







 本文介绍了频繁模式挖掘的基础概念,包括支持度、置信度和提升度,并通过一个具体的例题详细阐述了这些概念的应用。例题中探讨了{香蕉,可乐}的关联规则,分析了它们的支持度、置信度和是否构成强规则。
本文介绍了频繁模式挖掘的基础概念,包括支持度、置信度和提升度,并通过一个具体的例题详细阐述了这些概念的应用。例题中探讨了{香蕉,可乐}的关联规则,分析了它们的支持度、置信度和是否构成强规则。
频繁模式挖掘 (Frequent pattern mining) 从交易及关系数据库中发现条目集中的关联关系。
此方法的
假设是数据项目 (data item) 被组合为交易 (transactions),也叫项目集 (itemsets)。
目标是发现在交易中占比较高的项目的模式。
最
经典的案例是耳熟能详的啤酒和尿布的故事。数据分析人员从数据中发现购买了尿布的客户也倾向于同时买啤酒,基于这个发现 (知识),超级市场有两种可能的选择,一是将啤酒和尿布放在一起,从而客户可以方便地一起购买;另一个选择是将啤酒和尿布尽量分开,客户为了买到两样商品需要走过更多的货架,从而增加购买其他商品的机会。如何设计业务方案 (actions) 是一个问题,因为只有将知识应用于业务后才可以真正产生价值,因此这个环节从某种角度讲更重要,也更考验数据分析人员,因为你的客户总是会问,“那么我能做什么呢”。
目前,频繁模式挖掘的
应用场景包括购物篮分析,交叉营销,目录设计,销售活动分析,网络点击流分析,以及DNA序列分析等等。
下面列出关联关系挖掘涉及到的基本概念 (concepts) 和表示方法 (notation)。
1 项目 (item) : 举例来说,对于购物行为的分析,苹果、牛奶和面包就是项目。
2 项目集 (itemset):一个或者多个项目的集合,用
 来表示。
来表示。
举例来说,{苹果,牛奶,面包} 是一个项目集。
3 k-项目集 (k-itemset), k是一个正整数,是项目集的势,简单来说,就是项目集中项目的数量,比如{苹果,牛奶,面包} 是一个 3-项目集。
4 交易 (transaction):一个非空的项目集,拥有一个唯一的标识 (TID),并属于一个数据库。记为
 ,其中
,其中
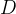 是一个与交易相关的交易集,也叫数据集或者数据库。
是一个与交易相关的交易集,也叫数据集或者数据库。
举例来说,
 , 其中
, 其中
 {苹果,牛奶,面包},
{苹果,牛奶,面包},
 {方便面,拖鞋}。
{方便面,拖鞋}。
5 包含 (contain):假设
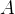 和
和
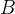 是两个项目集,
是两个项目集,
 且
且
 。如果
。如果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









