







文章目录
项目说明
数据集说明
GTSRB : The German Traffic Sign Recognition Benchmark
德国交通标志基准测试是在2011年国际神经网络联合会议(IJCNN)上举行的多类,单图像分类挑战。
GTSRB 包含 43类交通信号,切分为训练图片 39,209张 和 测试图片 12,630 张;
- ModelWhale 数据下载:
https://www.heywhale.com/mw/dataset/5d8db5ca037db3002d3a5ba0 - paperswithcode.com 数据描述
https://paperswithcode.com/dataset/gtsrb
你也可以使用pytorch 下载数据:torchvision.datasets.GTSRB
https://pytorch.org/vision/stable/generated/torchvision.datasets.GTSRB.html
语法:
torchvision.datasets.GTSRB(root: str, split: str = ‘train’, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
数据文件结构
Final_Training
├── Images
├── 00000
│ ├── 00000_00000.ppm
│ ├── 00000_00001.ppm
│ ├── ...
│ ├── 00006_00029.ppm
│ └── GT-00001.csv
├── 00002
│ ├── 00000_00000.ppm
│ ├── 00000_00001.ppm
│ ├── ...
│ ├── 00006_00029.ppm
│ └── GT-00002.csv
├── ...
└── 00042
├── 00000_00000.ppm
├── 00000_00001.ppm
├── ...
├── 00006_00029.ppm
└── GT-00042.csv
GT-000**.csv 文件内容如下:
| Filename | Width | Height | Roi.X1 | Roi.Y1 | Roi.X2 | Roi.Y2 | ClassId |
|---|---|---|---|---|---|---|---|
| 00000_00000.ppm | 29 | 30 | 5 | 6 | 24 | 25 | 0 |
| 00000_00001.ppm | 30 | 30 | 5 | 5 | 25 | 25 | 0 |
| 00000_00002.ppm | 30 | 30 | 5 | 5 | 25 | 25 | 0 |
| 00000_00003.ppm | 31 | 31 | 5 | 5 | 26 | 26 | 0 |
代码实现 - 训练四个类别
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2
import seaborn as sns
import shutil
import os
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
from tqdm import tqdm
from pylab import rcParams
from matplotlib import rc
from matplotlib.ticker import MaxNLocator
from pathlib import Path
from glob import glob
from PIL import Image
from collections import defaultdict
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from torch.optim import lr_scheduler
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import models
from torch import nn, optim
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#93D30C", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 12, 8
RANDOM_SEED = 666
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
device = torch.device("cuda" if torch.cuda.is_available() else torch.device("cpu"))
加载数据
Train_Path = 'GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/*'
Test_Path = 'GTSRB_Final_Test_Images/GTSRB/Final_Test/Images/*'
# 训练集文件夹
train_folders = sorted(glob(Train_Path))
# 测试集文件
test_files = sorted(glob(Test_Path))
