






朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
朴素贝叶斯法的重点知识与思考(慢慢补充)
- 贝叶斯定理
- 先验概率、类条件概率、后验概率的含义
- 为什么要做条件独立性假设?
- 贝叶斯法分类的基本公式推导
- 后验概率最大化公式的推导
- 极大似然估计(先验概率的极大似然估计公式的推导)
- 为什么用极大似然估计可能会出现所要估计的概率值为0的情况
- 贝叶斯估计(先验概率和条件概率的贝叶斯估计公式推导)
1、贝叶斯定理
, 换个表达式容易理解一点
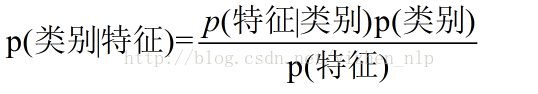
加深理解:
可以站在A的角度去看B,也可以站在B的角度去看A。 他们看到的事实应该是一致的。
(图片来源:https://www.zhihu.com/question/21134457)
假设需对n个类别进行分类,按照贝叶斯公式:
2、先验概率、类条件概率、后验概率的含义
P(Y):为先验概率,表示每种类别分布的概率;
P(X|Y):类条件概率,表示在某种类别前提下,某事件发生的概率;
P(X):后验概率,表示某事发生了,并且它属于某一类别的概率,有了后验概率,便可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,便越有理由把它归到这个类别下。
3、为什么要做条件独立性假设?
答:为了简化计算。在现实生活中,往往有非常多的特征,每一个特征的取值也是非常之多,那么通过统计来估计后面概率的值,变得几乎不可做,这也是为什么需要假设特征之间独立的原因。
5、后验概率最大化的推导
首先贝叶斯分类实例的属性可以是离散的,连续的,也可以使混合的。(应该是,忘记在哪里看到的)
朴素贝叶斯法将实例分到后验概率最大的类中。后验概率最大化公式推导:


6、极大似然估计
对于这个函数:P(x|θ) 输入有两个:x表示某一个具体的数据;θ表示模型的参数。
如果θ是已知确定的,x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
如果x是已知确定的,θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
(详解极大似然估计与后验概率最大化:https://blog.csdn.net/u011508640/article/details/72815981)
极大似然估计,就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值(模型已知,参数未知)。
极大似然估计:现在已经拿到了很多个样本(你的数据集中所有因变量),这些样本值已经实现,最大似然估计就是去找到那个(组)参数估计值,使得前面已经实现的样本值发生概率最大。因为你手头上的样本已经实现了,其发生概率最大才符合逻辑。这时是求样本所有观测的联合概率最大化,是个连乘积,只要取对数,就变成了线性加总。此时通过对参数求导数,并令一阶导数为零,就可以通过解方程(组),得到最大似然估计值。
(来源:https://www.zhihu.com/question/20447622/answer/23902715)
所以求解极大似然估计的步骤为:
- 写出似然函数(目的是求出最大的概率p)
- 对似然函数取对数(why?因为对数ln把乘法变成加法,并且不改变极值的位置(单调性保持一致),这样求导方便)
- 求导数(求导过程就是求极值的过程)
- 解似然函数
先验概率的极大似然估计公式的推导:(李航《统计学习方法》P62)


7、为什么用极大似然估计可能会出现所要估计的概率值为0的情况?
答:假如所给定实例的元素取值在样本中不存在,即在训练集中未出现元素的一个取值,而在测试实例中出现了该取值,

8、贝叶斯估计(先验概率的贝叶斯估计公式推导)
李航《统计学习方法》P64,4.11,先验概率的贝叶斯估计公式推导:

(4.10)条件概率的贝叶斯估计公式推导
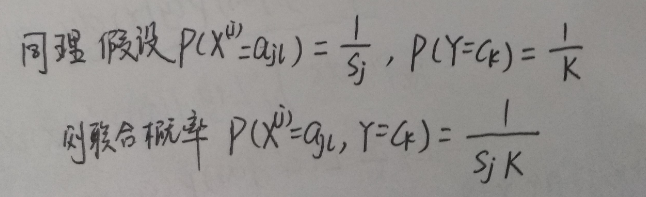

式中K为所要分类的训练样本的类别个数,,是一个引入的变量,等价于在统计的频数上赋予一个正数。
式中Sj 是样本点每个元素可能取值集合的个数。















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









