







GPU环境的配置
在深度学习中,模型往往很复杂,数据量很大,此时使用GPU运行会快很多。而使用GPU就需要安装CUDA和CuDNN。本文是为了使用tensorflow的gpu版本而使用的GPU。(1)GPU的配置
首先,要使用TensorFlow的GPU,需要达到的硬件前提:显卡类型是NVIDIA,显卡的计算能力要至少达到3.0。 可以在下面的网站查看: https://developer.nvidia.com/cuda-gpus然后,下载CUDA和CuDNN
CuDA至少8.0,CuDNN至少6.1
CuDA的下载网址:
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exelocal
CuDNN的下载网址:
https://developer.nvidia.com/rdp/cudnn-download
注:CuDNN版本和CUDA的版本要对应上
我使用的是CUDA 8.0和CuDnn v7


Cudnn在官网下载后,直接解压即可,当中会有如下文件:
主要要注意的是CUDA的安装:
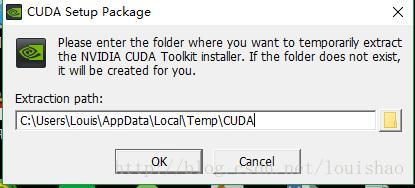
双击安装的cuda_8.0.44.exe后,出现
类似上图的画面,这个是CUDA安装包提取的路径,感觉没有什么意义,而且最终cuda的安装路径也不一定是这里(为什么说不一定,请继续看下去)
点击“OK”之后,经过一个进度条,之后会对系统进行检测。
正式到了安装的时候,建议选择“高级 - 自定义”。之后,都使用默认的选项,一直下一步,最后直到安装完成。
如果选择的是“精装”,后面的安装过程直接就会把CUDA安装在上面的默认路径中;
如果选择“自定义”,后面也是可以自定义路径的,但是这样的话,CUDA可能不会自动配置好系统路径。
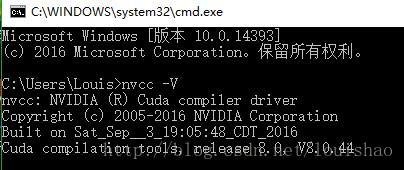
当安装CUDA之后,可以在控制台中输入: nvcc -V查看cuda的版本,如下图:
同时,环境变量中会多出两个路径,即:CUDA_PATH和CUDA_PATH_V8.0
如下图所示:
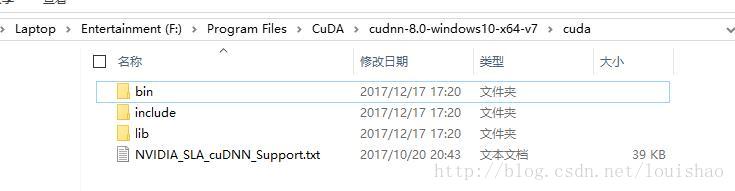

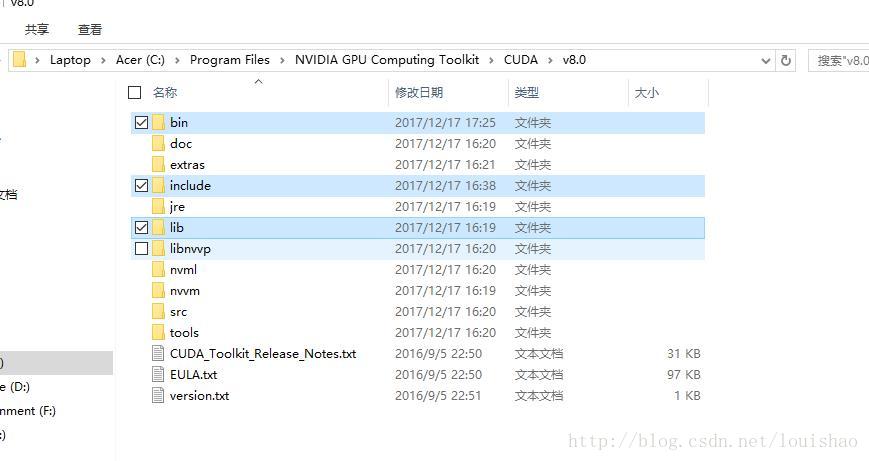
之后,将解压后的Cudnn文件夹中的bin、include和lib文件夹复制到下图所示的文件夹中:
还要在PATH中,添加

