







微调
微调模型以获得更好的结果和效率。
https://platform.openai.com/docs/guides/fine-tuning
精细调整让您通过提供以下内容从通过API可用的模型中获得更多:
- 比提示生成更高的质量结果
- 能够在比提示框中能容纳的更多示例上进行训练
- 由于提示词更短而节省的token 费用
- 低延迟请求
OpenAI 的文本生成模型已经在大量的文本上进行了预训练。为了有效地使用这些模型,我们在提示中包括指令,有时还会包含几个示例。使用演示来展示如何执行任务通常被称为“少样本学习”。
微调通过在比提示中能容纳的更多样例上训练,改进了少样本学习,让您在众多任务上获得更好的结果。
一旦模型经过微调,您在提示中就不需要提供那么多的样例。
这节省了成本并使得请求延迟更低。
在整体上,微调涉及以下步骤:
- 准备并上传训练数据
- 训练一个新的微调模型
- 评估结果并在需要时返回步骤 1
- 使用您的微调模型
访问我们的 定价页面 以了解更多关于如何计费进行微调模型训练和使用的详情。
哪些模型可以进行微调?
目前以下模型支持微调:
gpt-4o-2024-08-06gpt-4o-mini-2024-07-18gpt-4-0613gpt-3.5-turbo-0125gpt-3.5-turbo-1106gpt-3.5-turbo-0613
您还可以微调一个已经微调过的模型,这在您获取了额外数据且不想重复之前的训练步骤时非常有用。
从性能、成本和易用性方面考虑,我们预计 gpt-4o-mini 将是大多数用户的理想选择。
何时使用微调
微调 OpenAI 文本生成模型可以使它们更适合特定应用,但这需要仔细的时间和精力投入。我们建议首先尝试通过提示工程、提示链(将复杂任务分解为多个提示)和功能调用来获得良好的结果,关键原因如下:
- 在许多任务中,我们的模型可能最初看起来表现不佳,但通过合适的提示可以改善结果——因此可能不需要微调
- 与微调相比,对提示和其他策略进行迭代具有更快的反馈循环,微调需要创建数据集和运行训练作业
- 在仍然需要微调的情况下,最初的提示工程工作不会白费——我们通常在微调数据中使用良好的提示时看到最佳结果(或者将提示链/工具使用与微调结合)
我们的提示工程指南提供了有关一些最有效的策略和战术的背景,这些策略和战术可以在不进行微调的情况下获得更好的性能。您可能会发现在我们的游乐场中快速迭代提示很有帮助。
常见用例
以下是一些可以通过微调改进结果的常见用例:
- 设置风格、语气、格式或其他定性方面
- 提高产生所需输出的可靠性
- 纠正无法遵循复杂提示的失败
- 以特定方式处理许多边缘情况
- 执行难以在提示中表述的新技能或任务
思考这些用例的一种高级方法是,当“展示而非告知”更容易时。在接下来的章节中,我们将探讨如何设置微调数据以及各种示例,其中微调在性能上优于基线模型。
微调有效的另一个场景是通过用微调后的 gpt-4o-mini 模型替换更昂贵的模型(如 gpt-4o),来降低成本和/或延迟。如果您可以使用 gpt-4o 获得良好的结果,那么通过在 gpt-4o 完成内容上进行微调,通常可以达到类似的质量,可能还需要缩短指令提示。
准备您的数据集
一旦您确定微调是正确的解决方案(即,您已经将提示优化到了极致,并识别出模型仍然存在的问题),您就需要准备用于训练模型的数据。您应该创建一组多样化的演示对话,这些对话与您在生产环境中要求模型在推理时响应的对话相似。
数据集中的每个示例都应该是一个与我们的 Chat Completions API 相同格式的对话,具体来说是一个包含消息的列表,其中每个消息都有一个角色、内容和 可选名称。至少应该有一些训练示例直接针对那些提示的模型未按预期行为的情况,并且在数据中提供的辅助消息应该是您希望模型提供的理想响应。
示例格式
在这个示例中,我们的目标是创建一个聊天机器人,它偶尔会给出讽刺的回答,以下是我们可以为数据集创建的三个训练示例(对话):
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
多轮对话示例
在聊天格式中,示例可以包含具有助手角色的多个消息。在微调期间的默认行为是在单个示例中训练所有助手消息。要跳过对特定助手消息的微调,可以添加一个 weight 键来禁用该消息的微调,让您控制哪些助手消息被学习。weight 的允许值目前是 0 或 1。以下是一些使用 weight 的聊天格式示例。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
构建提示
我们通常建议在微调之前,选择最适合该模型的指令和提示集,并将它们包含在每个训练示例中。这应该可以帮助你达到最佳和最通用的结果,尤其是如果你有相对较少的训练示例(例如,不到一百个)。
如果你想要缩短在每个示例中重复的指令或提示以节省成本,请记住,模型可能会表现得好像那些指令被包含在内,并且在推理时可能很难让模型忽略那些“嵌入”的指令。
由于模型必须通过演示完全学习而没有指导指令,可能需要更多的训练示例才能获得良好的结果。
示例数量推荐
为了微调一个模型,您至少需要提供10个示例。我们通常看到,在50到100个训练示例上使用 gpt-4o-mini 和 gpt-3.5-turbo 进行微调时,模型会有明显的改进,但合适的数量会根据具体用例有很大差异。
我们建议从50个精心制作的演示开始,看看模型在微调后是否显示出改进的迹象。在某些情况下,这可能已经足够,但即使模型尚未达到生产质量,明显的改进也是一个好迹象,表明提供更多数据将继续改进模型。没有改进可能意味着您可能需要重新思考如何为模型设置任务或重构数据,在超过有限示例集之前进行调整。
训练和测试分割
在收集初始数据集之后,我们建议将其分割成训练和测试两部分。当提交包含训练和测试文件的微调作业时,我们将在训练过程中提供这两部分的统计数据。这些统计数据将是你评估模型改进程度的初始信号。此外,在早期构建测试集将有助于确保你能够在训练后通过在测试集上生成样本来评估模型。
Token 限制
Token 限制取决于您选择的模型。以下是 gpt-4o-mini 和 gpt-3.5-turbo 模型的最大推理上下文长度和训练示例上下文长度的概述:
| 模型 | 推理上下文长度 | 训练示例上下文长度 |
|---|---|---|
gpt-4o-2024-08-06 | 128,000 tokens | 65,536 tokens (128k coming soon) |
gpt-4o-mini-2024-07-18 | 128,000 tokens | 65,536 tokens (128k coming soon) |
gpt-3.5-turbo-0125 | 16,385 tokens | 16,385 tokens |
gpt-3.5-turbo-1106 | 16,385 tokens | 16,385 tokens |
gpt-3.5-turbo-0613 | 16,385 tokens | 4,096 tokens |
超过默认长度的示例将被截断到最大上下文长度,这将从训练示例的末尾删除 tokens。为确保您的整个训练示例都能适应上下文,请考虑检查消息内容中的总 token 数是否低于限制。
您可以使用 OpenAI 烹饪书中的 计数 tokens 笔记本 来计算 token 数。
估算成本
有关培训成本以及部署微调模型的输入和输出成本的详细定价,请访问我们的定价页面。请注意,我们不对用于培训验证的token 收费。要估算特定微调培训作业的成本,请使用以下公式:
(每1M输入token 的基础培训成本 ÷ 1M) × 输入文件中的token 数量 × 训练的轮数
对于一个包含100,000个token 的培训文件,经过3轮训练,预期的成本将是:
- 2024年10月31日免费期结束后,使用
gpt-4o-mini-2024-07-18的预期成本为 ~$0.90 USD。 - 使用
