节点的结构都是一样的,由有效数据区和指针区两部分组成。
有效数据区用来存储有效数据信息,而指针区用来指向链表的前继节点或者后继节点。
因此,链表就是利用指针将各个节点串联起来的一种存储结构。
1、单向链表
单向链表的指针区只包含一个指向下一个节点的指针,因此会形成一个单一方向的链表。
struct list {
int data; /*有效数据*/
struct list *next; /*指向下一个元素的指针*/
};
下图所示,单向链表具有单向移动性,也就是只能访问当前的节点的后继节点,而无法访问当前节点的前继节点,因此在实际项目中运用得比较少。

2、双向链表
双向链表和单向链表的区别是指针区包含了两个指针,一个指向前继节点,另一个指向后继节点。
struct list {
int data; /*有效数据*/
struct list *next; /*指向下一个元素的指针*/
struct list *prev; /*指向上一个元素的指针*/
};

3、linux内核链表
单向链表和双向链表在实际使用中有一些局限性,如数据区必须是固定数据,而实际需求是多种多样的。这种方法无法构建一套通用的链表,因为每个不同的数据区需要一套链表。
为此, Linux 内核把所有链表操作方法的共同部分提取出来,把不同的部分留给代码编程者自己去处理。
Linux 内核实现了一套纯链表的封装,链表节点数据结构只有指针区而没有数据区,另外还封装了各种操作函数,如创建节点函数、插入节点函数、删除节点函数、遍历节点函数等。
1)linux内核链表使用struct list_head数据结构来描述:
<include/linux/types.h>
struct list_head {
struct list_head *next, *prev;
};
2)struct list_head 数据结构不包含链表节点的数据区,通常是嵌入其他数据结构,如 struct page数据结构中嵌入了一个 lru 链表节点,通常是把 page 数据结构挂入 LRU 链表。
<include/linux/mm_types.h>
struct page {
...
struct list_head lru;
...
}
3)链表头的初始化有两种方法,一种是静态初始化,另一种动态初始化。把 next 和 prev 指针都初始化并指向自己,这样便初始化了一个带头节点的空链表。
<include/linux/list.h>
/*静态初始化*/
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
/*动态初始化*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
4) 添加节点到一个链表中,内核提供了几个接口函数,如 list_add()是把一个节点添加到表头,list_add_tail()是插入表尾。
<include/linux/list.h>
void list_add(struct list_head *new, struct list_head *head)
list_add_tail(struct list_head *new, struct list_head *head)
5) 遍历节点的接口函数
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
这个宏只是遍历一个一个节点的当前位置,那么如何获取节点本身的数据结构呢?这里还需要使用 list_entry()宏。
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
//container_of()宏的定义在 kernel.h 头文件中。
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
其中 offsetof()宏是通过把 0 地址转换为 type 类型的指针,然后去获取该结构体中 member成员的指针,也就是获取了 member 在 type 结构体中的偏移量。最后用指针 ptr 减去 offset,就得到 type 结构体的真实地址了。
6)遍历链表例子
