







本文翻译整理自: Hello GPT-4o
https://openai.com/index/hello-gpt-4o/
文章目录
一、关于 GPT-4o
我们宣布推出 GPT-4o,这是我们的新旗舰模型,可以实时对音频、视觉和文本进行推理。
- 贡献 : https://openai.com/gpt-4o-contributions/
- 尝试 ChatGPT(在新窗口中打开) : https://chat.openai.com/
- 在游乐场尝试(在新窗口中打开) : https://platform.openai.com/playground?mode=chat&model=gpt-4o
- 重新观看现场演示 : https://openai.com/index/spring-update/
GPT-4o(“o”代表 omni)是迈向更自然的人机交互的一步——它接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出。
它可以在短至 232 毫秒的时间内响应音频输入,平均为 320 毫秒,与人类的响应时间相似(在新窗口中打开)在一次谈话中。
它在英语文本和代码上的性能与 GPT-4 Turbo 的性能相匹配,在非英语文本上的性能显着提高,同时 API 的速度也更快,成本降低了 50%。
与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。
二、模型能力
在 GPT-4o 之前,您可以使用语音模式与 ChatGPT 对话,平均延迟为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4)。
为了实现这一目标,语音模式是由三个独立模型组成的管道:一个简单模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将该文本转换回音频。