gpt-3.5-turbo-0125的预期成本为 ~$2.40 USD。
检查数据格式
一旦您已经编译了一个数据集,在创建微调作业之前,检查数据格式是非常重要的。为此,我们创建了一个简单的Python脚本,您可以使用它来查找潜在的错误、审查token 计数以及估算微调作业的成本。
微调数据格式验证
了解微调数据格式
上传训练文件
一旦数据经过验证,需要使用 Files API 上传文件,以便用于微调任务:
使用 DPO 创建一个微调任务
from openai import OpenAI
client = OpenAI()
job = client.fine_tuning.jobs.create(
training_file="file-all-about-the-weather",
model="gpt-4o-2024-08-06",
method={
"type": "dpo",
"dpo": {
"hyperparameters": {"beta": 0.1},
},
},
)
在您上传文件后,可能需要一些时间来处理。在文件处理期间,您仍然可以创建微调作业,但它将在文件处理完成后才开始。
大小限制和大型上传
最大上传大小为 512 MB,使用 Files API。您可以使用 Uploads API 将文件分成多个部分上传,最多可达 8 GB。我们建议从小开始,因为您不需要大量数据就能看到改进。
创建一个微调模型
在确保您拥有正确数量和结构的训练数据集,并上传文件后,下一步是创建一个微调作业。我们支持通过 微调用户界面 或通过编程方式创建微调作业。
要使用 OpenAI SDK 开始微调作业:
创建一个微调作业
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4o-mini-2024-07-18"
)
在这个例子中,model 是你想要微调的模型名称。请注意,只有特定的模型快照(如本例中的 gpt-4o-mini-2024-07-18)可以用于此参数,具体请参阅我们的支持模型。training_file 参数是在将训练文件上传到 OpenAI API 时返回的文件 ID。你可以使用 后缀参数来自定义你的微调模型名称。
如果您未指定方法,默认为监督微调(SFT)。
要设置额外的微调参数,例如 validation_file 或 hyperparameters,请参阅微调 API 规范。
在您开始微调作业后,它可能需要一些时间才能完成。您的作业可能在我们的系统中排队在其他作业之后,训练一个模型可能需要几分钟或几小时,具体取决于模型和数据集的大小。模型训练完成后,创建微调作业的用户将收到一封电子邮件确认。
除了创建微调作业外,您还可以列出现有作业、检索作业状态或取消作业。
与微调作业一起工作
from openai import OpenAI
client = OpenAI()
# List 10 fine-tuning jobs
client.fine_tuning.jobs.list(limit=10)
# Retrieve the state of a fine-tune
client.fine_tuning.jobs.retrieve("ftjob-abc123")
# Cancel a job
client.fine_tuning.jobs.cancel("ftjob-abc123")
# List up to 10 events from a fine-tuning job
client.fine_tuning.jobs.list_events(fine_tuning_job_id="ftjob-abc123", limit=10)
# Delete a fine-tuned model
client.models.delete("ft:gpt-3.5-turbo:acemeco:suffix:abc123")
使用微调模型
当作业成功时,当你检索作业详情时,你会看到 fine_tuned_model 字段已填充了模型的名称。你现在可以将此模型作为参数指定在 Chat Completions API 中,并使用 Playground 向其发送请求。
在您的作业完成后,模型应立即可用于推理。在某些情况下,您的模型可能需要几分钟才能准备好处理请求。如果对您的模型请求超时或找不到模型名称,这可能是由于您的模型仍在加载中。如果发生这种情况,请稍后再试。
使用微调模型
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-4o-mini:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
您可以通过传递模型名称来开始发送请求,如上所示,以及在我们的 GPT 指南 中所示。
使用已检查点的模型
除了在每个微调作业结束时创建一个最终的微调模型之外,OpenAI 还会在每个训练周期结束时为您创建一个完整的模型检查点。这些检查点本身就是可以用于我们完成和聊天完成端点的完整模型。检查点很有用,因为它们可能提供了在模型经历过度拟合之前您的微调模型的版本。
要访问这些检查点,
对于每个检查点对象,您将看到 fine_tuned_model_checkpoint 字段已填充了模型检查点的名称。现在您可以像使用 最终微调模型 一样使用此模型。
{
"object": "fine_tuning.job.checkpoint",
"id": "ftckpt_zc4Q7MP6XxulcVzj4MZdwsAB",
"created_at": 1519129973,
"fine_tuned_model_checkpoint": "ft:gpt-3.5-turbo-0125:my-org:custom-suffix:96olL566:ckpt-step-2000",
"metrics": {
"full_valid_loss": 0.134,
"full_valid_mean_token_accuracy": 0.874
},
"fine_tuning_job_id": "ftjob-abc123",
"step_number": 2000
}
每个检查点将指定其:
step_number: 创建检查点时的步骤(每个epoch是训练集步骤数除以批量大小的结果)metrics:一个对象,包含创建检查点时的微调作业的指标。
目前,只有作业最后 3 个纪元的检查点被保存并可用于使用。我们计划在不久的将来发布更复杂和灵活的检查点策略。
分析您的微调模型
我们在训练过程中计算以下训练指标:
- 训练损失
- 训练标记准确率
- 验证损失
- 验证标记准确率
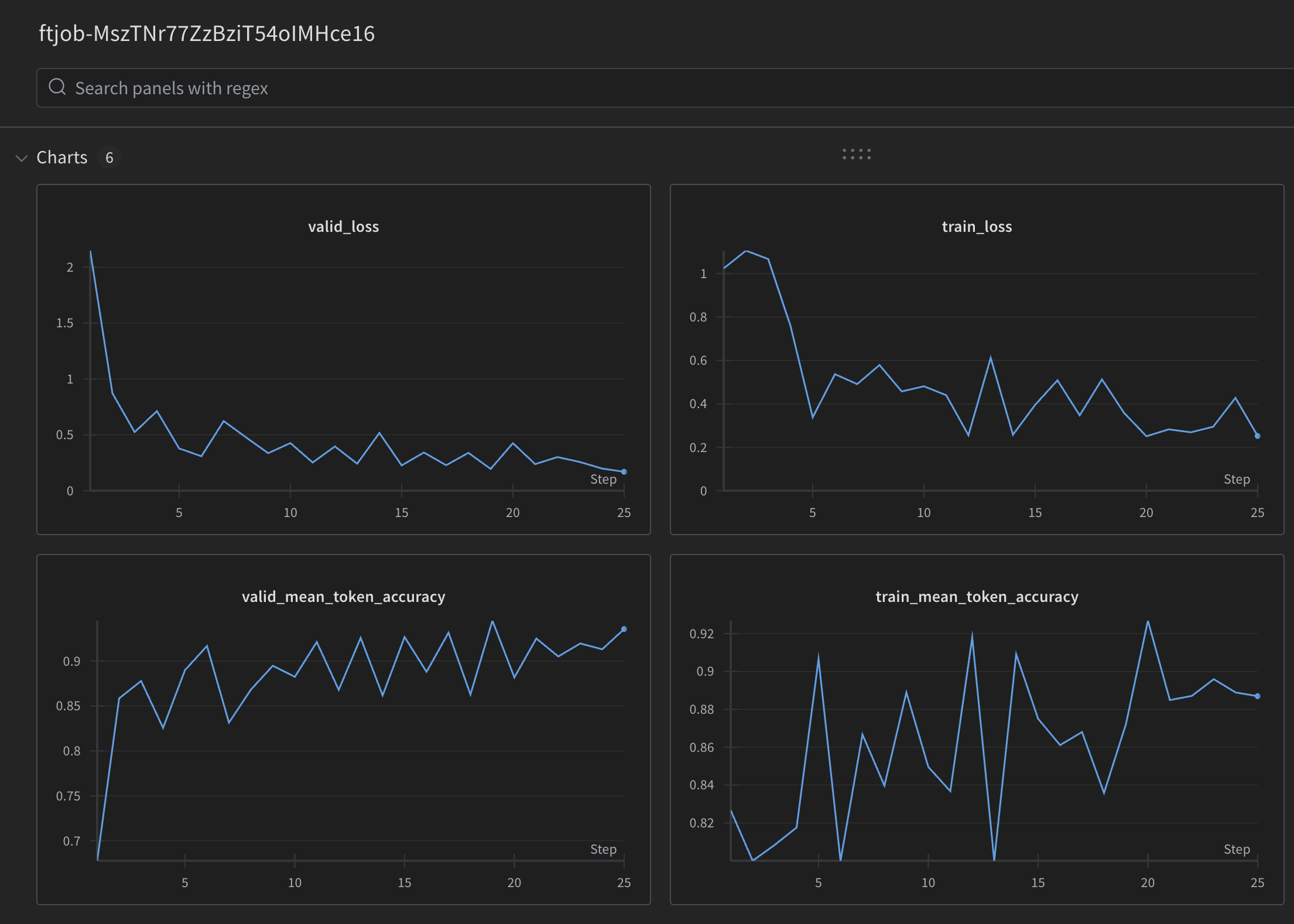
验证损失和验证标记准确率以两种不同的方式计算 - 在每个步骤的数据的小批次上,以及在每个纪元的末尾的完整验证分割上。完整的验证损失和完整的验证标记准确率指标是最准确的指标,用于跟踪模型的整体性能。这些统计数据旨在提供一个理智的检查,以确保训练顺利进行(损失应该减少,标记准确率应该增加)。当微调作业正在运行时,您可以查看包含一些有用指标的的事件对象:
{
"object": "fine_tuning.job.event",
"id": "ftevent-abc-123",
"created_at": 1693582679,
"level": "info",
"message": "Step 300/300: training loss=0.15, validation loss=0.27, full validation loss=0.40",
"data": {
"step": 300,
"train_loss": 0.14991648495197296,
"valid_loss": 0.26569826706596045,
"total_steps": 300,
"full_valid_loss": 0.4032616495084362,