len(train_folders) # 43
len(test_files) # 12631
# 函数:根据路径,加载图片
def load_image(img_path, resize=True):
img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2BGRA) # 读取图片,并进行灰度转换
if resize:
img = cv2.resize(img, (64, 64)) # 改变图片尺寸大小
return img
# 函数:显示图片
def show_img(img_path):
img = load_image(img_path) # 调用函数
plt.imshow(img) # 显示
plt.axis('off') # 关闭坐标轴
# 函数:显示一批图片(一个网格所包含的图片)
def show_imgs_grid(img_paths):
"""
img_paths : 很多图片的路径
"""
images = [load_image(path) for path in img_paths] # 根据路径,读取一批图片
print("images length : ", len(images))
images = torch.as_tensor(images) # list类型转换为tensor类型
print("images shape : ", images.shape)
images = images.permute(0, 3, 1, 2) # 维度换位
print("维度变换后的images shape : ", images.shape)
grid_imgs = torchvision.utils.make_grid(images, nrow=8) # 将若干幅图像拼成一幅图像
plt.figure(figsize=(24, 12)) # 画布大小
print("grid_imgs shape : ", grid_imgs.shape)
plt.imshow(grid_imgs.permute(1, 2, 0)) # 维度交换
plt.axis('off') # 关闭坐标轴
# 依次从43个文件夹中,从每个文件夹中,随机获取一张图片的路径
sample_images = [np.random.choice(glob(f'{file_name}/*ppm')) for file_name in train_folders]
sample_images[0] # 第一张图片的路径
# 'GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00000/00003_00019.ppm'
# 显示第一张图片
show_img(sample_images[0])

# 显示这批图片
show_imgs_grid(sample_images)
images length : 43
images shape : torch.Size([43, 64, 64, 4])
维度变换后的images shape : torch.Size([43, 4, 64, 64])
grid_imgs shape : torch.Size([4, 398, 530])

# 类别名称
class_names = ['STOP', '禁止通行', '直行', '环岛行驶']
# 类别对应的文件夹序号: 00014, 00017, 00035, 00040
class_indices = [14, 17, 35, 40]
拆分数据集
# 新建目录,将原始的train数据集分割成:train, val, test, 比例是70%, 20%, 10%
DATA_DIR = Path('New_Data_4_classes')
DATASETS = ['train', 'val', 'test']
for dt in DATASETS:
for cls in class_names:
(DATA_DIR/dt/cls).mkdir(parents=True, exist_ok=True) # exist_ok为True,则在目标目录已存在的情况下不会触发FileExistsError异常
# 从原始数据集拷贝图片到目标文件夹
for i, cls_index in enumerate(class_indices):
image_paths = np.array(glob(f'{train_folders[int(cls_index)]}/*.ppm')) # 标签对应的所有图片路径
class_name = class_names[i] # 标签
print(f'{class_name} : {len(image_paths)}')
np.random.shuffle(image_paths) # 打乱图片路径
# 数据集切分,train : 70%, val : 20%, test : 10%
# 本质上是索引切分
ds_split = np.split(
image_paths,
indices_or_sections=[int(0.7*len(image_paths)), int(0.9*len(image_paths))]
)
# 拼接
dataset = zip(DATASETS, ds_split)
for dt, img_pathes in dataset:
print(f'{dt}, {len(img_pathes)}')