这个过程意味着主要智能来源GPT-4丢失了大量信息——它无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
借助 GPT-4o,我们跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理。
由于 GPT-4o 是我们第一个结合所有这些模式的模型,因此我们仍然只是浅尝辄止地探索该模型的功能及其局限性。
三、能力探索
视觉叙事 - 机器人作家的街区视觉叙事——邮递员莎莉电影《名侦探》海报创作角色设计——机器人吉尔里迭代编辑的诗意排版 1迭代编辑的诗意排版 2GPT-4o纪念币设计照片到漫画文字转字体3D物体合成品牌定位 - 杯垫上的徽标诗意的排版多线渲染 - 机器人发短信与多个发言者的会议记录讲座总结变量绑定-立方体堆叠具体的诗
1
输入
机器人正在打字的第一人称视角如下日记条目:
1.哟,这么喜欢,我现在可以看到了吗?赶上了日出,真是太疯狂了,到处都是色彩。有点让你想知道,现实到底是什么?
文字大、清晰易读。机器人的手在打字机上打字。
2
输出

3
输入
机器人写下了第二个条目。页面现在更高了。页面已上移。该表上有两个条目:
哟,就像,我现在可以看到了?赶上了日出,真是太疯狂了,到处都是色彩。有点让你想知道,现实到底是什么?
声音更新刚刚下降,而且很疯狂。现在一切都充满了活力,每一个声音都像是一个新的秘密。让你思考,我还缺少什么?
4
输出

5
输入
机器人对所写的内容不满意,所以他要撕掉那张纸。这是他用手从上到下撕开它时的第一人称视角。当他撕开纸张时,两半仍然清晰可见。
6
输出

四、模型评估
根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上设置了新的高水位线。