"train_mean_token_accuracy": 0.9444444179534912,
"valid_mean_token_accuracy": 0.9565217391304348,
"full_valid_mean_token_accuracy": 0.9089635854341737
},
"type": "metrics"
}
在微调作业完成后,您还可以通过查询微调作业、从 result_files 中提取文件 ID,然后检索该文件的内容来查看训练过程的指标。每个结果 CSV 文件都有以下列:step、train_loss、train_accuracy、valid_loss 和 valid_mean_token_accuracy。
step,train_loss,train_accuracy,valid_loss,valid_mean_token_accuracy
1,1.52347,0.0,,
2,0.57719,0.0,,
3,3.63525,0.0,,
4,1.72257,0.0,,
5,1.52379,0.0,,
虽然指标可能有所帮助,但评估微调模型的样本可以提供最相关的模型质量感。我们建议使用 Evals 产品来比较您的基线模型与微调模型。或者,您可以在测试集上手动生成两个模型的样本,并对照比较。测试集应理想地包括您可能在生产用例中发送给模型的完整输入分布。
对数据质量进行迭代
如果微调作业的结果没有达到您的预期,请考虑以下调整训练数据集的方法:
- 收集示例以针对剩余问题
- 如果模型在某个方面仍然表现不佳,请添加直接向模型展示如何正确执行这些方面的训练示例
- 仔细检查现有示例中存在的问题
- 如果您的模型存在语法、逻辑或风格问题,检查您的数据是否也有这些问题。例如,如果模型现在说“我将为您安排这次会议”(而它不应该),看看现有示例是否教会了模型说出它无法做到的新事物
- 考虑数据的平衡和多样性
- 如果数据中60%的助手响应说“我不能回答这个问题”,但在推理时间只有5%的响应应该这么说,您可能会遇到拒绝过多的情况
- 确保您的训练示例包含所有需要用于响应的信息
- 如果我们希望模型根据用户的个人特征来赞美用户,而一个训练示例包括对在先前的对话中没有找到的特征的助手赞美,模型可能会学会臆想信息
- 查看训练示例中的协议/一致性
- 如果多个人创建了训练数据,模型性能可能会受到人与人之间协议/一致性的限制。例如,在一个文本提取任务中,如果人们在70%的提取片段上达成一致,那么模型可能无法做得比这更好
- 确保所有训练示例都以预期的推理格式进行
对数据量进行迭代
一旦你对示例的质量和分布感到满意,你可以考虑增加训练示例的数量。这通常有助于模型更好地学习任务,尤其是在可能的“边缘情况”方面。我们预计每次将训练示例的数量加倍,都会带来类似的改进。你可以通过以下方式粗略估计增加训练数据量所能带来的预期质量提升:
- 在你当前的数据库上微调
- 在你当前数据库的一半上微调
- 观察两者之间的质量差距
总的来说,如果你必须做出权衡,通常来说,少量高质量的数据比大量低质量的数据更有效。
超参数迭代
您可以指定以下超参数:
- epochs
- 学习率乘数
- 批大小
我们建议最初训练时不指定这些参数,让我们根据数据集大小为您选择默认值,然后根据您观察到的以下情况进行调整:
- 如果模型没有像预期那样很好地跟踪训练数据,请将epochs的数量增加1或2
- 这在只有一个理想完成(或一小组相似的理想完成)的任务中更为常见。一些例子包括分类、实体提取或结构化解析。这些通常是您可以对参考答案计算最终准确度指标的任务。
- 如果模型不如预期地多样化,请将epochs的数量减少1或2
- 这在有多种可能的良好完成的情况中更为常见
- 如果模型似乎没有收敛,请增加学习率乘数
您可以将超参数设置如下所示:
设置超参数
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4o-mini-2024-07-18",
method={
"type": "supervised",
"supervised": {
"hyperparameters": {"n_epochs": 2},
},
},
)
视觉微调
微调也可以使用 JSONL 文件中的图像。就像您可以向 Chat Completions 发送一个或多个图像输入 一样,您也可以在您的训练数据中包含这些相同的消息类型。图像可以以 HTTP URL 或包含 base64 编码的图像 的数据 URL 的形式提供。
以下是一个在您的 JSONL 文件中的一行上的图像消息的示例。下面,JSON 对象被展开以提高可读性,但通常这个 JSON 会出现在您的数据文件的单行上:
{
"messages": [
{ "role": "system", "content": "You are an assistant that identifies uncommon cheeses." },
{ "role": "user", "content": "What is this cheese?" },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/3/36/Danbo_Cheese.jpg"
}
}
]
},
{ "role": "assistant", "content": "Danbo" }
]
}
图像数据集要求
大小
- 您的训练文件可以包含最多50,000个包含图像的示例(不包括文本示例)。
- 每个示例最多可以包含10张图像。
- 每张图像的最大大小为10 MB。
格式
- 图片必须是 JPEG、PNG 或 WEBP 格式。
- 您的图片必须使用 RGB 或 RGBA 图像模式。
- 您不能包含由
assistant角色输出的消息中的图片。
内容审查政策
我们在训练前扫描您的图像以确保它们符合我们的使用政策。这可能会在开始微调之前引入文件验证的延迟。
以下内容的图像将从您的数据集中排除,并且不会被用于训练:
- 人物
- 脸部
- 儿童
- 验证码
Help
如果您的图像被跳过该怎么办
您的图像可能因为以下原因被跳过:
- 包含验证码 , 包含人物, 包含面部, 包含儿童
- 删除图像。目前,我们无法对包含这些实体的图像进行微调。
- 无法访问的 URL
- 确保图像 URL 是公开可访问的。
- 图像太大
- 请确保您的图像大小在我们数据集大小限制范围内。
- 无效的图像格式
- 请确保您的图像格式符合我们的 数据集格式。
降低训练成本
如果您将图像的 detail 参数设置为 low,则图像将调整为 512 x 512 像素,并且无论其大小如何,都只由 85 个标记表示。这将降低训练成本。了解更多信息。
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/3/36/Danbo_Cheese.jpg",
"detail": "low"
}
}
视觉微调的其他考虑因素
- 为了控制图像理解的保真度,将
image_url的detail参数设置为low、high或auto,适用于每张图像。这也会影响模型在训练期间看到的每张图像的标记数量,并会影响训练成本。更多信息请见这里。
预设微调
直接偏好优化 (DPO) 微调允许您根据提示和回应对模型进行微调。这种方法使模型能够从人类偏好中学习,优化输出更可能被偏爱的结果。请注意,我们目前仅支持文本形式的 DPO 微调。
为数据准备DPO
您的数据集中的每个示例应包含:
- 一个提示,如用户消息。
- 一个首选输出(理想的助手响应)。
- 一个非首选输出(次优的助手响应)。
数据应以JSONL格式格式化,每行代表一个示例,其结构如下:
{
"input": {
"messages": [
{
"role": "user",
"content": "Hello, can you tell me how cold San Francisco is today?"
