









EAST简介
EAST是一个文本检测模型,由于他的实现方式非常简洁且高效,所以吸引了很多人用他的方法做文本检测,具体实现方法已经有很多人讲过,下面将记录一下其中的具体代码处理过程。
EAST论文地址:https://arxiv.org/pdf/1704.03155.pdf
EAST代码复现:https://github.com/argman/EAST
一、图像预处理
# 读取图片
im_fn = image_list[i]
im = cv2.imread(im_fn)
h, w, _ = im.shape
# 读取标签txt
label_name = os.path.splitext(os.path.basename(im_fn))[0]
label_dir = os.path.join(data_dir, "labels")
txt_fn = os.path.join(label_dir,label_name+".txt")
text_polys, text_tags = load_annoataion(txt_fn) # 获取点的位置和内容信息
#保证框在图里
text_polys, text_tags = check_and_validate_polys(text_polys, text_tags, (h, w))
然后图像根据 background_ratio 分流,切一部分带文字的当前景,切不带文字的当背景
if np.random.rand() < background_ratio: #这些图当背景
im, text_polys, text_tags = crop_area(im, text_polys, text_tags, crop_background=True)
......#一系列背景处理
else: #当前景
#切出的图如果带框,就当前景,数据增强的一种
im, text_polys, text_tags = crop_area(im, text_polys, text_tags, crop_background=True)
score_map, geo_map, training_mask = generate_rbox((new_h, new_w), text_polys, text_tags)
......
geo_map是最复杂的,具体格式如下图,对于0,1,2这每一个像素,都有5个值,ABCDE,分别代表像素点到框的上、下、左、右、框倾斜角度这五个值。包括d的4层和e的1层

具体矩阵如下图所示,

二、模型训练
1)前向计算
EAST的模型,代码中用的是ResNet50 + 多分支预测 的架构,论文中如下图所示

代码中具体像素如下:
然后用这个预测结果与前面标注的score_map, geo_map,结果进行对比,算loss,然后反向传播优化,最终得到一个好的模型。
Loss 计算
Loss的计算,根据论文分为2部分,包括score_map的loss和像素框geo_map的loss

其中:score_loss在代码中使用了dice_lose


classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask)
# 其中,dice_lose 是
def dice_coefficient(y_true_cls, y_pred_cls,training_mask):
import numpy as np
np.random.normal()
'''
dice loss
coeff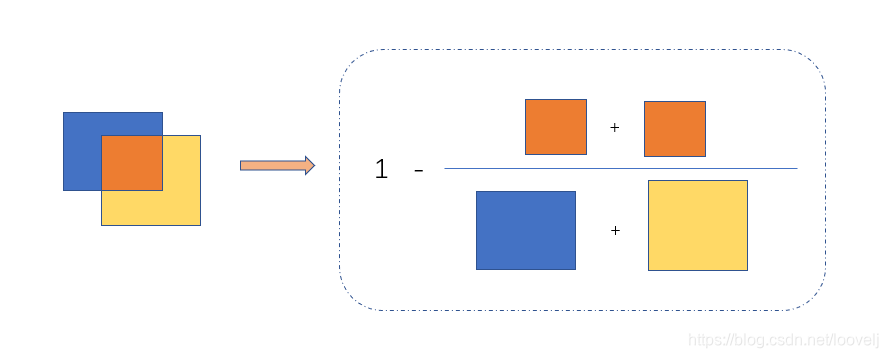
icient:协同因素
:param y_true_cls: 是一个1/0图
:param y_pred_cls: 是一个概率图,每个像素是一个0~1之间的概率值
:param training_mask:
:return:
'''
eps = 1e-5 #0.00001
# reduce_sum是压缩求和,得到一个标量
intersection = tf.reduce_sum(y_true_cls * y_pred_cls * training_mask) # training_mask都是1,只有文字框小的,模糊的会被屏蔽掉
union = tf.reduce_sum(y_true_cls * training_mask) + \
tf.reduce_sum(y_pred_cls * training_mask) + \
eps
loss = 1. - (2 * intersection / union) # loss在[-1,1]之间
tf.summary.scalar('classification_dice_loss', loss)
return loss
这是Lg的loss,就是如下公式

用图像表示如下:

三、前向推理
推理图像,首先resize到固定的32倍数的大小,如512/720等像素。经过模型后获得 score_map 和geo_map,通过这些信息,先推理出所有的矩形框,
正向预测图像:
(1)根据点到四边的距离,计算一个矩形
(2)根据角度旋转矩形
(3)根据中心点位置,移动到相应的位置

Locality-Aware NMS
局部感知NMS,这个主要就是将相近的先通过权重融合到一起,而不是直接去除,这样省了很多计算量,其中最关键的是:
def weighted_merge(g, p):
# 取g,p两个几何体的加权(权重根据对应的检测得分计算得到)
g[:8] = (g[8] * g[:8] + p[8] * p[:8])/(g[8] + p[8])
#合并后的几何体的得分为两个几何体得分的总和
g[8] = (g[8] + p[8])
return g
总结:
相比于其他框架,这个简单粗暴,单效果还挺好,除了长文本和弯曲文本,对于普通的短文本非常合适,快而且准确,是非常好的文本检测模型。其中,看源码也有很大的启发,里面很多numpy函数、tf1.x时代的多gpu训练函数等,体现了argman扎实的编程基础,每次读源码都有收获。为这位大神点赞
参考文档:
1、https://github.com/argman/EAST #原始注释
2、https://github.com/zyh8306/EAST #这个代码注释详细、幽默,强烈推荐
3、EAST源码解析
4、【OCR实践系列】EAST理解及实现
5、Dice_Loss简介
6、EAST讲解 求面积的动图很好
7、目标检测之非极大值抑制(NMS)各种变体
8、知乎上EAST讲解
9、目标检测之非极大值抑制(NMS)各种变体















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