//<drivers/block/osdblk.c>
static ssize_t class_osdblk_list(struct class *c,
struct class_attribute *attr,
char *data)
{
int n = 0;
struct list_head *tmp;
list_for_each(tmp, &osdblkdev_list) {
struct osdblk_device *osdev;
osdev = list_entry(tmp, struct osdblk_device, node);
n += sprintf(data+n, "%d %d %llu %llu %s\n",
osdev->id,
osdev->major,
osdev->obj.partition,
osdev->obj.id,
osdev->osd_path);
}
return n;
}
2.2 红黑树
红黑树( Red Black Tree)被广泛应用在内核的内存管理和进程调度中,用于将排序的元素组织到树中。
红黑树是具有以下特征的二叉树:
- 每个节点或红或黑。
- 每个叶节点是黑色的。
- 如果结点都是红色,那么两个子结点都是黑色。
- 从一个内部结点到叶结点的简单路径上,对所有叶节点来说,黑色结点的数目都是相同的。
红黑树的一个优点是,所有重要的操作(例如插入、 删除、搜索)都可以在 O(log n)时间内完成, n 为树中元素的数目。
内核中使用红黑树的例子( 源码来源文件documentation/Rbtree.txt ):
#include <linux/init.h>
#include <linux/list.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/slab.h>
#include <linux/mm.h>
#include <linux/rbtree.h>
MODULE_AUTHOR("figo.zhang");
MODULE_DESCRIPTION(" ");
MODULE_LICENSE("GPL");
struct mytype {
struct rb_node node;
int key;
};
/*红黑树根节点*/
struct rb_root mytree = RB_ROOT;
/*根据 key 来查找节点*/
struct mytype *my_search(struct rb_root *root, int new)
{
struct rb_node *node = root->rb_node;
while (node) {
struct mytype *data = container_of(node, struct mytype, node);
if (data->key > new)
node = node->rb_left;
else if (data->key < new)
node = node->rb_right;
else
return data;
}
return NULL;
}
/*插入一个元素到红黑树中*/
int my_insert(struct rb_root *root, struct mytype *data)
{
struct rb_node **new = &(root->rb_node), *parent=NULL;
/* 寻找可以添加新节点的地方 */
while (*new) {
struct mytype *this = container_of(*new, struct mytype, node);
parent = *new;
if (this->key > data->key)
new = &((*new)->rb_left);
else if (this->key < data->key) {
new = &((*new)->rb_right);
} else
return -1;
}
/* 添加一个新节点 */
rb_link_node(&data->node, parent, new);
rb_insert_color(&data->node, root);
return 0;
}
static int __init my_init(void)