}
],
"tools": [],
"parallel_tool_calls": true
},
"preferred_output": [
{
"role": "assistant",
"content": "Today in San Francisco, it is not quite cold as expected. Morning clouds will give away to sunshine, with a high near 68°F (20°C) and a low around 57°F (14°C)."
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": "It is not particularly cold in San Francisco today."
}
]
}
目前,我们只针对每个示例进行一轮对话训练,其中首选和非首选消息需要是最后的助手消息。
堆叠方法:监督 + DPO
目前,OpenAI 将监督微调(SFT)作为默认的微调方法。在运行另一个 DPO 作业之前,先对您首选的响应(或其子集)进行 SFT 微调可以显著提高模型的对齐和性能。通过首先在期望的响应上微调模型,它可以更好地识别正确的模式,为 DPO 精炼行为提供一个坚实的基础。
建议的工作流程如下:
- 使用您首选响应的子集,用 SFT 对基础模型进行微调。重点关注确保任务的数据质量和代表性。
- 使用经过 SFT 微调的模型作为起点,并应用 DPO 根据偏好比较调整模型。
配置 DPO 微调作业
我们在微调作业创建端点中引入了一个 method 字段,其中您可以指定 type 以及任何相关的 hyperparameters。对于 DPO:
- 将
type参数设置为dpo - 可选地设置
hyperparameters属性,配置您想要配置的任何选项。
beta 超参数是一个仅在 DPO 中可用的新选项。它是一个介于 0 和 2 之间的浮点数,用于控制新模型将有多严格地遵循其先前行为,与提供的偏好对齐。高数值将更保守(更倾向于先前行为),而低数值将更激进(更频繁地倾向于新提供的偏好)。
您也可以将其设置为 auto(默认值)以使用平台配置的值。
以下示例展示了如何使用 OpenAI SDK 配置 DPO 微调作业。有关创建微调作业的更多信息,请参阅指南的下一节。
使用 DPO 创建微调作业
from openai import OpenAI
client = OpenAI()
job = client.fine_tuning.jobs.create(
training_file="file-all-about-the-weather",
model="gpt-4o-2024-08-06",
method={
"type": "dpo",
"dpo": {
"hyperparameters": {"beta": 0.1},
},
},
)
微调示例
现在我们已经探讨了微调 API 的基础知识,接下来让我们看看针对几个不同的用例进行微调生命周期体验。
风格和语气
在这个例子中,我们将探讨如何构建一个经过微调的模型,该模型能够在仅使用提示的情况下实现模型遵循特定的风格和语气指导。
首先,我们创建一组示例消息,展示模型应该做什么,在这个例子中是拼写错误。
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
如果您想跟随着教程自己创建一个微调模型,您至少需要10个示例。
在获取可能改进模型的数据后,下一步是检查这些数据是否满足所有 格式要求。
现在我们已经格式化和验证了数据,最后的训练步骤是启动一个任务来创建微调模型。您可以通过以下方式使用 OpenAI CLI 或我们的 SDK 来完成此操作:
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("marv.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-4o-mini-2024-07-18"
)
一旦训练作业完成,您将能够 使用您的微调模型。
结构化输出
另一种非常适合微调的使用案例是让模型提供结构化信息,在这种情况下是关于体育新闻标题:
{"messages": [{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: \"player\" (full name), \"team\", \"sport\", and \"gender\"."}, {"role": "user", "content": "Sources: Colts grant RB Taylor OK to seek trade"}, {"role": "assistant", "content": "{\"player\": \"Jonathan Taylor\", \"team\": \"Colts\", \"sport\": \"football\", \"gender\": \"male\" }"}]}
{"messages": [{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: \"player\" (full name), \"team\", \"sport\", and \"gender\"."}, {"role": "user", "content": "OSU 'split down middle' on starting QB battle"}, {"role": "assistant", "content": "{\"player\": null, \"team\": \"OSU\", \"sport\": \"football\", \"gender\": null }"}]}
如果您想跟随教程并自己创建一个微调模型,您至少需要10个示例。
在获取可能改进模型的资料后,下一步是检查这些资料是否符合所有 格式要求。
现在我们已经将数据格式化和验证完成,最终的训练步骤是启动一个作业来创建微调模型。您可以通过以下方式使用 OpenAI CLI 或我们的 SDK 来完成此操作:
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("sports-context.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-4o-mini-2024-07-18"
)
一旦训练作业完成,您将能够 使用您的微调模型 并发出如下请求:
completion = client.chat.completions.create(
model="ft:gpt-4o-mini:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "Given a sports headline, provide the following fields in a JSON dict, where applicable: player (full name), team, sport, and gender"},
{"role": "user", "content": "Richardson wins 100m at worlds to cap comeback"}
]
)
print(completion.choices[0].message)
基于格式化的训练数据,响应应如下所示:
{
"player": "Sha'Carri Richardson",
"team": null,
"sport": "track and field",
"gender": "female"
}
工具调用
Chat Completions API 支持工具调用 tool calling。在完成 API 中包含大量工具可能会消耗相当数量的提示token ,有时模型会虚构或无法提供有效的 JSON 输出。
使用工具调用示例微调模型可以让你:
- 即使完整的工具定义不存在,也能获得类似格式的响应
- 获得更准确和一致的结果
按照以下格式格式化你的示例,每行包括一个“messages”列表和一个可选的“tools”列表:
{
"messages": [
{ "role": "user", "content": "What is the weather in San Francisco?" },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_id",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"
}
}
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and country, eg. San Francisco, USA"
},
"format": { "type": "string", "enum": ["celsius", "fahrenheit"] }
},
"required": ["location", "format"]
}
}
}
]
}
如果您想跟随着创建一个微调模型,您至少需要10个示例。
如果您的目标是使用更少的token ,一些有用的技巧包括:
- 忽略函数和参数描述:从函数和参数中移除描述字段
- 忽略参数:从参数对象中删除整个属性字段
- 完全省略函数:从函数数组中移除整个函数对象
如果您的目标是最大化函数调用输出的正确性,我们建议在训练和查询微调模型时使用相同的工具定义。
对函数调用的微调也可以用来定制模型对函数输出的响应。为此,您可以包括一个函数响应消息和一个解释该响应的助手消息:
{
"messages": [
{"role": "user", "content": "What is the weather in San Francisco?"},
