




概述
一个开源的支持高并发的高性能大模型推理引擎。在这篇博客有简单提到过。
modelscope
通过vLLM(或其他平台、框架)部署模型前,需要先下载模型。国内一般使用魔搭社区,模型库里搜索想要下载的模型。输入qwen3会看到很多个候选项,主要是:
- 参数量不一致;
- 量化版本不一致;
- 提交者不一致。
总之,找到模型下载路径(/Qwen/Qwen3-30B-A3B)是需要花点时间的。
下载模型有多种方式:
- 通过浏览器下载:打开魔搭页面,默认下载到
C:\Users\johnny\Downloads目录下。模型文件通常非常大,如Qwen3-30B-A3B-FP8,分割为7个文件共30+G。Chrome下载效果如下,不便之处在于文件名可辨识度非常低,最后极有可能不知道下载下来的是哪个模型的子文件。而且这么做,也不太专业。
- 通过命令行下载:在有Python和pip的环境下,
pip install modelscope安装modelscope。使用modelscope命令行下载,如下载reranker模型:modelscope download --model BAAI/bge-reranker-v2-m3 --local_dir /home/models/BAAI/bge-reranker-v2-m3。 - 通过客户端下载:
vim ms_download.py,填入如下内容
from modelscope import snapshot_download
import os
os.environ['HTTP_PROXY'] = 'http://192.168.4.123:7890'
os.environ['HTTPS_PROXY'] = 'http://192.168.4.123:7890'
model_dir = snapshot_download('JunHowie/Qwen3-30B-A3B-GPTQ-Int8')
embedding
使用BAAI提供的模型,docker启动命令(一行):
docker run --name=embedding --volume /home/models:/home/models --network=host --workdir=/ --restart=unless-stopped --runtime=nvidia --detach=true docker.1ms.run/dustynv/vllm:0.7.4-r36.4.0-cu128-24.04 python3 -m vllm.entrypoints.openai.api_server --served-model-name BAAI/bge-m3 --task embedding --enable-prefix-caching --model /home/models/BAAI/bge-m3 --host 0.0.0.0 --port 8001 --trust-remote-code
docker logs -f <container_id>查看日志:
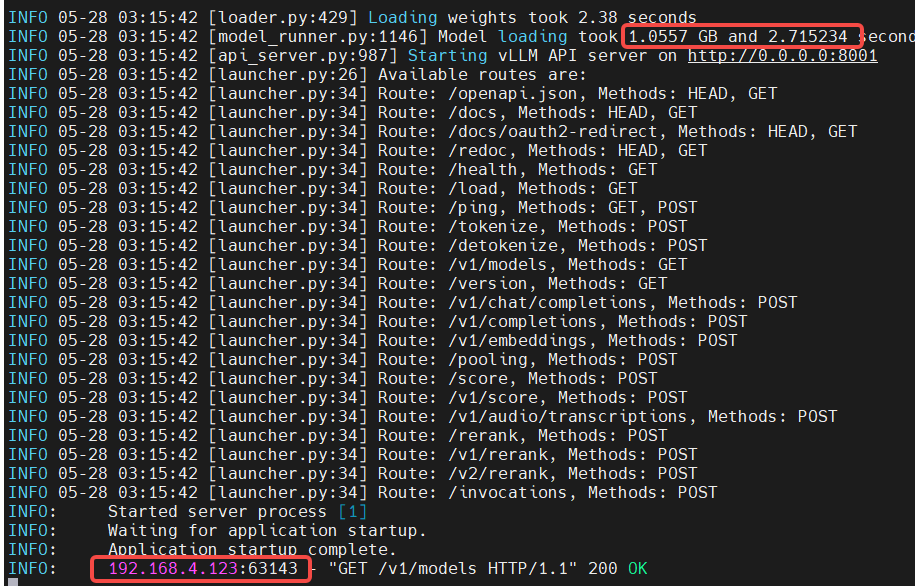
实际上,上述截图还省略掉不少有价值的日志:
- embedding模型只花费2.38s就成功加载权重值,只使用1G内存(显存),这也是被称为小模型的原因,下面的reranker和语音模型也是如此;
- 暴露的端点,即Endpoint,或routes,有很多,不一一列举;
- 端口是8001;本地访问使用
http://0.0.0.0:8001/或http://localhost:8001,同一个局域网访问需要使用固定IP形式:http://192.168.4.134:8001/openapi.json; 192.168.4.123:63143是什么?