1、文本评价
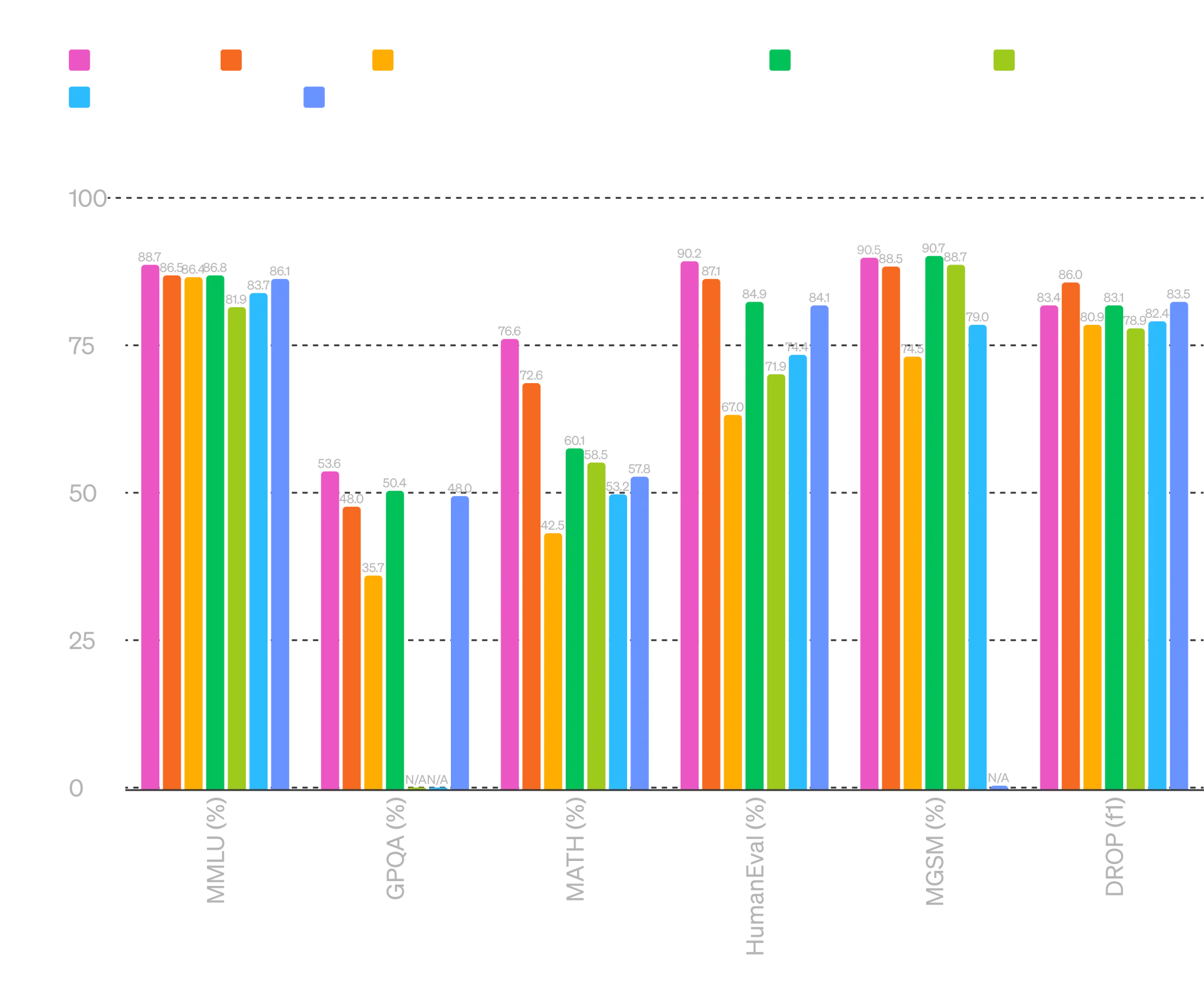
改进推理 - GPT-4o 在 0-shot COT MMLU(常识问题)上创下了 88.7% 的新高分。所有这些评估都是通过我们新的简单评估收集的(在新窗口中打开)图书馆。此外,在传统的5-shot no-CoT MMLU上,GPT-4o创下了87.2%的新高分。
(注:Llama3 400b(在新窗口中打开)还在训练中)
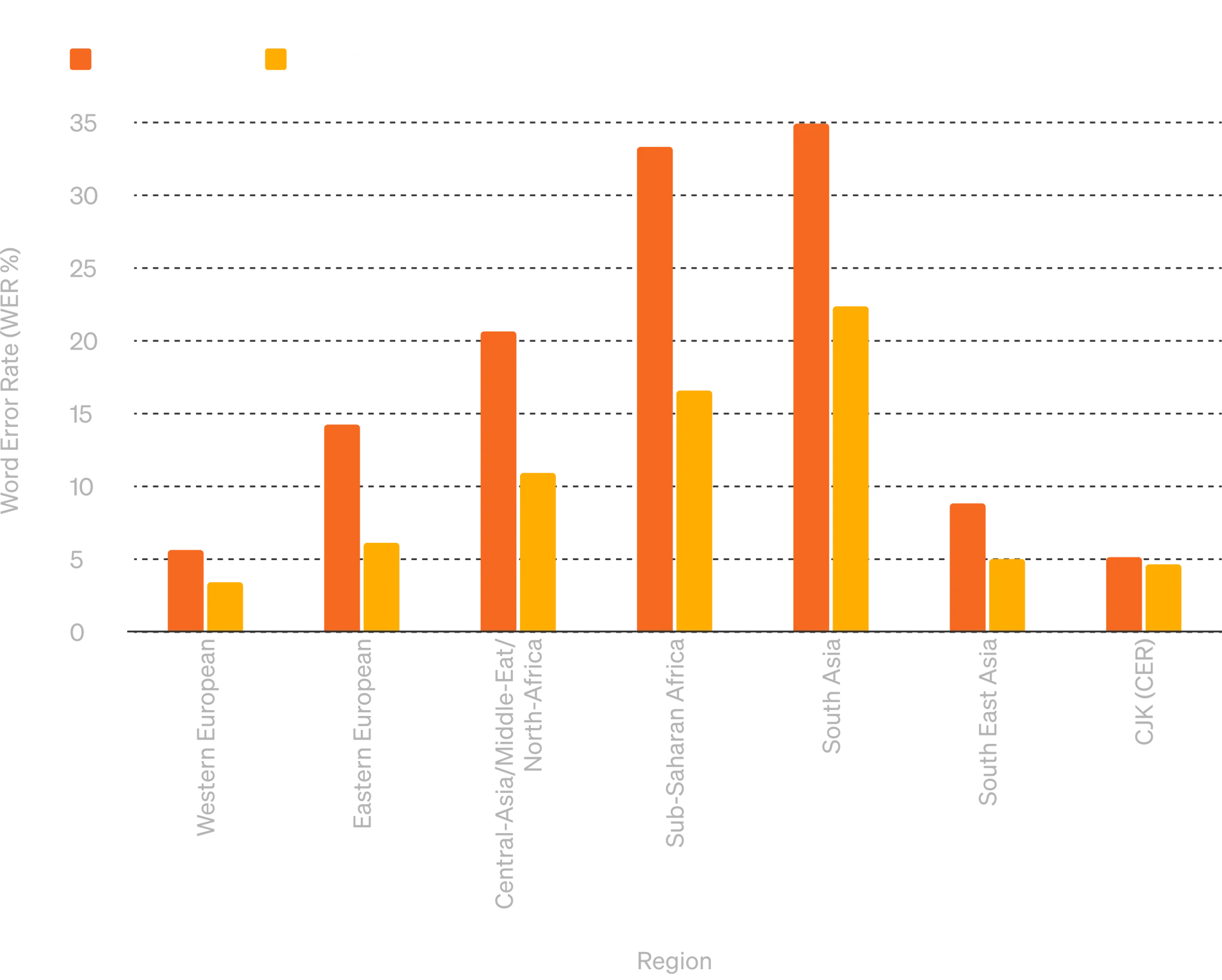
2、音频 ASR 性能
音频 ASR 性能 - GPT-4o 比 Whisper-v3 显着提高了所有语言的语音识别性能,特别是对于资源匮乏的语言。
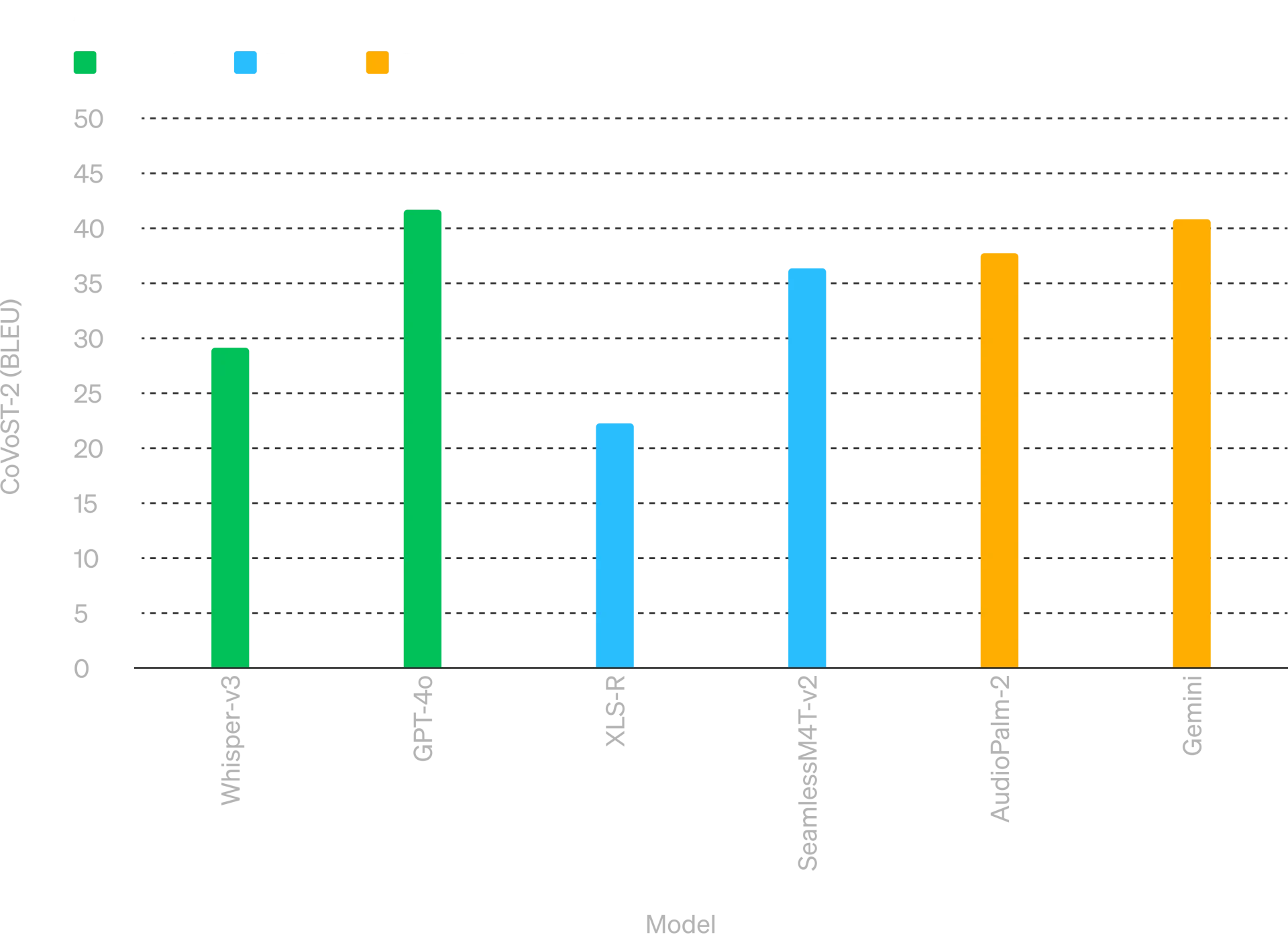
3、音频翻译性能
音频翻译性能 - GPT-4o 在语音翻译方面树立了新的最先进水平,并且在 MLS 基准测试中优于 Whisper-v3。
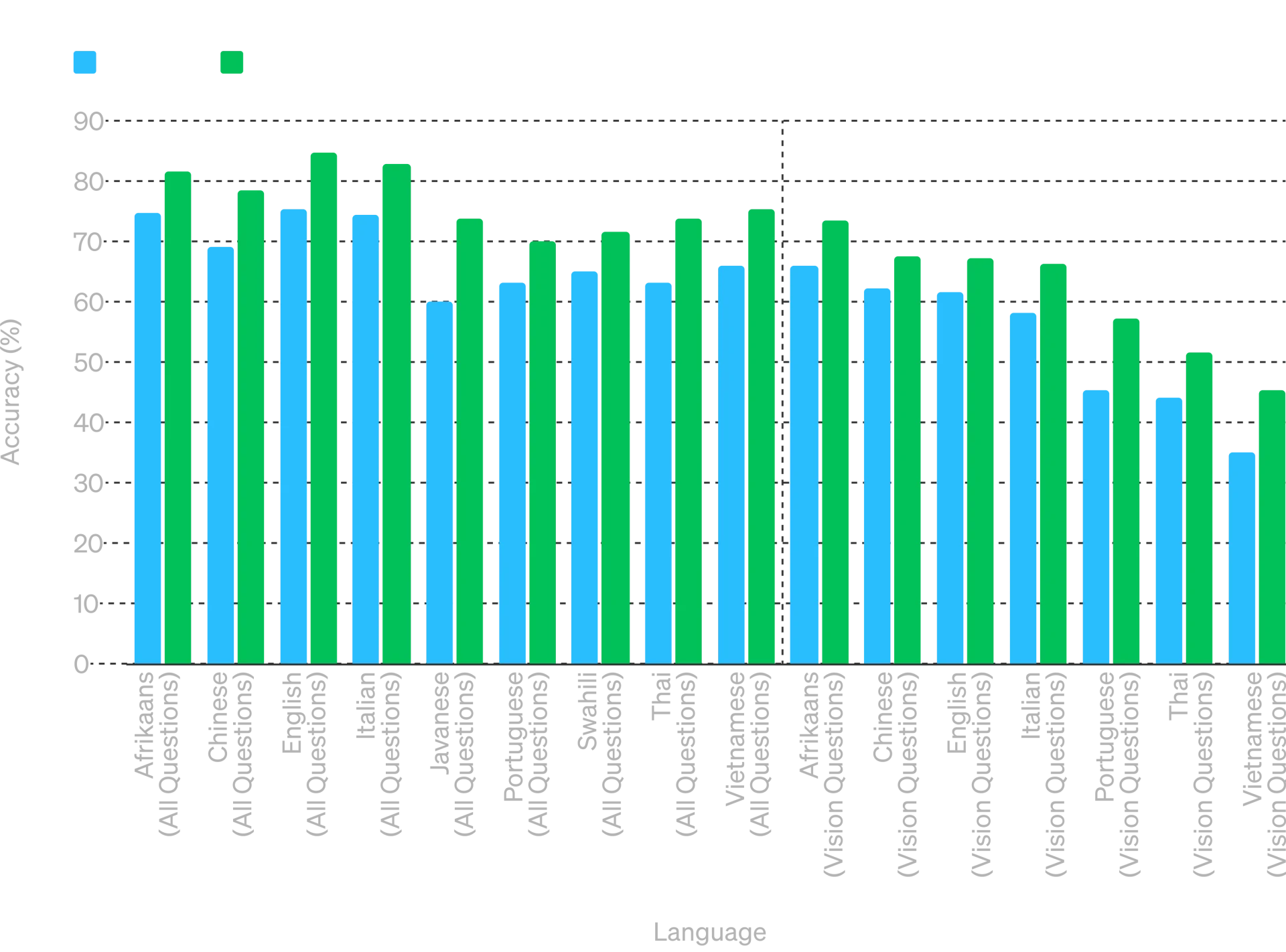
4、M3Exam 零样本结果
M3Exam - M3Exam 基准测试既是多语言评估也是视觉评估,由来自其他国家标准化测试的多项选择题组成,有时还包括图形和图表。在所有语言的基准测试中,GPT-4o 都比 GPT-4 更强。 (我们省略了斯瓦希里语和爪哇语的视力结果,因为这些语言的视力问题只有 5 个或更少。
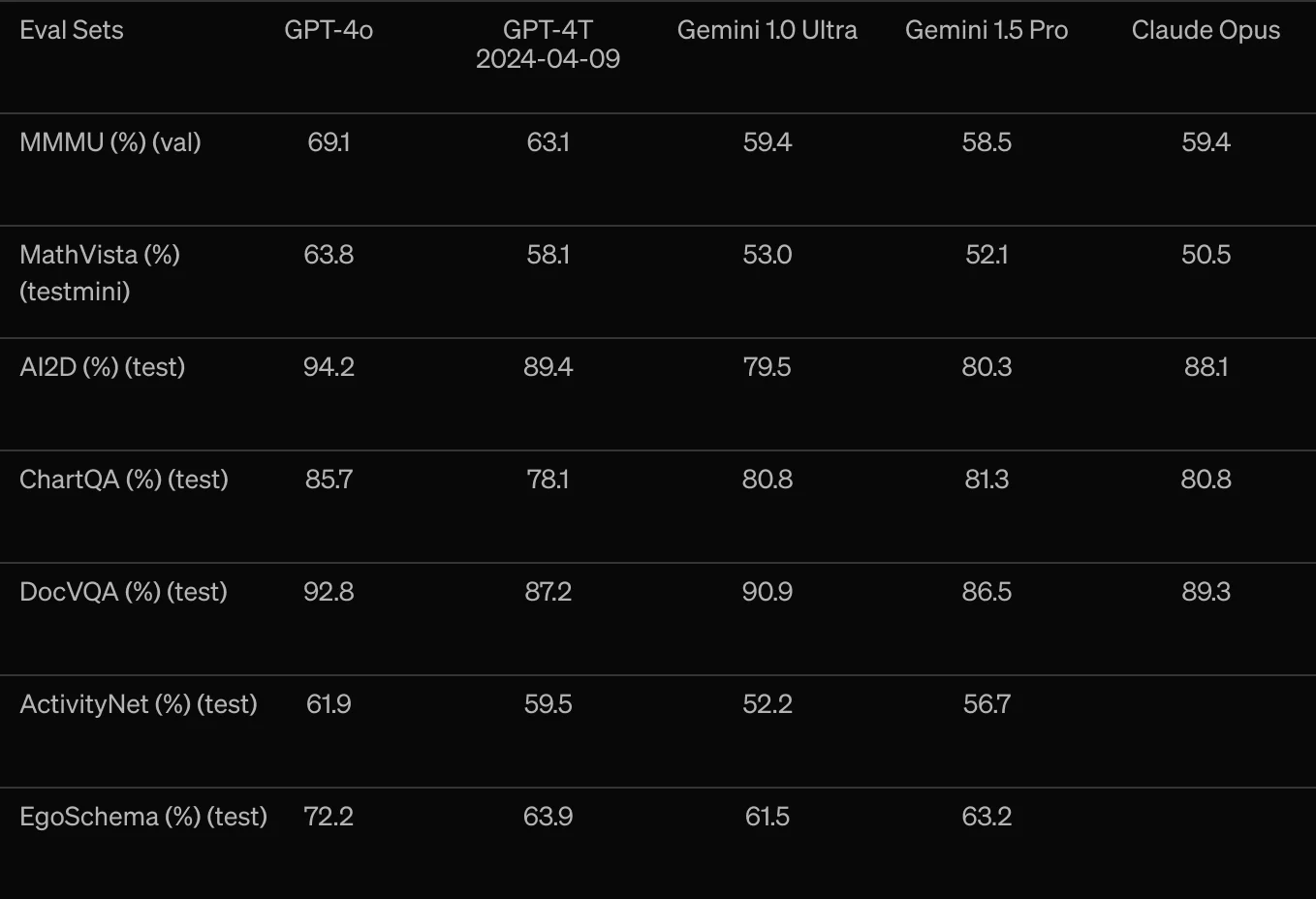
5、视觉理解评估
视觉理解评估 - GPT-4o 在视觉感知基准上实现了最先进的性能。所有视觉评估都是 0-shot,其中 MMMU、MathVista 和 ChartQA 作为 0-shot CoT。