{
int i;
struct mytype *data;
struct rb_node *node;
/*插入元素*/
for (i =0; i < 20; i+=2) {
data = kmalloc(sizeof(struct mytype), GFP_KERNEL);
data->key = i;
my_insert(&mytree, data);
}
/*遍历红黑树,打印所有节点的 key 值*/
for (node = rb_first(&mytree); node; node = rb_next(node))
printk("key=%d\n", rb_entry(node, struct mytype,node)->key);
return 0;
}
static void __exit my_exit(void)
{
struct mytype *data;
struct rb_node *node;
for (node = rb_first(&mytree); node; node = rb_next(node))
{
data = rb_entry(node, struct mytype, node);
if (data) {
rb_erase(&data->node, &mytree);
kfree(data);
}
}
}
module_init(my_init);
module_exit(my_exit);
mytree 是红黑树的根节点, my_insert()实现插入一个元素到红黑树中, my_search()根据 key来查找节点。内核大量使用红黑树。
三、CFS调度器
CFS(完全公平调度器)实现的主要思想是维护为任务提供处理器时间方面的平衡(公平性),这意味着应给进程分配相当数量的处理器。分给某个任务的时间失去平衡时(意味着一个或多个任务相对于其他任务而言未被给予相当数量的时间),应给失去平衡的任务分配时间,让其执行。
CFS 通过虚拟运行时间( vruntime)来实现平衡,维护提供给某个任务的时间量。
进程的虚拟时间是指实际运行时间相对于权重为 0 的进程的比例值。
在 CFS 调度器中有一个计算虚拟时间的核心函数 calc_delta_fair(),它的计算公式为:
vruntime = 实际运行时间*1024 / 进程权重
因此,进程按照各自不同的速率在物理时钟节拍内进行,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但获得比较多运行时间;反之,优先级低则权重小,其虚拟时钟比真实时钟跑得快,反而获得比较少的运行时间。
CFS调度器总是选择虚拟时钟跑得慢的进程来运行,从而让每个调度实体的虚拟运行时间互相追赶,进而实现进程调度上的平衡。
CFS 调度器没有将进程维护在运行队列中,而是维护了一个以虚拟运行时间为顺序的红黑树。
红黑树的主要特点有:
- 自平衡,树上没有一条路径会比其他路径长出俩倍。
- O(log n) 时间复杂度,能够在树上进行快速高效地插入或删除进程。
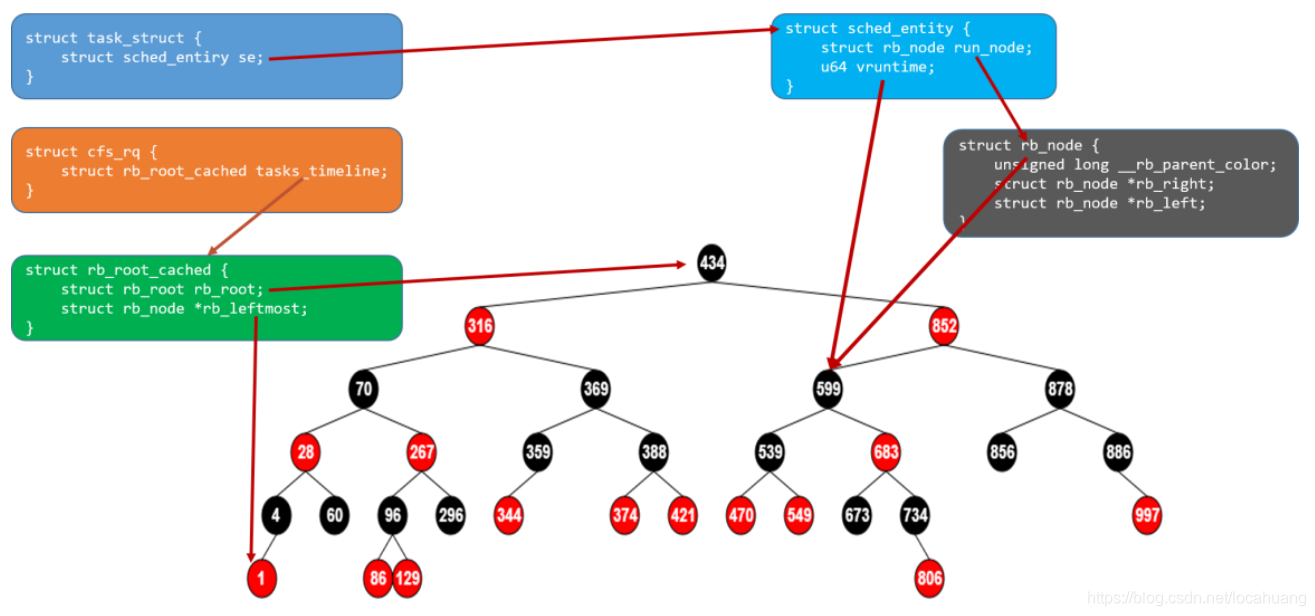
Linux 内的所有任务都由称为 task_struct 的任务结构表示,它位于调度的最顶端。该结构(在./linux/include/linux/sched.h)完整地描述了任务并包括了任务的当前状态、其堆栈、进程标识、优先级(静态和动态)等等。
struct task_struct{
...
volatile long state;
void *stack;
unsigned int flags;
int prio;
int static_prio;
int normal_prio;
struct sche_entity se;
...
};
但是,由于不是所有任务都是可运行的,所以在 task_struct 中不会发现任何与 CFS 相关的字段。因此,需要通过一个名为 sched_entity 的新结构来跟踪调度信息。
struct sched_entity{
...
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
u64 vruntime;
...