for path in img_pathes:
# 拷贝图片
shutil.copy(path, f'{DATA_DIR}/{dt}/{class_name}/')
STOP : 780
train, 546
val, 156
test, 78
禁止通行 : 1110
train, 777
val, 222
test, 111
直行 : 1200
train, 840
val, 240
test, 120
环岛行驶 : 360
train, 251
val, 73
test, 36
数据增强
- 本数据集比较小,很多类别中,图片才只有几百张;图片识别每个类别能达到 1w 以上比较保险。
mean_nums = [0.485, 0.456, 0.406]
std_nums = [0.229, 0.224, 0.225]
transform = {
'train':transforms.Compose([
transforms.RandomResizedCrop(size=256), # 随机裁剪
transforms.RandomRotation(degrees=15), # 随机旋转
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为tensor
]),
'val':transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
]),
'test':transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
])
}
# 定义数据加载器(ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名)
Image_datasets = {
d : ImageFolder(f'{DATA_DIR}/{d}', transform[d]) for d in DATASETS
}
# 批数据读取
data_loaders = {
d : DataLoader(Image_datasets[d], batch_size=8, shuffle=True, num_workers=12, pin_memory=True)
for d in DATASETS
}
# 统计train, val, test 数据集大小
dataset_size = {d : len(Image_datasets[d]) for d in DATASETS}
{'train': 2414, 'val': 691, 'test': 345}
# 查看train的类别
class_names = Image_datasets['train'].classes
# ['STOP', '环岛行驶', '直行', '禁止通行']
可视化数据增强后的图片
# 可视化显示数据增强后的图片(注意:中文字符显示)
from matplotlib.font_manager import FontProperties
def imshow(inp, title=None):
my_font = FontProperties(fname='SimHei.ttf', size=12)
inp = inp.numpy().transpose((1,2,0)) # 转置
mean = np.array([mean_nums])
std = np.array([std_nums])
inp = std * inp + mean # 还原
inp = np.clip(inp, 0, 1) # 限制像素值在0~1之间
plt.imshow(inp)
if title is not None:
plt.title(title, fontproperties=my_font)
plt.axis('off')
# 获取一批数据
inputs, labels = next(iter(data_loaders['train']))
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in labels])

迁移学习
def create_model(n_classes):
model = models.resnet50(pretrained=True) # 下载预训练模型
# 全连接层输入特征
n_features = model.fc.in_features
# 新的全连接层输入特征
model.fc = nn.Linear(n_features, n_classes)
return model.to(device)
# 创建模型对象
clf_model = create_model(len(class_names))
# clf_model
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=4, bias=True)
)
定义训练函数
def train(model, data_loader, criterion, optimizer, device, scheduler, n_examples):
model.train()
train_loss = []
correct_pred = 0 # 判断正确的图片个数
for inputs, labels in data_loader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 梯度置零