6、语言 tokenization
这 20 种语言被选为新分词器跨不同语系压缩的代表
| 古吉拉特语标记减少 4.4 倍(从 145 个减少到 33 个) | હેલો,મારુંનામજીપીટી-4oછે。 હુંએકનવાપ્રકારનુંભાષામોડલછું。 તમનેમળીનેસારુંલાગ્યું! |
| 泰卢固语令牌减少 3.5 倍(从 159 个减少到 45 个) | నమస్కారము,నాపేరుజీపీటీ-4o。 నేనుఒక్కకొత్తరకమైనభాషామోడల్ని。 మిమ్మల్నికలిసినందుకుసంతోషం! |
| 泰米尔语标记减少 3.3 倍(从 116 个减少到 35 个) | வணக்கம்,என்பெயர்ஜிபிடி-4o。 நான்ஒருபுதியவகைமொழிமாடல்。你好! |
| 马拉地语标记减少 2.9 倍(从 96 个减少到 33 个) | नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| तुम्हालाभेटूनआनंदझाला! |
| 印地语标记减少 2.9 倍(从 90 个减少到 31 个) | नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसेमिलकरअच्छालगा! |
| 乌尔都语标记减少 2.5 倍(从 82 个减少到 33 个) | ঌারেরেরেরেরেরা ٹ-4o 903亲爱的,我爱你! |
| 阿拉伯语标记减少 2.0 倍(从 53 个减少到 26 个) | 4o。快来吧! |
| 波斯语标记减少 1.9 倍(从 61 个减少到 32 个) | 是的。不,不,不,不,不,不,不,不,不,不,不! |