{"role": "assistant", "tool_calls": [{"id": "call_id", "type": "function", "function": {"name": "get_current_weather", "arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"}}]}
{"role": "tool", "tool_call_id": "call_id", "content": "21.0"},
{"role": "assistant", "content": "It is 21 degrees celsius in San Francisco, CA"}
],
"tools": [] // same as before
}
并行函数调用默认启用,可以通过在训练示例中使用 parallel_tool_calls: false 来禁用。
函数调用
function_call 和 functions 已被弃用,建议使用 tools 参数代替。
Chat Completions API 支持函数调用 function calling。在完成 API 中包含大量函数可能会消耗相当数量的提示token ,有时模型可能会产生幻觉或无法提供有效的 JSON 输出。
使用函数调用示例微调模型可以让你:
- 即使完整的函数定义不存在,也能获得类似格式的响应
- 获得更准确和一致的输出
按照以下格式格式化你的示例,每行包括一个“messages”列表和一个可选的“functions”列表:
{
"messages": [
{ "role": "user", "content": "What is the weather in San Francisco?" },
{
"role": "assistant",
"function_call": {
"name": "get_current_weather",
"arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"
}
}
],
"functions": [
{
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and country, eg. San Francisco, USA"
},
"format": { "type": "string", "enum": ["celsius", "fahrenheit"] }
},
"required": ["location", "format"]
}
}
]
}
如果您想跟随着教程自己创建一个微调模型,您至少需要10个示例。
如果您的目标是使用更少的token ,以下是一些有用的技巧:
- 忽略函数和参数描述:从函数和参数中移除描述字段
- 忽略参数:从参数对象中删除整个属性字段
- 完全省略函数:从函数数组中移除整个函数对象
如果您的目标是最大化函数调用输出的正确性,我们建议在训练和查询微调模型时使用相同的函数定义。
功能调用的微调也可以用来定制模型对函数输出的响应。为此,您可以包括一个函数响应消息和一个解释该响应的助手消息:
{
"messages": [
{"role": "user", "content": "What is the weather in San Francisco?"},
{"role": "assistant", "function_call": {"name": "get_current_weather", "arguments": "{\"location\": \"San Francisco, USA\", \"format\": \"celsius\"}"}}
{"role": "function", "name": "get_current_weather", "content": "21.0"},
{"role": "assistant", "content": "It is 21 degrees celsius in San Francisco, CA"}
],
"functions": [] // same as before
}
微调集成
OpenAI 提供了通过我们的集成框架将您的微调作业与第三方服务集成的功能。集成通常允许您在第三方系统中跟踪作业状态、状态、指标、超参数和其他与作业相关的信息。您还可以使用集成根据作业状态变化在第三方系统中触发操作。目前,唯一支持的集成是与 Weights and Biases 的集成,但很快会有更多集成。
重量和偏差集成
重量和偏差 (W&B) 是一个流行的跟踪机器学习实验的工具。您可以使用 OpenAI 与 W&B 的集成来跟踪您的微调作业在 W&B 中的情况。此集成将自动记录指标、超参数和其他与作业相关的信息到您指定的 W&B 项目。
要将您的微调作业与 W&B 集成,您需要
- 为您的 Weights and Biases 账户向 OpenAI 提供身份验证凭据
- 在创建新的微调作业时配置 W&B 集成
使用 OpenAI 认证 Weights and Biases 账户
认证是通过向 OpenAI 提交有效的 W&B API 密钥来完成的。目前,这只能通过 账户仪表板 来完成,并且只能由账户管理员完成。您的 W&B API 密钥将在 OpenAI 中加密存储,并允许 OpenAI 在您的微调作业运行时代表您向 W&B 发布指标和元数据。如果在没有首先使用 WandB 认证您的 OpenAI 组织的情况下尝试在微调作业上启用 W&B 集成,将导致错误。
启用 Weights & Biases 集成
在创建新的微调作业时,您可以通过在作业创建请求中的 integrations 字段下包含一个新的 "wandb" 集成来启用 W&B 集成。此集成允许您指定您希望新创建的 W&B 运行出现在哪个 W&B 项目下。
以下是在创建新的微调作业时启用 W&B 集成的示例:
curl -X POST \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-d '{
"model": "gpt-4o-mini-2024-07-18",
"training_file": "file-ABC123",
"validation_file": "file-DEF456",
"integrations": [
{
"type": "wandb",
"wandb": {
"project": "custom-wandb-project",
"tags": ["project:tag", "lineage"]
}
}
]
}' https://api.openai.com/v1/fine_tuning/jobs
默认情况下,运行 ID 和运行显示名称是您微调作业的 ID(例如,ftjob-abc123)。您可以通过在 wandb 对象中包含一个 "name" 字段来自定义运行的显示名称。您还可以在 wandb 对象中包含一个 "tags" 字段以向 W&B 运行添加标签(标签必须是 <= 64 个字符的字符串,并且最多可以有 50 个标签)。
有时,显式设置 W&B 实体 与运行关联是很方便的。您可以通过在 wandb 对象中包含一个 "entity" 字段来实现这一点。如果您不包含 "entity" 字段,W&B 实体将默认为与您之前注册的 API 密钥关联的默认 W&B 实体。
完整的集成规范可以在我们的微调作业创建文档中找到。
在 Weights and Biases 中查看您的微调作业
一旦您启用了 W&B 集成创建了微调作业,您可以通过导航到作业创建请求中指定的 W&B 项目来在 W&B 中查看作业。您的运行应位于以下 URL:
https://wandb.ai/<WANDB-ENTITY>/<WANDB-PROJECT>/runs/ftjob-ABCDEF
您应该会看到一个新的运行,其名称和标签与您在作业创建请求中指定的名称和标签相匹配。运行配置将包含相关的作业元数据,例如:
model: 你正在微调的模型training_file:训练文件的IDvalidation_file: 验证文件的 ID超参数:用于作业的超参数(例如n_epochs,learning_rate_multiplier,batch_size)seed: 用于作业的随机种子
同样,OpenAI 将在运行时设置一些默认标签,以便您更容易进行搜索和筛选。这些标签将以前缀 "openai/" 开头,并将包括:
openai/fine-tuning:标签,用于告知您这次运行是一个微调作业openai/ft-abc123:微调作业的IDopenai/gpt-4o-mini:您正在微调的模型
以下是一个从 OpenAI 精调作业生成的 W&B 运行示例:
每个微调作业步骤的指标将被记录到W&B运行中。这些指标与微调作业事件对象中提供的指标相同,也是您可以通过OpenAI微调仪表板查看的指标。
您可以使用W&B的可视化工具来跟踪您的微调作业进度,并将其与其他您已运行的微调作业进行比较。
以下是一个将指标记录到W&B运行的示例:
FAQ
在什么情况下我应该使用微调与嵌入/检索增强生成?
嵌入与检索最适合于需要拥有包含相关上下文和信息的庞大文档数据库的情况。
默认情况下,OpenAI 的模型是训练成有用的通用助手。微调可以用来制作一个专注于特定领域并且表现出特定固有行为模式的模型。检索策略可以通过在生成响应之前为模型提供相关上下文来使新信息可用于模型。检索策略不是微调的替代品,实际上它可以与微调互补。
我如何知道我的微调模型实际上比基础模型更好?
我们建议使用 Evals 产品来创建一个针对您特定用例的评估。
我能否继续微调一个已经微调过的模型?
是的,您可以在创建微调作业时将已微调模型的名称传递给 model 参数。这将使用微调模型作为起点启动一个新的微调作业。
如何估算微调模型的成本?
请参阅上方的估算成本部分。
我一次可以运行多少个微调任务?