outputs = model(inputs) # 输出
loss = criterion(outputs, labels) # 计算损失
_, preds = torch.max(outputs, dim=1) # 获取到概率最大值的索引
correct_pred += torch.sum(preds == labels) # 累计正确数
train_loss.append(loss.item()) # 累计损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
scheduler.step() # 更新学习率
# 返回平均损失,平均准确率
return np.mean(train_loss), correct_pred.double()/n_examples
定义验证函数
def evaluation(model, data_loader, criterion, device, n_examples):
model.eval()
eval_loss = []
correct_pred = 0
with torch.no_grad():
for inputs, labels in data_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs) #输出
loss = criterion(outputs, labels) # 损失
_, preds = torch.max(outputs, dim=1) # 获取到概率最大值的索引
correct_pred += torch.sum(preds == labels) # 累计正确数
eval_loss.append(loss.item()) # 累计损失
return np.mean(eval_loss), correct_pred.double() / n_examples
开始训练
# 函数:开始训练
def train_model(model, data_loader, dataset_size, device, n_epochs=30):
optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) # 动态学习率
criterion = nn.CrossEntropyLoss().to(device) # 损失函数
# 假设最好的accuracy, history
best_accuracy = 0.0 # 保存历史结果
history = defaultdict(list) # 构建一个默认value为list的字典
for epoch in range(n_epochs):
print(f'\n-- Epoch : {epoch + 1} / {n_epochs}')
train_loss, train_accuracy = train(model, data_loader['train'],
criterion, optimizer, device, scheduler, dataset_size['train'])
print(f'Train Loss : {train_loss}, Train accuracy : {train_accuracy}')
val_loss, val_accuracy = evaluation(model, data_loader['val'], criterion, device, dataset_size['val'])
print(f'Val loss : {val_loss}, val accuracy : {val_accuracy}')
# 保存所有结果
history['train_acc'].append(train_accuracy)
history['train_loss'].append(train_loss)
history['val_acc'].append(val_accuracy)
history['val_loss'].append(val_loss)
if val_accuracy > best_accuracy:
# 保存最佳模型
torch.save(model.state_dict(), 'best_model_state_2.pkl')
# 最好得分
best_accuracy = val_accuracy
print(f'==== Best Accuracy : {best_accuracy}')
# 加载模型
model.load_state_dict(torch.load("best_model_state_2.pkl"))
return model, history
%%time
best_model, history = train_model(clf_model, data_loaders, dataset_size, device)
-- Epoch : 1 / 30
Train Loss : 0.6232142846735306, Train accuracy : 0.7858326429163214
Val loss : 1.1294343096428905, val accuracy : 0.7149059334298118
-- Epoch : 2 / 30
Train Loss : 0.38599158964113683, Train accuracy : 0.8695111847555923