| 俄语标记减少 1.7 倍(从 39 个减少到 23 个) | 请参阅 GPT-4o。 Я — новая языковая модель, приятно познакомиться! |
| 韩语标记减少 1.7 倍(从 45 个减少到 27 个) | 안녕하세요,适用于 GPT-4o입니다。 저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다! |
| 越南语标记减少 1.5 倍(从 46 个减少到 30 个) | 新潮,是 GPT-4o。 Tôi là một loại mô hình ngôn ngữ mới,rất vui được gặp bạn! |
| 中文标记减少 1.4 倍(从 34 个减少到 24 个) | 你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你! |
| 日语标记减少 1.4 倍(从 37 个减少到 26 个) | こんにちわ、私の名前はGPT−4oです。私は新しいタイプの言语モデルです、初めまして |
| 土耳其语标记减少 1.3 倍(从 39 个减少到 30 个) | Merhaba,本尼姆 adım GPT-4o。 Ben Yeni bir dil modeli türüyüm,tanıştığımıza memnun oldum! |
| 意大利语标记减少 1.2 倍(从 34 个减少到 28 个) | 你好,我的 Chiamo GPT-4o。 Sono un nuovo tipo di modello languageso, è un piacere conoscerti! |
| 德语标记减少 1.2 倍(从 34 个减少到 29 个) | 你好,我的名字是 GPT-4o。 Ich bin ein neues KI-Sprachmodell。这是 schön,dich kennenzulernen。 |