};
sched_entity 包含负载权重、各种统计数据以及 vruntime(任务运行的虚拟时间量,并作为红黑树的索引)。同时, sched_entity 还包含红黑树的节点 rb_node。
struct rb_node{
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
};
红黑树的每个节点都由 rb_node 表示,它只包含子引用和父对象的颜色。红黑树的叶子不包含信息,但是内部节点代表一个或多个可运行的任务。红黑树的根通过 rb_root_cached 结构中的 rb_root 引用,而该结构同时包含了红黑树的最左节点 rb_leftmost 的指针。
struct rb_root_cached{
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
在运行过程中, __schedule()(在./kernel/sched/core.c 中)是 CFS 调度器的核心函数,其作用是让调度器选择和切换到一个合适的进程运行。
在时钟周期开始时,调度器调用__schedule()函数来开始调度的运行。
然后, __schedule()函数调用 pick_next_task()让进程调度器从就绪队列中选择一个最合适的进程 next,即红黑树最左边的节点。
接着,通过 context_switch()切换到新的地址空间,从而保证 next 进程运行。
在时钟周期结束时,调度器调用 entity_tick()函数来更新进程负载、进程状态以及vruntime(当前 vruntime + 该时钟周期内运行的时间)。
最后,将该进程的虚拟时间与就绪队列红黑树中最左边的调度实体的虚拟时间做比较,如果小于坐左边的时间,则不用触发调度,继续调度当前调度实体。否则,则表明最左边的调度实体更需要调度。因此,调度器将当前调度实体放回红黑树,并选择红黑树中最左边的调度实体作为 next 在下一个时钟周期进行调度。
通过以上的结构和调度方式, Linux 内核保证了操作系统中进程调度的公平性。
四、虚拟内存管理
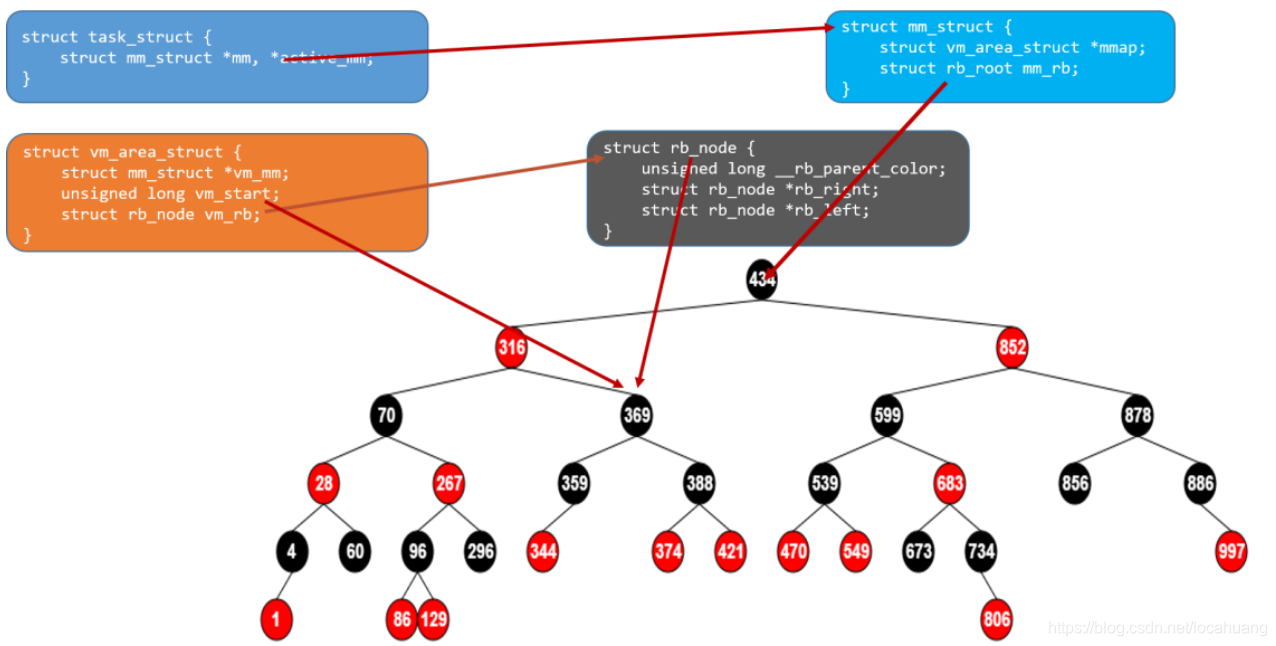
在内存管理中,在内核管理某个进程的内存时使用了红黑树,见下面数据结构(只保留和内存管理相关的成员),每个进程都有一个 active_mm 的成员用于管理该进程的虚拟内存空间。
struct mm_struct 中的成员 mm_rb 是红黑树的根,该进程的所有虚拟空间块(虚拟地址不连续)都以起始虚拟地址为 key 值挂在该红黑树上。