Val loss : 3.4867780328482048, val accuracy : 0.42836468885672935
...
-- Epoch : 29 / 30
Train Loss : 0.05038131698228312, Train accuracy : 0.9817729908864954
Val loss : 5.68476289305294, val accuracy : 0.6439942112879884
-- Epoch : 30 / 30
Train Loss : 0.044309226956246624, Train accuracy : 0.9850869925434962
Val loss : 6.398965428394316, val accuracy : 0.6193921852387844
==== Best Accuracy : 0.8075253256150506
CPU times: user 9min 29s, sys: 2min 49s, total: 12min 19s
Wall time: 12min 4s
绘制 loss, acc
def plot_training_history(history):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 6))
ax1.plot(history['train_loss'], label='train loss')
ax1.plot(history['val_loss'], label='val loss')
ax1.set_ylim([-0.05, 1.05])
ax1.legend()
ax1.set_ylabel('Loss')
ax1.set_xlabel('Epoch')
ax2.plot(history['train_acc'], label='train acc')
ax2.plot(history['val_acc'], label='val acc')
ax2.set_ylim([-0.05, 1.05])
ax2.legend()
ax2.set_ylabel('Accuracy')
ax2.set_xlabel('Epoch')
fig.suptitle('Training History')
plot_training_history(history)
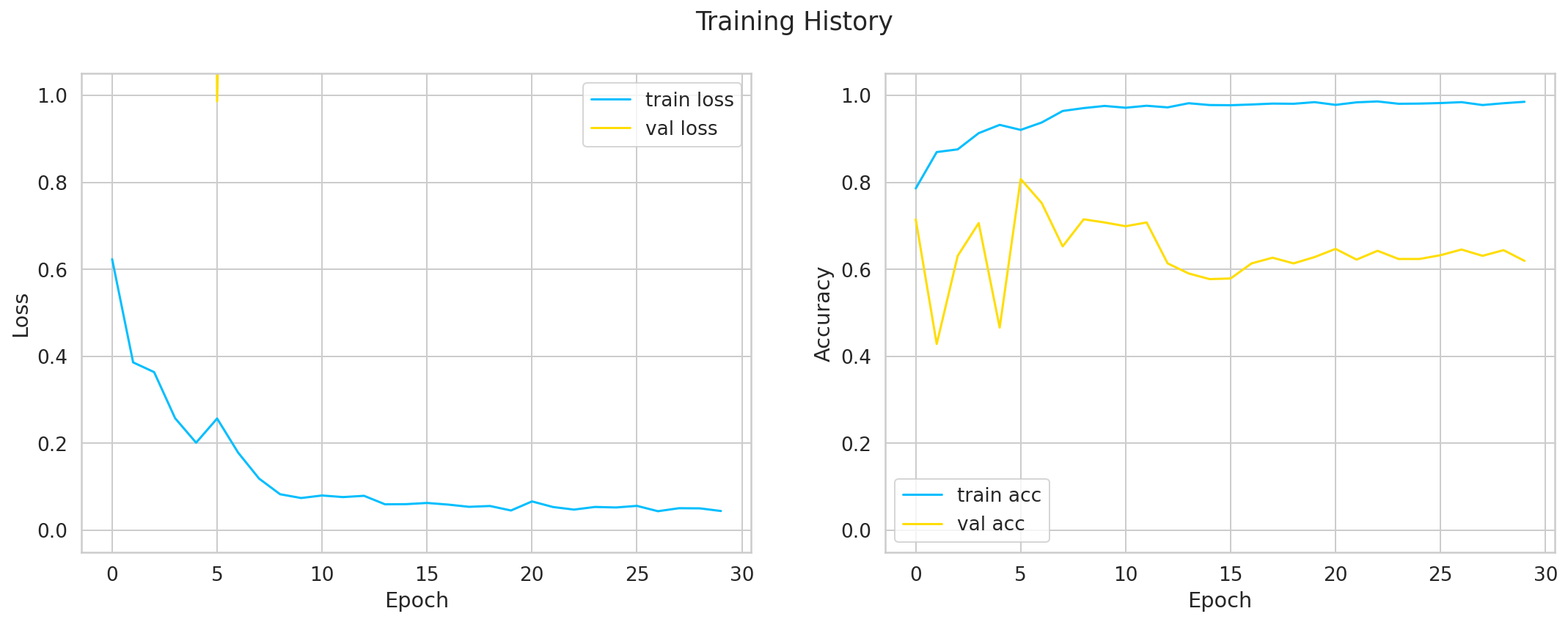
在test集上评估
def show_predictions(model, class_names, n_imgs=6):
model.eval()
images_handled = 0
plt.figure()
with torch.no_grad():
my_font = FontProperties(fname='SimHei.ttf', size=12)
for i, (inputs, labels) in enumerate(data_loaders['test']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, dim=1)
for j in range(inputs.shape[0]):
images_handled += 1
ax = plt.subplot(2, n_imgs // 2, images_handled)
ax.set_title(f'predicted : {class_names[preds[j]]}', fontproperties=my_font)
imshow(inputs.cpu().data[j])
ax.axis('off')
if images_handled == n_imgs:
return
show_predictions(best_model, class_names, n_imgs=8)

根据预测结果,计算统计指标
def get_predictions(model, data_loaders):
model.eval()
predictions = [] # 预测值
real_values = [] # 真值
with torch.no_grad():
for inputs, labels in data_loaders:
inputs = inputs.to(device)
labels = labels.to(device)
# 预测输出
outputs = model(inputs)
# 获取概率最大值索引
_, preds = torch.max(outputs, dim=1)
# 保存预测值和真值
predictions.extend(preds)
real_values.extend(labels)
#print(predictions)
#print(real_values)
# 类型转换
predictions = torch.as_tensor(predictions).cpu()
real_values = torch.as_tensor(real_values).cpu()
return predictions, real_values
y_pred, y_test = get_predictions(best_model, data_loaders['test'])