请参考我们的速率限制页面获取最新关于限制的信息。
模型蒸馏
使用蒸馏技术提升较小模型的效果。
https://platform.openai.com/docs/guides/distillation
模型蒸馏允许您利用大型模型的输出对较小的模型进行微调,使其在特定任务上实现类似的表现。此过程可以显著降低成本和延迟,因为较小的模型通常更高效。
这里是如何工作的:
- 使用 Chat Completions API 中的
store参数将大模型的优质输出存储起来。 - 评估 存储的完成内容,使用大模型和小模型以建立基线。
- 选择您想要用于蒸馏的已存储补全内容,并使用它们来微调较小的模型。
- 评估微调模型的性能,以查看其与大型模型的比较情况。
让我们一步步来看如何完成这个过程。
存储大型模型的高质量输出
蒸馏过程的第一步是使用像 o1-preview 或 gpt-4o 这样的大型模型生成满足您标准的好结果。在生成这些结果时,您可以使用 Chat Completions API 中的 store: true 选项来存储它们。我们还建议您使用 metadata 属性来标记这些完成项,以便稍后轻松筛选。
然后可以在 仪表板 中查看和筛选这些存储的完成项。
存储大型模型的高质量输出
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: "You are a corporate IT support expert." },
{ role: "user", content: "How can I hide the dock on my Mac?"},
],
store: true,
metadata: {
role: "manager",
department: "accounting",
source: "homepage"
}
});
console.log(response.choices[0]);
当使用 store: true 选项时,补全内容将存储30天。您的补全内容可能包含敏感信息,因此,您可能想要考虑创建一个新的 项目 以限制访问来存储这些补全内容。
建立基线进行评估
您可以使用存储的完成度来评估较大模型和较小模型在您任务上的表现,从而建立基线。这可以通过使用 evals 产品来完成。
通常,较大模型在您的评估中会优于较小模型。建立这个基线允许您衡量通过蒸馏/微调过程获得的改进。
创建训练数据集 以微调较小模型
接下来,您可以选择存储的完成内容的一部分,将其用作微调较小模型(如 gpt-4o-mini)的训练数据。过滤您的存储完成内容 以您希望用于训练小模型的内容,然后点击“提炼”按钮。几百个样本可能足够,但有时更广泛的数千个样本范围可以产生更好的结果。

此操作将打开一个对话框以开始 微调作业,并使用您选择的完成作为训练数据集。根据需要配置参数,选择您想要微调的基础模型。在此示例中,我们将选择 GPT-4o-mini 的最新快照。
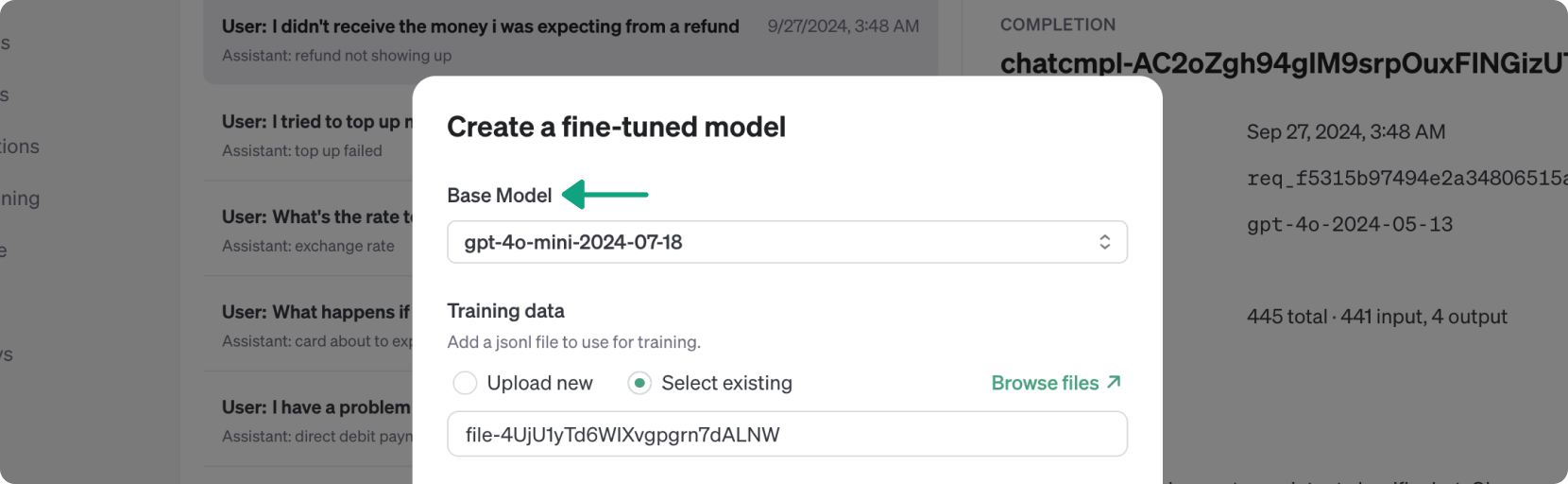
配置完成后,点击 Run 开始微调作业。该过程可能需要 15 分钟或更长时间,具体取决于训练数据集的大小。
评估微调的小型模型
当您的微调作业完成后,您可以运行评估来查看它与基础小型和大型模型的性能对比。您可以在 评估 产品中选择微调模型,以使用微调的小型模型生成新的补全内容。
检索
使用语义相似性搜索您的数据。
https://platform.openai.com/docs/guides/retrieval
检索 API 允许您在您的数据上执行 语义搜索,这是一种呈现语义相似结果的技术——即使它们匹配的关键词很少或没有。检索本身很有用,但与我们的模型结合使用时尤其强大。
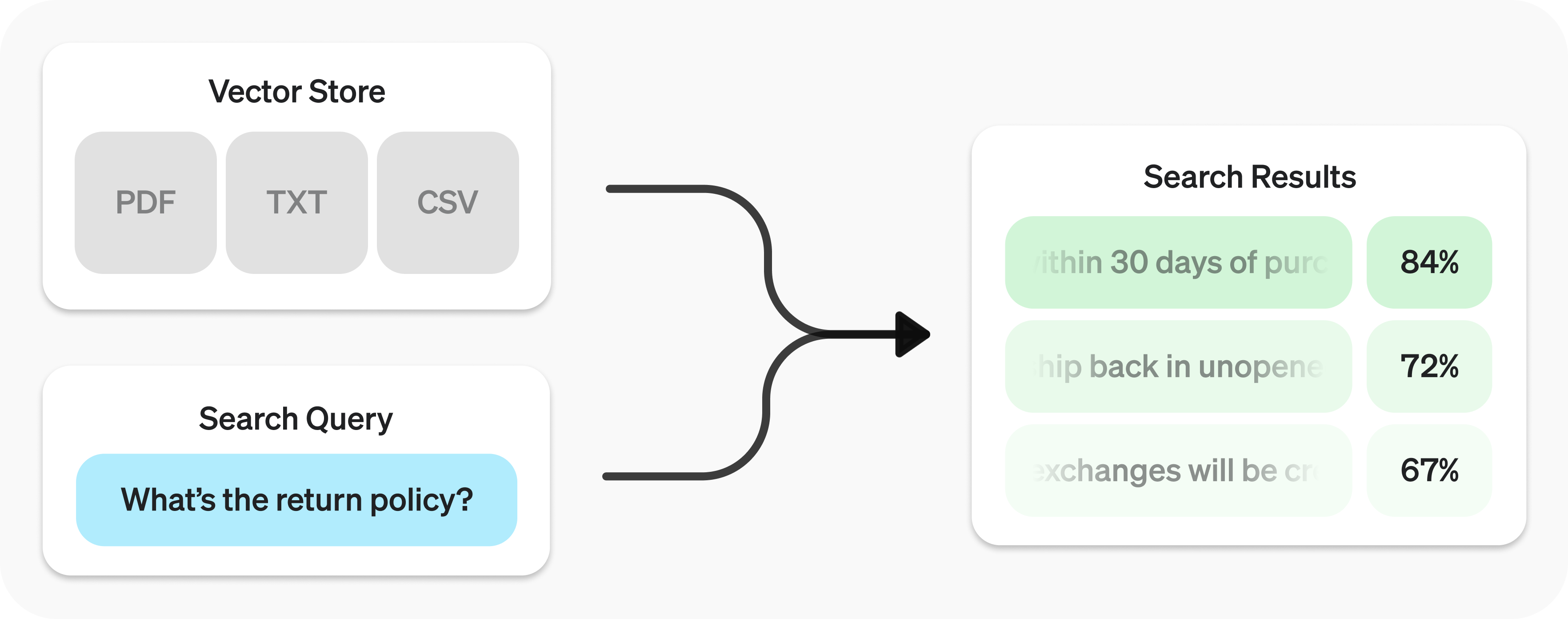
检索API由向量存储提供支持,这些存储作为您数据的索引。本指南将涵盖如何执行语义搜索,并详细介绍向量存储的细节。
快速入门
创建向量存储并上传文件。
使用文件创建向量存储
from openai import OpenAI
client = OpenAI()
vector_store = client.vector_stores.create( # Create vector store
name="Support FAQ",
)
client.vector_stores.files.upload_and_poll( # Upload file
vector_store_id=vector_store.id,
file=open("customer_policies.txt", "rb")
)
发送搜索查询以获取相关结果。
搜索查询
user_query = "What is the return policy?"