curl请求截图:


postman请求接口如下:
一行命令的可视化效果可能不太好,docker启动命令(多行):
docker run -it \
--name=embedding \
--volume /home/models:/home/models \
--network=host \
--workdir=/ \
--restart=unless-stopped \
--runtime=nvidia \
--detach=true \
dustynv/vllm:0.7.4-r36.4.0-cu128-24.04 \
python3 -m vllm.entrypoints.openai.api_server \
--served-model-name BAAI/bge-m3 \
--task embedding \
--enable-prefix-caching \
--model /home/models/BAAI/bge-m3 \
--host 0.0.0.0 \
--port 8001 \
--trust-remote-code
测试
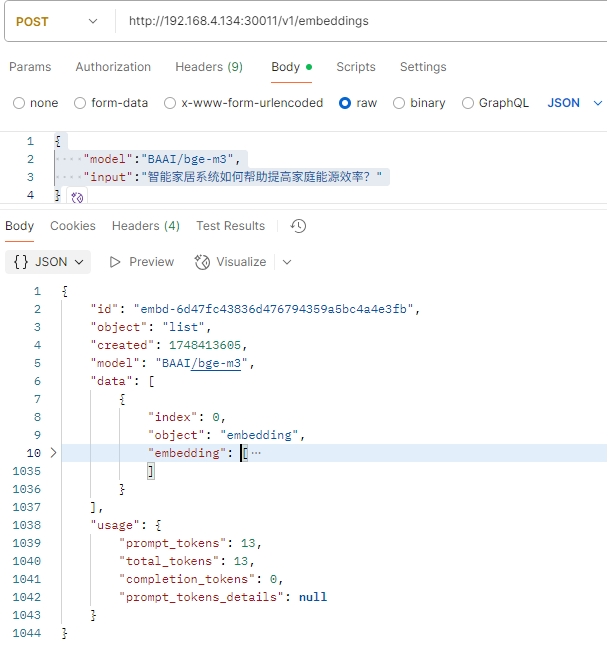
使用postman简单测试,POST请求,requestBody如下:
{
"model":"BAAI/bge-m3",
"input":"智能家居系统如何帮助提高家庭能源效率?"
}
执行效果如下:
使用更加专业的py脚本来执行测试:
import requests
import concurrent.futures
BASE_URL = "http://192.168.4.134:30011"
MODEL = "BAAI/bge-m3"
def create_request_body():
return {
"model": MODEL,
"input": "智能家居系统如何帮助提高家庭能源效率?"
}
def make_request(request_body):
headers = {
"Content-Type": "application/json"
}
response = requests.post(f"{BASE_URL}/v1/embeddings", json=request_body, headers=headers, verify=False)
return response.json()
def parallel_requests(num_requests):
request_body = create_request_body()
with concurrent.futures.ThreadPoolExecutor(max_workers=num_requests) as executor:
futures = [executor.submit(make_request, request_body) for _ in range(num_requests)]
results = [future.result() for future in concurrent.futures.as_completed(futures)]
return results
if __name__ == "__main__":
num_requests = 50 # Example: Set the number of parallel requests
responses = parallel_requests(num_requests)
for i, response in enumerate(responses):
print(f"Response {i+1}: {response}")
k8s
上面是使用docker方式启动模型,--restart=unless-stopped参数可以实现自动重启,但是重启(包括探针)机制不如k8s。
将上面的启动脚本扔给GPT,再经过调整,不难得到一个符合k8s或k3s的yaml文件:
# embedding-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-embedding
spec:
replicas: 1
selector:
matchLabels:
app: vllm-embedding
template:
metadata:
labels:
app: vllm-embedding
spec:
nodeSelector:
kubernetes.io/hostname: k3s-master-2
runtimeClassName: nvidia # 需提前配置GPU运行时
containers:
- name: vllm-embedding
image: dustynv/vllm:0.7.4-r36.4.0-cu128-24.04
command: ["python3"]
args:
- "-m"
- "vllm.entrypoints.openai.api_server"
- "--served-model-name"
- "BAAI/bge-m3"
- "--task"
- "embedding" # 关键参数:指定任务类型
- "--enable-prefix-caching"
- "--model"
- "/home/models/BAAI/bge-m3"
- "--host"
- "0.0.0.0"
- "--port"
- "8011"
- "--trust-remote-code"
volumeMounts:
- name: model-storage
mountPath: /home/models
startupProbe:
httpGet:
path: /health
port: 8011
initialDelaySeconds: 120
periodSeconds: 10
failureThreshold: 3
livenessProbe:
httpGet:
path: /health
port: 8011
initialDelaySeconds: 90
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /health
port: 8011
initialDelaySeconds: 90
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 1
volumes:
- name: model-storage
hostPath:
path: /home/models # 主机模型存储路径
---
# embedding-service.yaml
apiVersion: v1
kind: Service
metadata:
name: vllm-embedding-service
spec:
selector:
app: vllm-embedding
ports:
- protocol: TCP
port: 8011 # 集群内部访问端口
targetPort: 8011 # 容器端口
nodePort: 30011
type: NodePort # 外部访问方式
reranker
与embedding经常一起出现的就是重排序,即reranker小模型。魔搭社区地址,一般用BAAI/bge-reranker-v2-m3