print(classification_report(y_test, y_pred, target_names=class_names))
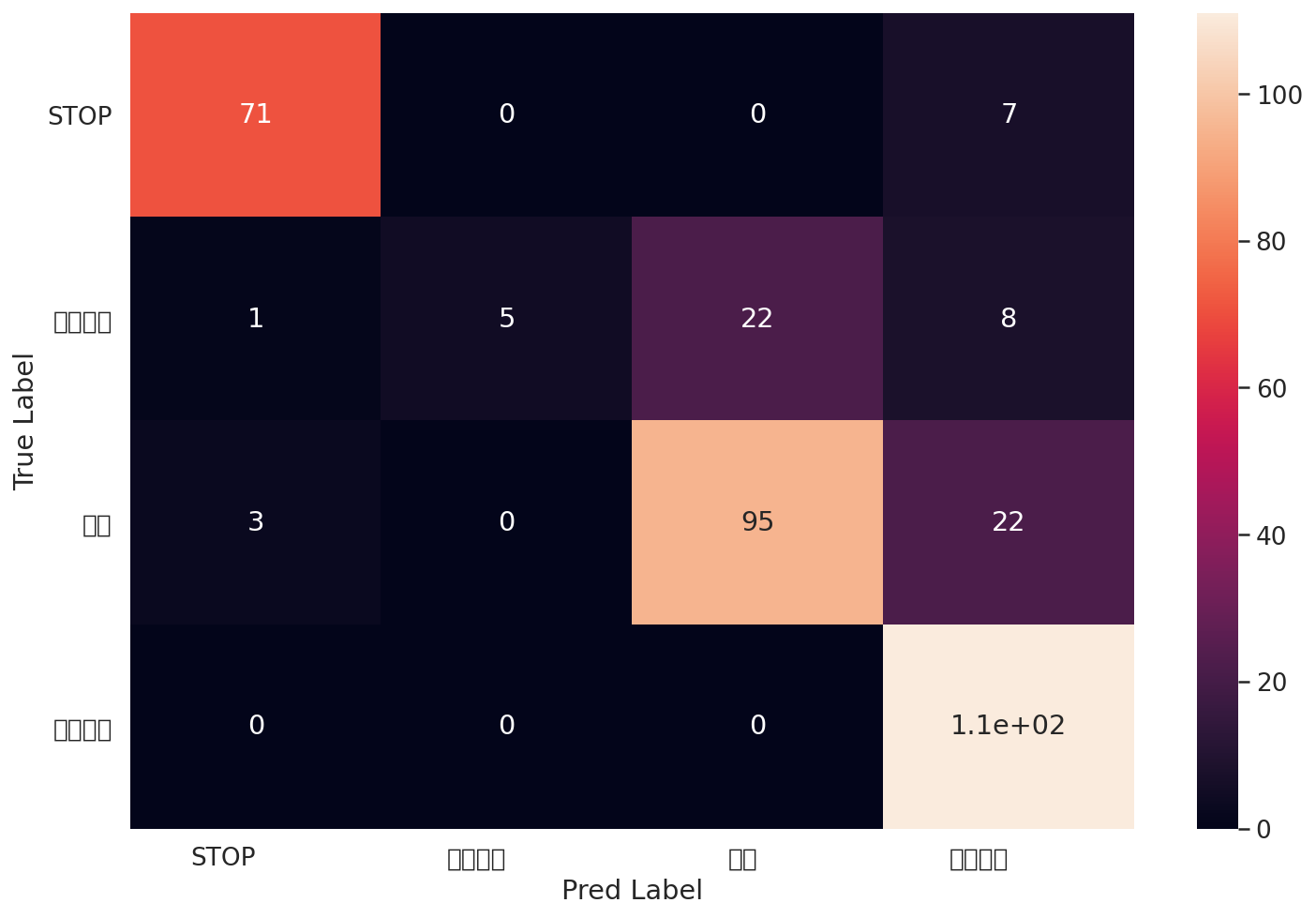
precision recall f1-score support
STOP 0.95 0.91 0.93 78
环岛行驶 1.00 0.14 0.24 36
直行 0.81 0.79 0.80 120
禁止通行 0.75 1.00 0.86 111
accuracy 0.82 345
macro avg 0.88 0.71 0.71 345
weighted avg 0.84 0.82 0.79 345
计算混淆矩阵
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred) # 计算TP, FP, TN, FN
df_cm = pd.DataFrame(cm, index=class_names, columns=class_names)
hmap = sns.heatmap(df_cm, annot=True)
hmap.yaxis.set_ticklabels(hmap.yaxis.get_ticklabels(), rotation=0, ha='right')
hmap.xaxis.set_ticklabels(hmap.xaxis.get_ticklabels(), rotation=0, ha='right')
plt.ylabel('True Label')
plt.xlabel('Pred Label')
plt.show()
测试识别一张图片
test_path = 'test.jpg'
show_img(test_path)

预测
# 函数:对图片进行识别,计算各个类别的概率
def predict_proba(model, img_path):
# 读取图片
image = Image.open(img_path)
image = transform['test'](image).unsqueeze(0) # 图像变化,并扩充一维,充当batch_size
print("test image shape :", image.shape)
# 模型预测
pred = model(image.to(device))
print("output : ", pred)
# 计算概率
proba = F.softmax(pred, dim=1)
print("proba : ", proba)
"""
知识点:x.data() vs x.detach()
相同:
① 都和 x 共享同一块数据
② 都和 x 的 计算历史无关
③ requires_grad = False
不同:
① x.detach()更安全
"""
#print("proba.data() ", proba.data()) 报错
print("proba.detach()", proba.detach())
return proba.detach().cpu().numpy().flatten() # flatten() : 返回一个一维数组
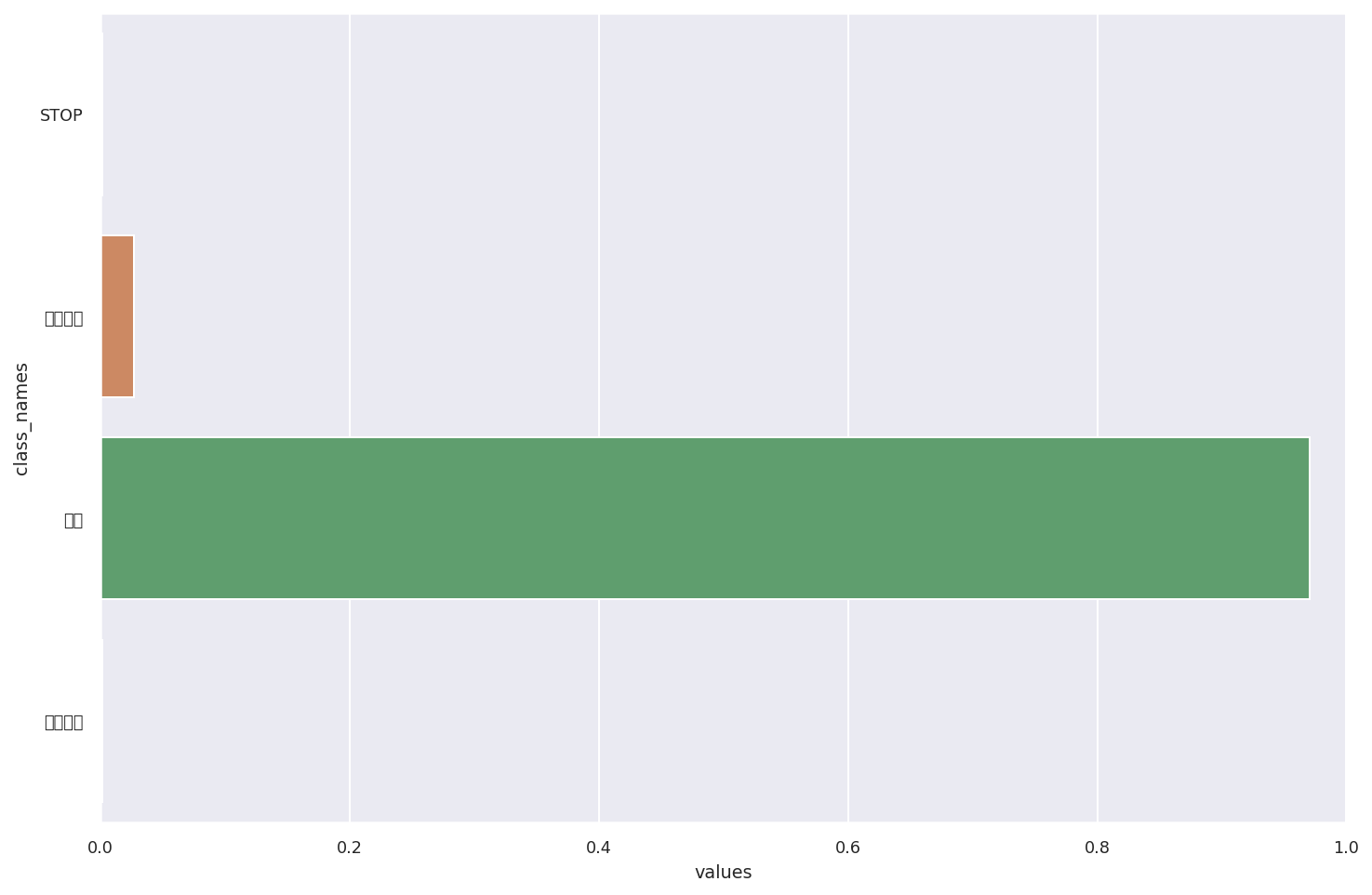
pred = predict_proba(best_model, test_path)
pred
test image shape : torch.Size([1, 3, 224, 224])
output : tensor([[-3.6926, -0.8210, 2.7710, -3.7285]], device='cuda:0',
grad_fn=<AddmmBackward>)
proba : tensor([[0.0015, 0.0267, 0.9703, 0.0015]], device='cuda:0',
grad_fn=<SoftmaxBackward>)
proba.detach() tensor([[0.0015, 0.0267, 0.9703, 0.0015]], device='cuda:0')
array([0.00151293, 0.02672534, 0.9703021 , 0.00145965], dtype=float32)
绘制结果
import warnings
warnings.filterwarnings('ignore')
def plot_prediction_confidence(prediction, class_names):
sns.set(font='SimHei', font_scale=0.8)
pred_df = pd.DataFrame({
'class_names' : class_names,
'values' : prediction
})
sns.barplot(x='values', y='class_names', data=pred_df, orient='h')
plt.xlim([0, 1])
plt.show()
plot_prediction_confidence(pred, class_names)
findfont: Font family ['SimHei'] not found. Falling back to DejaVu Sans.
findfont: Font family ['SimHei'] not found. Falling back to DejaVu Sans.