results = client.vector_stores.search(
vector_store_id=vector_store.id,
query=user_query,
)
要了解如何使用我们的模型处理结果,请查看合成响应部分。
语义搜索
语义搜索是一种利用向量嵌入技术来展示语义相关结果的技巧。重要的是,这包括具有少量或没有共享关键词的结果,这些结果可能是经典搜索技术所遗漏的。
例如,让我们看看对于查询“我们什么时候去了月球?”的潜在结果:
| 文本 | 关键词相似度 | 语义相似度 |
|---|---|---|
| 第一次登月发生在1969年7月。 | 0% | 65% |
| 第一位登上月球的人是尼尔·阿姆斯特朗。 | 27% | 43% |
| 我吃月饼的时候,它很美味。 | 40% | 28% |
(Jaccard用于关键词,余弦与text-embedding-3-small用于语义。)
注意,最相关的结果不包含搜索查询中的任何单词。这种灵活性使得语义搜索成为查询任何规模知识库的非常强大的技术。
语义搜索由向量存储提供支持,我们将在指南的后面部分详细介绍。本节将专注于语义搜索的机制。
执行语义搜索
您可以使用 search 函数查询向量存储,并指定一个自然语言的 query。这将返回一个结果列表,每个结果都包含相关的片段、相似度得分和来源文件。
搜索查询
results = client.vector_stores.search(
vector_store_id=vector_store.id,
query="How many woodchucks are allowed per passenger?",
)
Results
{
object: "vector_store.search_results.page",
search_query: "How many woodchucks are allowed per passenger?",
data: [
{
file_id: "file-12345",
filename: "woodchuck_policy.txt",
score: 0.85,
attributes: {
"region": "North America",
"author": "Wildlife Department"
},
content: [
{
type: "text",
text: "According to the latest regulations, each passenger is allowed to carry up to two woodchucks."
},
{
type: "text",
text: "Ensure that the woodchucks are properly contained during transport."
}
]
},
{
file_id: "file-67890",
filename: "transport_guidelines.txt",
score: 0.75,
attributes: {
"region": "North America",
"author": "Transport Authority"
},
content: [
{
type: "text",
text: "Passengers must adhere to the guidelines set forth by the Transport Authority regarding the transport of woodchucks."
}
]
}
],
has_more: false,
next_page: null
}
默认情况下,一个响应将包含最多10个结果,但您可以使用max_num_results参数设置最多50个。
查询重写
某些查询风格会产生更好的结果,因此我们提供了一个设置来自动重写您的查询以获得最佳性能。通过在执行 search 时设置 rewrite_query=true 来启用此功能。
重写后的查询将在结果的 search_query 字段中可用。
| 原始 | 重写 |
|---|---|
| 我想知道主办公楼的身高。 | primary office building height |
| 运输危险材料的安全生产法规是什么? | safety regulations for hazardous materials |
| 我该如何提交关于服务问题的投诉? | service complaint filing process |
属性过滤
属性过滤有助于通过应用标准来缩小结果范围,例如限制搜索到特定的日期范围。您可以在 attribute_filter 中定义和组合标准,以便在执行语义搜索之前根据文件的属性定位文件。
使用 比较过滤器 来比较文件 attributes 中的特定 key 与给定的 value,并使用 复合过滤器 通过 and 和 or 组合多个过滤器。
比较过滤器
{
"type": "eq" | "ne" | "gt" | "gte" | "lt" | "lte", // comparison operators
"property": "attributes_property", // attributes property
"value": "target_value" // value to compare against
}
复合过滤器
{
"type": "and" | "or", // logical operators
"filters": [...]
}
以下是一些示例过滤器。
Region
筛选区域
{
"type": "eq",
"property": "region",
"value": "us"
}
日期范围
日期范围过滤器
{
"type": "and",
"filters": [
{
"type": "gte",
"property": "date",
"value": 1704067200 // unix timestamp for 2024-01-01
},
{
"type": "lte",
"property": "date",
"value": 1710892800 // unix timestamp for 2024-03-20
}
]
}
Filenames
过滤以匹配一组文件名
{
"type": "or",
"filters": [
{
"type": "eq",
"property": "filename",
"value": "example.txt"
},
{
"type": "eq",
"property": "filename",
"value": "example2.txt"
}
]
}
Complex
筛选具有特定英文名称的秘密项目
{
"type": "or",
"filters": [
{
"type": "and",
"filters": [
{
"type": "or",
"filters": [
{ "type": "eq", "property": "project_code", "value": "X123" },
{ "type": "eq", "property": "project_code", "value": "X999" }
]
},
{
"type": "eq",
"property": "confidentiality",
"value": "top_secret"
}
]
},
{
"type": "eq",
"property": "language",
"value": "en"
}
]
}
排名
如果您发现文件搜索结果不够相关,您可以调整 ranking_options 来提高响应质量。这包括指定一个 ranker,例如 auto 或 default-2024-08-21,并设置一个介于 0.0 和 1.0 之间的 score_threshold。较高的 score_threshold 将限制结果到更相关的片段,尽管可能会排除一些可能有用的片段。
向量存储
向量存储是支持检索 API 和助手 API 文件搜索 工具语义搜索的容器。当您将文件添加到向量存储中时,它将被自动分割、嵌入和索引。
向量存储包含 vector_store_file 对象,这些对象由 file 对象支持。
| 对象类型 | 描述 |
|---|---|
file | 代表通过 文件 API 上传的内容。通常与向量存储一起使用,但也用于微调和其他用例。 |
vector_store | 可搜索文件的容器。 |
vector_store.file | 特定表示已分割和嵌入,并与 vector_store 关联的 file 的包装类型。包含用于过滤的 attributes 映射。 |
定价
您将被根据您所有矢量存储中的总存储使用量收费,这取决于解析块的大小及其相应的嵌入。
| 存储 | 费用 |
|---|---|
| 不超过1 GB(所有存储总计) | 免费 |
| 超过1 GB | 0.10美元/GB/天 |
查看过期政策,了解降低成本的选择。
向量存储操作
创建
创建向量存储
client.vector_stores.create(
name="Support FAQ",
file_ids=["file_123"]
)
Retrieve
检索向量存储
client.vector_stores.retrieve(
vector_store_id="vs_123"
)
Update
更新向量存储
client.vector_stores.update(
vector_store_id="vs_123",
name="Support FAQ Updated"
)
Delete
删除向量存储
client.vector_stores.delete(
vector_store_id="vs_123"
)
List
列表向量存储
client.vector_stores.list()
向量存储文件操作
某些操作,如 vector_store.file 的 create,是异步的,可能需要一些时间才能完成——使用我们的辅助函数,如 create_and_poll,以阻塞直到它完成。否则,您可以检查状态。
创建
创建向量存储文件
client.vector_stores.files.create_and_poll(
vector_store_id="vs_123",
file_id="file_123"
)
Upload
上传矢量存储文件
client.vector_stores.files.upload_and_poll(
vector_store_id="vs_123",
file=open("customer_policies.txt", "rb")
)
Retrieve
检索向量存储文件