直接给出docker启动模型命令:
docker run -it --name=rerank --volume /home/models:/home/models --network=host --workdir=/ --restart=unless-stopped --runtime=nvidia --detach=true dustynv/vllm:0.7.4-r36.4.0-cu128-24.04 python3 -m vllm.entrypoints.openai.api_server --served-model-name BAAI/bge-reranker-v2-m3 --enable-prefix-caching --model /home/models/BAAI/bge-reranker-v2-m3 --host 0.0.0.0 --port 8002 --trust-remote-code
转化为k3s或k8s的yaml文件也很简单,将上面的embedding模型的yaml文件稍加改动即可。
语音
魔搭社区地址为iic/SenseVoiceSmall。启动SenseVoiceSmall模型的镜像不是vLLM,需要自己构建Docker镜像。如果转换为k3s yaml文件,则还需要将Docker镜像转化成crictl镜像。具体参考docker、ctr、crictl命令简介与使用。
qwen2.5
部署的模型为DeepSeek-R1-Distill-Qwen-32B-AWQ,魔搭社区地址为Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ。
Docker启动模型的命令为:
docker run -d --name=qwen-32b --hostname=ubuntu --workdir=/ --restart unless-stopped --runtime nvidia --detach=true -v /home/models:/models --network host dustynv/vllm:0.7.4-r36.4.0-cu128-24.04 python -m vllm.entrypoints.openai.api_server --served-model-name deepseek-r1-distill-qwen-32b-awq --model "/models/deepseek-r1-32b" --gpu-memory-utilization 0.6 --host 0.0.0.0 --port 8000 --tensor-parallel-size 1 --max-model-len 32768 --max-num-seqs 8
Docker命令转换成k3s的yaml文件不难:
# deepseek-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-r1-worker
spec:
replicas: 1
selector:
matchLabels:
app: deepseek-r1-worker
template:
metadata:
labels:
app: deepseek-r1-worker
# 负载均衡
service: deepseek-r1-distill
spec:
nodeSelector:
kubernetes.io/hostname: k3s-worker-3
runtimeClassName: nvidia # 依赖NVIDIA设备插件
containers:
- name: vllm
image: dustynv/vllm:0.7.4-r36.4.0-cu128-24.04
command: ["python"]
args:
- "-m"
- "vllm.entrypoints.openai.api_server"
- "--served-model-name"
- "deepseek-r1-distill-qwen-32b-awq"
- "--model"
- "/home/models/deepseek-r1-32b"
- "--gpu-memory-utilization"
- "0.85" # 调度到32G从节点
- "--max-model-len"
- "8192"
- "--host"
- "0.0.0.0"
- "--port"
- "8010"
volumeMounts:
- name: model-storage
mountPath: /home/models
startupProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 200
periodSeconds: 10
failureThreshold: 3
livenessProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 150
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 150
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 1
volumes:
- name: model-storage
hostPath:
path: /home/models
在使用k3s,需要注意的是:主节点已经crictl pull下载vLLM镜像,通过modelscope download下载过模型文件,在主节点执行k apply -f qwen2.5-worker.yaml文件,希望通过k8s调度到从节点部署;则从节点,也需要对应的镜像文件和crictl镜像。此时通过scp传输应该比下载来得快。
qwen3
Qwen3-30B-A3B
上面部署embedding、reranker、qwen2模型使用的vLLM镜像版本都是dustynv/vllm:0.7.4-r36.4.0-cu128-24.04,继续使用此版本部署qwen3模型,比如没有经过量化的Qwen3-30B-A3B,启动日志里有个报错:

升级使用的vLLM版本到dustynv/vllm:0.8.6-r36.4-cu128-24.04,即可成功部署。启动日志如下:

Qwen3-30B-A3B-GPTQ-Int4
如上截图所示,一个64G显存一体的Jetson Orin GPU卡,部署好Qwen3-30B-A3B模型,已经用去56G显存。那这张卡基本上就不能再部署其他服务或模型。
因此需要考虑部署量化版的Qwen3,在modelscope下载多个不同版本的模型,以及反复试错,解决问题后,成功部署Qwen3-30B-A3B-GPTQ-Int4。
给出yaml文件如下:
# deepseek-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-r1-master
spec:
replicas: 1
selector:
matchLabels:
app: deepseek-r1-master
template:
metadata:
labels:
app: deepseek-r1-master
# 负载均衡配置
service: deepseek-r1-distill
spec:
nodeSelector:
kubernetes.io/hostname: k3s-master-2
runtimeClassName: nvidia # 依赖NVIDIA设备插件
containers:
- name: vllm
image: dustynv/vllm:0.8.6-r36.4-cu128-24.04
command: ["python"]
args:
- "-m"
- "vllm.entrypoints.openai.api_server"
- "--served-model-name"
- "Qwen3-30B-A3B-GPTQ-Int4"
- "--model"
- "/home/models/Qwen/Qwen3-30B-A3B-GPTQ-Int4"
- "--gpu-memory-utilization"
- "0.6" # 调度到64G k3s主节点
# - "0.7" # 调度到32G k3s从节点
- "--max-model-len"
- "8192"
- "--enable-reasoning"
- "--reasoning-parser"
- "deepseek_r1"
- "--host"
- "0.0.0.0"
- "--port"
- "8010"
volumeMounts:
- name: model-storage
mountPath: /home/models
- name: local-py
mountPath: /opt/venv/lib/python3.12/site-packages/vllm/model_executor/layers/quantization/gptq_marlin.py
env:
- name: VLLM_USE_V1
value: "0"
startupProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 500
periodSeconds: 10
failureThreshold: 3
livenessProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 150
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /health
port: 8010
initialDelaySeconds: 150
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 1
volumes:
- name: model-storage
hostPath:
path: /home/models
- name: local-py
hostPath:
path: /home/models/gptq_marlin.py
---
# deepseek-service.yaml
apiVersion: v1
kind: Service
metadata:
name: deepseek-service
spec:
selector:
service: deepseek-r1-distill
ports:
- protocol: TCP
port: 8010 # 集群内部访问端口
targetPort: 8010 # 容器端口
nodePort: 30010
type: NodePort # 外部访问方式或LoadBalancer
其中一个非常关键的配置是本地gptq_marlin.py文件挂载,替换vLLM默认的gptq_marlin.py文件。
其他
日志
vLLM部署Qwen3-30B-A3B-GPTQ-Int4模型的启动日志:
INFO 05-30 11:26:31 [config.py:730] This model supports multiple tasks: {'classify', 'embed', 'generate', 'score', 'reward'}. Defaulting to 'generate'.
INFO 05-30 11:26:33 [gptq_marlin.py:143] The model is convertible to gptq_marlin during runtime. Using gptq_marlin kernel.
INFO 05-30 11:26:33 [api_server.py:246] Started engine process with PID 79
/opt/venv/lib/python3.12/site-packages/transformers/utils/hub.py:105: FutureWarning: Using `TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
warnings.warn(
INFO 05-30 11:26:38 [__init__.py:239] Automatically detected platform cuda.
INFO 05-30 11:26:42 [llm_engine.py:240] Initializing a V0 LLM engine (v0.8.6) with config: model='/home/models/Qwen/Qwen3-30B-A3B', speculative_config=None, tokenizer='/home/models/Qwen/Qwen3-30B-A3B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=8192, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=gptq_marlin, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend='deepseek_r1'), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=Qwen3-30B-A3B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=None, chunked_prefill_enabled=False, use_async_output_proc=True, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=True,
INFO 05-30 11:26:43 [cuda.py:292] Using Flash Attention backend.
[W530 11:26:44.180101328 ProcessGroupNCCL.cpp:959] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
INFO 05-30 11:26:44 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-30 11:26:44 [model_runner.py:1108] Starting to load model /home/models/Qwen/Qwen3-30B-A3B...