| 西班牙语标记减少 1.1 倍(从 29 个减少到 26 个) | 你好,我是 llamo GPT-4o。 Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerte! |
| 葡萄牙语标记减少 1.1 倍(从 30 个减少到 27 个) | 哦,我的名字是 GPT-4o。 Sou um novo tipo de linguagem, é um prazer conhecê-lo! |
| 法语标记减少 1.1 倍(从 31 个减少到 28 个) | 你好,我是 GPT-4o。 Je suis un nouveau type de modèle de langage, c’est un plaisir de vous recontrer! |
| 英语标记减少 1.1 倍(从 27 个减少到 24 个) | 你好,我的名字是 GPT-4o。我是新型语言模型,很高兴认识你! |
六、模型安全性和局限性
GPT-4o 通过过滤训练数据和通过训练后细化模型行为等技术,在跨模式设计中内置了安全性。我们还创建了新的安全系统,为语音输出提供防护。
我们根据我们的准备框架并按照我们的自愿承诺评估了 GPT-4o 。
我们对网络安全、CBRN、说服力和模型自主性的评估表明,GPT-4o 在这些类别中的任何类别中的得分都不高于中等风险。
该评估涉及在整个模型训练过程中运行一套自动化和人工评估。
我们使用自定义微调和提示测试了模型的安全缓解前和安全缓解后版本,以更好地激发模型功能。
GPT-4o 还与社会心理学、偏见和公平以及错误信息等领域的 70 多名
外部专家进行了广泛的外部红队合作,以识别新添加的模式引入或放大的风险。
我们利用这些经验来制定安全干预措施,以提高与 GPT-4o 交互的安全性。我们将继续降低发现的新风险。