至此,CUDA和CuDNN的配置已完成
(2)Python中TensorFlow-gpu的安装
本机的环境:Python 3.5当然,最好还是使用Anconda(包含Python3.6),去安装TensorFlow。
安装TensorFlow的gpu版本,只需要体格命令:
pip install tensorflow-gpu
安装完成后,在控制台中输入python,进入python环境
输入:
import tensorflow as tf
结果显示,一大堆错误,形如:
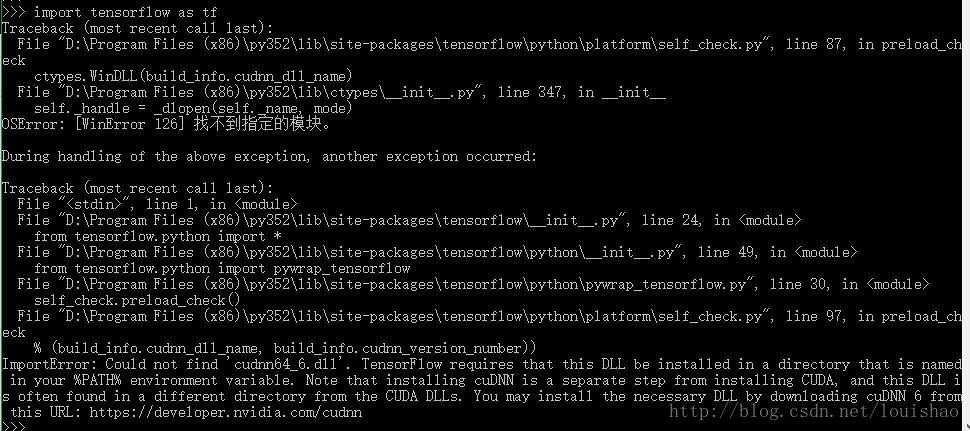
这个主要错误,就是找不到cudnn64_6.dll
解决问题:在下载Cudnn的时候,下载v6版本的CuDnn;如果下载了比v6更新的版本的,直接在修改,如下图所示:
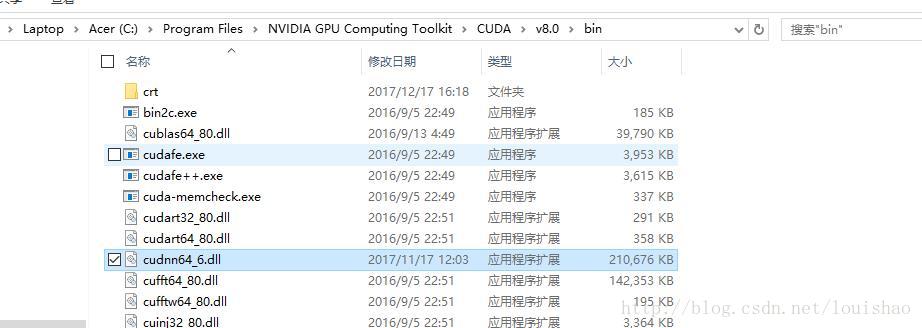
将cudnn64_7改为cudnn64_6即可,注意高版本的可以直接修改为低版本的,但是反之则不行!
此时,再次输入:
import tensorflow as tf
则没有报错
再对tf.Session()进行测试
输入:
sess = tf.Session()
a = tf.constant(2)
b = tf.constant(3)
print(sess.run(a+b))
TensorFlow会自己调用空闲的GPU,而且会显示GPU的信息
同时,可以输入
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
这个可以查看自己显卡的计算能力,和TensorFlow要求的计算能力,如果达不到,则同样起不了GPU加速的作用。

















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