WARNING 05-30 11:26:44 [utils.py:168] The model class Qwen3MoeForCausalLM has not defined `packed_modules_mapping`, this may lead to incorrect mapping of quantized or ignored modules
INFO 05-30 11:26:44 [gptq_marlin.py:238] Using MarlinLinearKernel for GPTQMarlinLinearMethod
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:28<00:00, 28.55s/it]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:28<00:00, 28.55s/it]
INFO 05-30 11:27:15 [loader.py:458] Loading weights took 28.98 seconds
INFO 05-30 11:27:20 [model_runner.py:1140] Model loading took 15.6069 GiB and 36.310342 seconds
WARNING 05-30 11:27:21 [fused_moe.py:668] Using default MoE config. Performance might be sub-optimal! Config file not found at /opt/venv/lib/python3.12/site-packages/vllm/model_executor/layers/fused_moe/configs/E=128,N=4096,device_name=Orin_(nvgpu).json
INFO 05-30 11:27:25 [worker.py:287] Memory profiling takes 4.08 seconds
INFO 05-30 11:27:25 [worker.py:287] the current vLLM instance can use total_gpu_memory (61.37GiB) x gpu_memory_utilization (0.60) = 36.82GiB
INFO 05-30 11:27:25 [worker.py:287] model weights take 15.61GiB; non_torch_memory takes -4.03GiB; PyTorch activation peak memory takes 1.42GiB; the rest of the memory reserved for KV Cache is 23.83GiB.
INFO 05-30 11:27:25 [executor_base.py:112] # cuda blocks: 16267, # CPU blocks: 2730
INFO 05-30 11:27:25 [executor_base.py:117] Maximum concurrency for 8192 tokens per request: 31.77x
INFO 05-30 11:27:32 [model_runner.py:1450] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:38<00:00, 1.11s/it]
INFO 05-30 11:28:11 [model_runner.py:1592] Graph capturing finished in 39 secs, took 0.66 GiB
INFO 05-30 11:28:11 [llm_engine.py:437] init engine (profile, create kv cache, warmup model) took 50.42 seconds
WARNING 05-30 11:28:11 [config.py:1252] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 05-30 11:28:11 [serving_chat.py:118] Using default chat sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-30 11:28:11 [serving_completion.py:61] Using default completion sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
显存利用
其中有一段值得深扒:
INFO 05-30 11:27:25 [worker.py:287] the current vLLM instance can use total_gpu_memory (61.37GiB) x gpu_memory_utilization (0.60) = 36.82GiB
INFO 05-30 11:27:25 [worker.py:287] model weights take 15.61GiB; non_torch_memory takes -4.03GiB; PyTorch activation peak memory takes 1.42GiB; the rest of the memory reserved for KV Cache is 23.83GiB.
注意到non_torch_memory使用的内存是负数。
GPT解读:
在vLLM的资源分配逻辑中,内存使用被分为几个部分:
| 内存类型 | 含义 |
|---|---|
| model weights | 模型权重占用的显存(通常为FP16或INT8 |
| non_torch_memory | 非PyTorch分配器管理的显存,如CUDA内存池、自定义内存等 |
| PyTorch activation peak memory | PyTorch激活函数使用的峰值内存(启用PyTorch backend) |
| KV Cache | 用于缓存attention key/value的内存 |
这些加起来应该小于等于总的可用显存 × 利用率:
total_gpu_memory * gpu_memory_utilization = model_weights + non_torch_memory + pytorch_activation + kv_cache
出现负数的可能原因:
- 数值溢出或精度误差:这些值可能是从GPU显存总量中减去其他已知项推导出来的;
- 估算方式不够严谨,或某些值过大,可能导致结果为负数。
原因:
- 模型太大:模型本身权重就很大,如Qwen3-30B;
- 配置不合理:设置较高的
max_num_seqs或max_seq_len,会导致KV Cache需求激增;加上一些激活内存开销,整体显存需求超过预留的60%,从而导致non_torch_memory被迫为负。
但是!!!
- 显存大小相同的两张Jetson Orin卡,都是64G;
- 都是Qwen3-30B-A3B-GPTQ-Int4模型;
--gpu-memory-utilization参数都是0.6。
一张卡是正数。另一张卡出现上述负数,第一次部署模型时,内存异常,触发pod重启,此时free -h查看剩余显存不够300M;
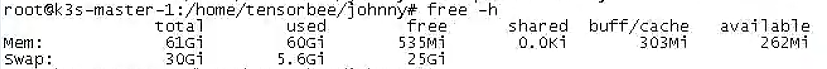
pod重启日志里该参数还是负数,等待pod启动成功,free -h查看剩余显存有1~2G。
杀掉进程,重新部署模型,还是负数。
作为TODO有待后续跟进的2个问题:
- 为啥是负数?
- 这个负数的绝对值大小有什么学问,也就是为啥第一次会触发pod异常重启?


















 5937
5937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