该进程新申请的虚拟内存区间会插入到这棵树上,当然插入过程中可能会合并相邻的虚拟区域。删除时会从该树上摘除相应的node。
在 32 位的系统上,线性地址空间可达到 4GB,这 4GB 一般按照 3:1 的比例进行分配,也就是说用户进程享有前 3GB 线性地址空间,而内核独享最后 1GB 线性地址空间。
由于虚拟内存的引入,每个进程都可拥有 3GB 的虚拟内存,并且用户进程之间的地址空间是互不可见、互不影响的,也就是说即使两个进程对同一个地址进行操作,也不会产生问题。
在前面介绍的一些分配内存的途径中,无论是伙伴系统中分配页的函数,还是 slab 分配器中分配对象的函数,它们都会尽量快速地响应内核的分配请求,将相应的内存提交给内核使用,而内核对待用户空间显然不能如此。用户空间动态申请内存时往往只是获得一块线性地址的使用权,而并没有将这块线性地址区域与实际的物理内存对应上,只有当用户空间真正操作申请的内存时,才会触发一次缺页异常,这时内核才会分配实际的物理内存给用户空间。
用户进程的虚拟地址空间包含了若干区域,这些区域的分布方式是特定于体系结构的,不过所有的方式都包含下列成分:
- 可执行文件的二进制代码,也就是程序的代码段
- 存储全局变量的数据段
- 用于保存局部变量和实现函数调用的栈
- 环境变量和命令行参数
- 程序使用的动态库的代码
- 用于映射文件内容的区域
由此可以看到进程的虚拟内存空间会被分成不同的若干区域,每个区域都有其相关的属性和用途,一个合法的地址总是落在某个区域当中的,这些区域也不会重叠。
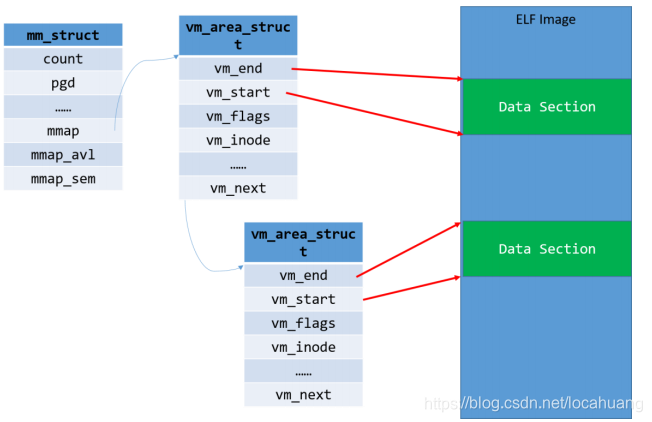
在 linux 内核中,这样的区域被称之为虚拟内存区域(virtual memory areas),简称 VMA。一个 vma 就是一块连续的线性地址空间的抽象,它拥有自身的权限(可读,可写,可执行等等) ,每一个虚拟内存区域都由一个相关的 struct vm_area_struct 结构来描述。
从进程的角度来讲, VMA 其实是虚拟空间的内存块,一个进程的所有资源由多个内存块组成,所以,一个进程的描述结 构task_struct中首先包含Linux的内存描述符mm_struct结构。
struct task_struct {
.......
struct mm_struct *mm;
.......
}
在 mm_struct 中进而包含了 vm_area_struct :
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result*/
.......