优化-多分类
优化代码中,使用了其他方式处理数据,添加了新的训练模型
第一种模型和训练方式和上方相似,准确率比较低,一方面原因是数据集太小。
import os
import glob
import cv2
import shutil
import numpy as np
from pathlib import Path
import matplotlib.pyplot as plt
# 训练集文件夹路径
train_path = "GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/*"
# 测试集文件夹路径
test_path = "GTSRB_Final_Test_Images/GTSRB/Final_Test/Images/*"
# 默认显示前5个类别的文件夹路径
glob.glob(train_path)[:5]
['GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00028',
'GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00000',
'GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00011',
'GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00007',
'GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00026']
切分数据集
# 按照比例: train 70%, val 20%, test 10% 创建文件夹,将每个类别的图片按此比例分配
# 第一步:分别创建train, val, test下各个类别的文件夹
classes_path = sorted(glob.glob(train_path)) # 所有类别的文件夹路径
categories = ['train', 'val', 'test'] # 分别创建3个文件夹
new_data_dir = Path('NEW_DATA') # 新数据集目录
for cat in categories:
for path in classes_path:
class_name = path[-5:] # 类别名称即为文件夹名称的最后5位数字
(new_data_dir/cat/class_name).mkdir(parents=True, exist_ok=True)
# 第二步:将原始train下的各个类别的图片按照比例保存到新建的文件夹下
class_indices = np.arange(len(classes_path)) # 所有类别对应的索引
#print(class_indices)
for i, class_idx in enumerate(class_indices):
img_paths = np.array(sorted(glob.glob(f'{classes_path[int(class_idx)]}/*.ppm'))) # 图片路径
class_name = classes_path[i][-5:]# 类别名称
# 打乱图片路径
np.random.shuffle(img_paths)
# 索引分割 70%, 20%, 10%
paths_split = np.split(img_paths, indices_or_sections=[int(0.7 * len(img_paths)), int(0.9 * len(img_paths))])
for ds, pathes in zip(categories, paths_split):
for path in pathes:
shutil.copy(path,f'{new_data_dir}/{ds}/{class_name}')
# 随机获取一张图片的路径,并显示
class_0_paths = np.array(sorted(glob.glob(f'{classes_path[0]}/*.ppm'))) # 索引0对应的类别的所有图片路径
random_img_path = np.random.choice(class_0_paths)
print(random_img_path)
# GTSRB_Final_Training_Images/GTSRB/Final_Training/Images/00000/00004_00029.ppm
show_img(random_img_path)
数据增强
from torchvision import transforms, models
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
from torch.optim import lr_scheduler
import torch
from torch import nn, optim
from collections import defaultdict
mean_nums = [0.485, 0.456, 0.406]
std_nums = [0.229, 0.224, 0.225]
transform = {
'train' : transforms.Compose([
transforms.RandomResizedCrop(size=256), # 随机裁剪
transforms.RandomRotation(degrees=15), # 随机旋转
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为tensor
transforms.Normalize(mean_nums, std_nums)
]),
'val' : transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
]),
'test' : transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean_nums, std_nums)
])
}
# 数据文件对象
image_folders = {
k : ImageFolder(f'{new_data_dir}/{k}', transform[k]) for k in categories
}
# 数据加载器
dataloaders = {
k : DataLoader(image_folders[k], batch_size=32, shuffle=True, num_workers=12, pin_memory=True) for k in categories
}
# train,val,test 大小
data_sizes = {
k : len(image_folders[k]) for k in categories
}
# 类别名称
names = image_folders['train'].classes
data_sizes # {'train': 27439, 'val': 7849, 'test': 3921}
# 显示一组图片
def imshow(imgs, title=None):
imgs = imgs.numpy().transpose((1, 2, 0)) # 类型转换,交换维度顺序
means = np.mean([mean_nums]) # 均值
stds = np.mean([std_nums]) # 标准差
imgs = imgs * stds + means # 复原
imgs = np.clip(imgs, 0, 1) # 将像素限制在0-1之间
plt.imshow(imgs)
if title:
plt.title(title)
plt.axis('off')
# 显示train中一批数据 1个batch_size
inputs, labels = next(iter(dataloaders['train']))
group_imgs = make_grid(inputs)
imshow(group_imgs, title=[names[i] for i in labels])

迁移学习
模型定义等方法,和上方一致
训练
# 创建模型对象
new_model = create_model(len(names)) # 有多少个类别,就有多少个输出
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
new_model = new_model.to(device)
def train_val_model(model, data_loader, dataset_sizes, device, epochs=10):
# 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) # 自动调节学习率
criterion = nn.CrossEntropyLoss() # 损失函数
history = defaultdict(list) # 保存结果
best_accuracy = 0 # 最好的准确率
best_model = None # 最好的模型
for epoch in range(epochs):
print(f'{epoch + 1} / {epochs}')
train_loss, train_accuracy = train(model, dataloaders['train'], criterion, optimizer,
device, scheduler, data_sizes['train'])
print(f'Train Loss : {train_loss}, Train Acc : {train_accuracy}')
eval_loss, eval_accuracy = evaluation(model, dataloaders['val'], criterion, device, data_sizes['val'])
print(f'Eval Loss : {eval_loss}, Eval Acc : {eval_accuracy}')
# 保存结果
history['train_acc'].append(train_accuracy)
history['train_loss'].append(train_loss)
history['eval_acc'].append(eval_accuracy)
history['eval_loss'].append(eval_loss)
# 比较:获取最好得分和模型
if best_accuracy < eval_accuracy:
torch.save(model.state_dict(), 'best_model_state.pth')
best_accuracy = eval_accuracy
print("最好模型验证得分: ", best_accuracy)
# 加载模型
model.load_state_dict(torch.load("best_model_state.pth"))
return model, history
best_model, history = train_val_model(new_model, dataloaders, data_sizes, device)
1 / 10
Train Loss : 7.555529162322447, Train Acc : 0.04369692876935005
Eval Loss : 6.954497982815998, Eval Acc : 0.02879347838461399
2 / 10
Train Loss : 5.441930296259883, Train Acc : 0.0411822609603405
Eval Loss : 4.568614590458754, Eval Acc : 0.027392026036977768
...