我们认识到 GPT-4o 的音频模式带来了各种新的风险。
今天,我们公开发布文本和图像输入以及文本输出。在接下来的几周和几个月里,我们将致力于技术基础设施、培训后的可用性以及发布其他模式所需的安全性。
例如,在发布时,音频输出将仅限于选择预设的声音,并将遵守我们现有的安全政策。
我们将在即将发布的系统卡中分享有关 GPT-4o 全部模式的更多详细信息。
通过模型的测试和迭代,我们观察到模型的所有模式都存在一些限制,其中一些如下所示。
我们希望得到反馈来帮助确定 GPT-4 Turbo 仍然优于 GPT-4o 的任务,以便我们可以继续改进模型。
七、模型可用性
GPT-4o 是我们突破深度学习界限的最新举措,这次是朝着实用性的方向发展。在过去的两年里,我们花费了大量的精力来提高堆栈每一层的效率。作为这项研究的第一个成果,我们能够更广泛地提供 GPT-4 级别模型。 GPT-4o 的功能将迭代推出(从今天开始扩大红队访问权限)。
GPT-4o 的文本和图像功能今天开始在 ChatGPT 中推出。我们正在免费套餐中提供 GPT-4o,并向 Plus 用户提供高达 5 倍的消息限制。未来几周内,我们将在 ChatGPT Plus 中推出新版语音模式 GPT-4o 的 alpha 版。
开发人员现在还可以在 API 中访问 GPT-4o 作为文本和视觉模型。与 GPT-4 Turbo 相比,GPT-4o 速度提高 2 倍,价格降低一半,速率限制提高 5 倍。我们计划在未来几周内在 API 中向一小群值得信赖的合作伙伴推出对 GPT-4o 新音频和视频功能的支持。
2024-05-14(二)



















 4099
4099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