}
一个进程的每个 VMA 块都会链接到中的链表和红黑树:
- 1)mmap 形成一个单链表,一个进程的所有 VMA 都链接到这个链表,链表头是 mm->mmap。
- 2)mm_rb 是红黑树节点,每个进程都一个 VMA 红黑树。
VMA 按照起始地址递增的方式,插入到 mm_struct->mmap 链表。当进程拥有大量的 VMA的时候,搜索效率比较低,所以哟娜那个到红黑树来加快查找。
vm_area_struct:
struct vm_area_struct {
struct mm_struct * vm_mm; /* 所属的内存描述符 */
unsigned long vm_start; /* vma 的起始地址 */
unsigned long vm_end; /* vma 的结束地址 */
/* 该 vma 的在一个进程的 vma 链表中的前驱 vma 和后驱 vma 指针,链表中的 vma 都是按地址来排序的*/
struct vm_area_struct *vm_next, *vm_prev;
pgprot_t vm_page_prot; /* vma 的访问权限 */
unsigned long vm_flags; /* 标识集 */
struct rb_node vm_rb; /* 红黑树中对应的节点 */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
/* shared 联合体用于和 address space 关联 */
union {
struct {
struct list_head list;/* 用于链入非线性映射的链表 */
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;/*线性映射则链入 i_mmap 优先树*/
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
/*anno_vma_node 和 annon_vma 用于管理源自匿名映射的共享页*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
/*该 vma 上的各种标准操作函数指针集*/
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* 映射文件的偏移量,以 PAGE_SIZE 为单位 */
struct file * vm_file; /* 映射的文件,没有则为 NULL */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
所以进程的 VMA 的组织为:
五、无锁环形缓冲区
环形缓冲区是实现生产者和消费者模型的经典算法。
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区可写的数据。通过移动读指针和写指针实现缓冲区数据的读取和写入。
在 Linux 内核中, KFIFO 是采用无锁环形缓冲区的实现。它采用环形缓冲区的方法来实现,并提供一个无边界的字节流服务。采用环形缓冲区的好处是,当一个数据元素被消耗之后,其余数据元素不需要移动其存储位置,从而减少复制,提高效率。
1、创建KFIFO
在使用 KFIFO 之前需要进行初始化,这里有静态初始化和动态初始化两种方式。
<include/linux/kfifo.h>
int kfifo_alloc(fifo, size, gfp_mask)
该函数创建并分配一个大小为 size 的 KFIFO 环形缓冲区。第一个参数 fifo 是指向该环形缓冲区的 struct kfifo 数据结构;第二个参数 size 是指定缓冲区元素的数量;第三个参数 gfp_mask表示分配 KFIFO 元素使用的分配掩码。
静态分配可以使用如下的宏:
#define DEFINE_KFIFO(fifo, type, size)
#define INIT_KFIFO(fifo)
2、入列
把数据写入 KFIFO 环形缓冲区可以使用 kfifo_in()函数接口。
int kfifo_in(fifo, buf, n)
该函数把 buf 指针指向的 n 个数据复制到 KFIFO 环形缓冲区中。第一个参数 fifo 指的是 KFIFO环形缓冲区;第二个参数 buf 指向要复制的数据的 buffer;第三个数据是要复制数据元素的数量。
3、出列
从 KFIFO 环形缓冲区中列出或者摘取数据可以使用 kfifo_out()函数接口。
#define kfifo_out(fifo, buf, n)
该函数是从 fifo 指向的环形缓冲区中复制 n 个数据元素到 buf 指向的缓冲区中。如果 KFIFO环形缓冲区的数据元素小于 n 个,那么复制出去的数据元素小于 n 个。
4、获取缓冲区大小
KFIFO 提供了几个接口函数来查询环形缓冲区的状态。
#define kfifo_size(fifo)
#define kfifo_len(fifo)
#define kfifo_is_empty(fifo)
#define kfifo_is_full(fifo)
kfifo_size()用来获取环形缓冲区的大小,也就是最大可以容纳多少个数据元素。 kfifo_len()用来获取当前环形缓冲区中有多少个有效数据元素。
kfifo_is_empty()判断环形缓冲区是否为空。
kfifo_is_full()判断环形缓冲区是否为满。
5、与用户空间数据交互
KFIFO 还封装了两个函数与用户空间数据交互。
#define kfifo_from_user(fifo, from, len, copied)
#define kfifo_to_user(fifo, to, len, copied)
kfifo_from_user()是把 from 指向的用户空间的 len 个数据元素复制到 KFIFO 中,最后一个参数 copied 表示成功复制了几个数据元素。 kfifo_to_user()则相反,把 KFIFO 的数据元素复制到用户空间。这两个宏结合了 copy_to_user()、 copy_from_user()以及 KFIFO 的机制,给驱动开发者提供了方便。

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