10 / 10
Train Loss : 3.10426214524916, Train Acc : 0.15015125274658203
Eval Loss : 3.840138560388146, Eval Acc : 0.10179641097784042
最好模型验证得分: tensor(0.1338, device='cuda:0')
模型2
def create_model_2(n_classes):
"""获取预训练模型
n_classes : 类别数量
"""
model = models.resnet50(pretrained=True)
# 冻结模型参数
for param in model.parameters():
param.requires_grad = False
# 替换全连接层
model.fc = nn.Sequential(
nn.Flatten(), # 拉平
nn.BatchNorm1d(2048), # 正则化
nn.Dropout(0.5),
nn.Linear(2048, 512),
nn.ReLU(), # 激活函数
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 43),
nn.LogSoftmax(dim=1)
)
return model
new_model_2 = create_model_2(len(names)).to(device) # 新模型
# new_model_2
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
...
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): ReLU()
(5): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=512, out_features=43, bias=True)
(8): LogSoftmax(dim=1)
)
)
best_model2, history2 = train_val_model(new_model_2, dataloaders, data_sizes, device, epochs=30)
1 / 30
Train Loss : 5.014600295009035, Train Acc : 0.2465468943119049
Eval Loss : 144.68224071390262, Eval Acc : 0.31086763739585876
2 / 30
Train Loss : 8.144561888454678, Train Acc : 0.23798245191574097
Eval Loss : 217.5533090432485, Eval Acc : 0.2623264193534851
...
30 / 30
Train Loss : 1.8795248135264382, Train Acc : 0.43347063660621643
Eval Loss : 131.41331707922424, Eval Acc : 0.6019875407218933
最好模型验证得分: tensor(0.6072, device='cuda:0')
绘制loss, acc
def plot_history(history):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))
ax1.plot(history['train_loss'], label="train loss")
ax1.plot(history['eval_loss'], label="eval loss")
#ax1.set_ylim([-0.05, 1.05])
ax1.legend()
ax1.set_ylabel("Loss")
ax1.set_xlabel("Epoch")
ax2.plot(history['train_acc'], label="train acc")
ax2.plot(history['eval_acc'], label="eval acc")
#ax2.set_ylim([-0.05, 1.05])
ax2.legend()
ax2.set_ylabel("Accuracy")
ax2.set_xlabel("Epoch")
fig.suptitle("Train and Val history")
plot_history(history2)
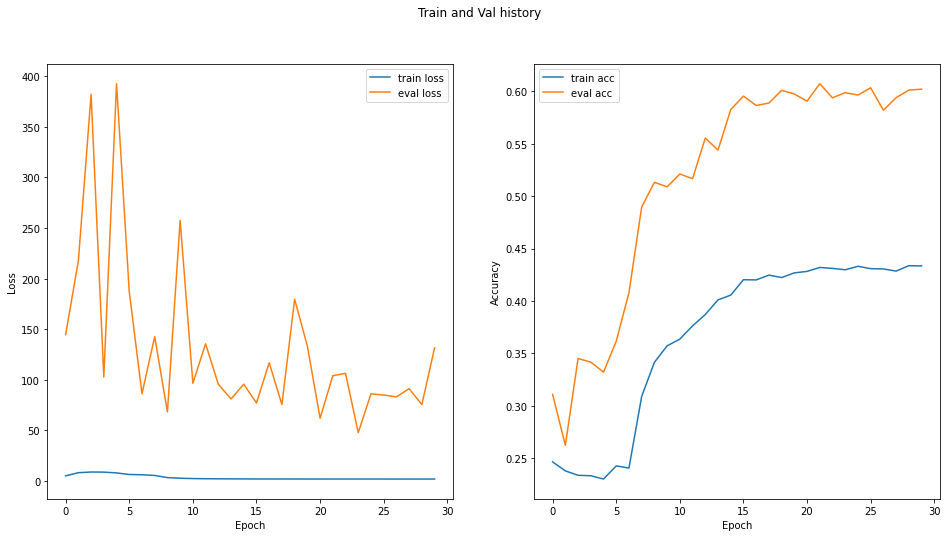
为什么 验证集准确度 大于 训练集准确度?
原因1:数据集太小,造成训练集和测试集的分布不均匀,造成训练集内部方差大于验证集,因而误差更大。
措施1:(1)扩充数据集;(2)重新切分数据集,使其分布均匀。
原因2:由dropout引起,它基本上能够确保测试准确性最好,优于训练集的准确性。
2023-02-22(三)


















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