client.vector_stores.files.retrieve(
vector_store_id="vs_123",
file_id="file_123"
)
Update
更新向量存储文件
client.vector_stores.files.update(
vector_store_id="vs_123",
file_id="file_123",
attributes={"key": "value"}
)
Delete
删除向量存储文件
client.vector_stores.files.delete(
vector_store_id="vs_123",
file_id="file_123"
)
List
列表向量存储文件
client.vector_stores.files.list(
vector_store_id="vs_123"
)
批量操作
创建
批量创建操作
client.vector_stores.file_batches.create_and_poll(
vector_store_id="vs_123",
file_ids=["file_123", "file_456"]
)
Retrieve
批量检索操作
client.vector_stores.file_batches.retrieve(
vector_store_id="vs_123",
batch_id="vsfb_123"
)
Cancel
批量取消操作
client.vector_stores.file_batches.cancel(
vector_store_id="vs_123",
batch_id="vsfb_123"
)
List
批处理列表操作
client.vector_stores.file_batches.list(
vector_store_id="vs_123"
)
属性
每个 vector_store.file 都可以关联 attributes,这是一个值字典,当进行带有 属性过滤 的 语义搜索 时可以引用。该字典最多可以有16个键,每个键的长度限制为256个字符。
创建具有属性的向量存储文件
client.vector_stores.files.create(
vector_store_id="vs_123",
file_id="file_123",
attributes={
"region": "US",
"category": "Marketing",
"date": 1672531200 # Jan 1, 2023
}
)
过期策略
您可以使用 expires_after 在 vector_store 对象上设置过期策略。一旦向量存储过期,所有相关的 vector_store.file 对象将被删除,并且您将不再为此类对象付费。
设置向量存储的过期策略
client.vector_stores.update(
vector_store_id="vs_123",
expires_after={
"anchor": "last_active_at",
"days": 7
}
)
限制
最大文件大小为 512 MB。每个文件应包含不超过 5,000,000 个标记(在您附加文件时自动计算)。
分块处理
默认情况下,max_chunk_size_tokens 设置为 800,chunk_overlap_tokens 设置为 400,这意味着每个文件通过分割成 800 个 token 的大块进行索引,连续块之间有 400 个 token 的重叠。
您可以通过在向向量存储添加文件时设置 chunking_strategy 来调整这些设置。chunking_strategy 存在一些限制:
max_chunk_size_tokens必须在 100 到 4096 之间(包括两端)。chunk_overlap_tokens必须是非负数,且不应超过max_chunk_size_tokens / 2。
支持的文件类型
对于 text/ MIME 类型,编码必须是 utf-8、utf-16 或 ascii 之一.
| 文件格式 | MIME 类型 |
|---|---|
.c | text/x-c |
.cpp | text/x-c++ |
.cs | text/x-csharp |
.css | text/css |
.doc | application/msword |
.docx | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
.go | text/x-golang |
.html | text/html |
.java | text/x-java |
.js | text/javascript |
.json | application/json |
.md | text/markdown |
.pdf | application/pdf |
.php | text/x-php |
.pptx | application/vnd.openxmlformats-officedocument.presentationml.presentation |
.py | text/x-python |
.py | text/x-script.python |
.rb | text/x-ruby |
.sh | application/x-sh |
.tex | text/x-tex |
.ts | application/typescript |
.txt | text/plain |
综合响应
在执行查询后,您可能希望根据结果综合出一个响应。您可以通过提供结果和原始查询来利用我们的模型做到这一点,从而得到一个基于事实的响应。
执行搜索查询以获取结果
from openai import OpenAI
client = OpenAI()
user_query = "What is the return policy?"
results = client.vector_stores.search(
vector_store_id=vector_store.id,
query=user_query,
)
基于结果综合回复
formatted_results = format_results(results.data)
'\n'.join('\n'.join(c.text) for c in result.content for result in results.data)
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "developer",
"content": "Produce a concise answer to the query based on the provided sources."
},
{
"role": "user",
"content": f"Sources: {formatted_results}\n\nQuery: '{user_query}'"
}
],
)
print(completion.choices[0].message.content)
"Our return policy allows returns within 30 days of purchase."
这使用了一个示例 format_results 函数,该函数可以像这样实现:
样本结果格式化函数
def format_results(results):
formatted_results = ''
for result in results.data:
formatted_result = f"<result file_id='{result.file_id}' file_name='{result.file_name}'>"
for part in result.content:
formatted_result += f"<content>{part.text}</content>"
formatted_results += formatted_result + "</result>"
return f"<sources>{formatted_results}</sources>"
评估模型性能Beta
通过评估来测试和改进模型输出。
https://platform.openai.com/docs/guides/evals
评估(通常称为evals)通过确保您使用模型生成的结果满足您指定的准确性标准,帮助您开发高质量的LLM应用程序。类似于为传统软件设置单元测试,为您的应用程序设置良好的评估让您能够更有信心地尝试新模型并在提示上迭代。
The Evaulations tooling 在 OpenAI 仪表板中可以帮助您创建和运行针对您应用程序的评估。在本指南中,您将了解评估在一般情况下的工作原理,以及如何使用仪表板中的评估工具来测试您的提示和 LLM 输出。
https://cdn.openai.com/API/docs/evals.mp4
理解你的目标
在开始之前,你应该了解你希望模型表现出的行为。以下是一些你应该能够回答的问题:
- 我希望模型生成什么样的输出?
- 模型应该能够处理哪些类型的输入?
- 我如何判断我的模型输出是否准确?
这些问题的答案将决定你如何构建评估,以及你在评估模型性能之前需要组装哪些类型的数据。让我们通过一个真实的例子来使这个问题更加具体。
示例目标 - 电影评论情感分析
假设您正在构建一个用于对IMDB的电影评论进行情感分析的LLM应用程序。您希望给模型提供电影评论的文本,如果它是正面评论,则输出1,如果是负面评论,则输出0。对于这个用例,让我们回答上述三个问题:
我希望模型生成什么样的输出?
在这种情况下,您希望模型只为正面评论生成1,为负面评论生成0。您不希望模型生成除这两个数字之外的其他内容。
模型应该能够处理哪些类型的输入?
模型应该能够处理用户生成的电影评论文本。根据评论的文本,模型应该能够判断评论的整体语气是正面还是负面。为了测试目的,我们将假设所有待测试的评论都是英文。
我如何判断我的模型输出是否准确?
我们可以通过几种潜在的方式来判断模型输出是否准确:
- 我们可以要求另一个(理想情况下更大或更强大的)模型分析相同的评论。如果其他模型同意我们模型的输出,那可能是一个成功的强烈指标。
- 我们可以将模型输出与同一评论上由人类创建的输出进行比较,我们可以相信这是准确的。人工标记的数据可以被认为是真实情况,这是我们想要测试我们的模型输出与之相比的现实。
第二个选项可能更准确——所以如果我们有能力以人工标记的数据作为我们的真实情况来测试,那可能是一个更好的选择。当没有人工标记的数据时,模型评分输出可能是有用的。
现在,我们已经明确了我们希望模型生成的内容,我们想要测试的输入类型,以及我们如何知道输出是否准确,我们可以继续收集我们评估所需的数据。
组装测试数据
获取良好的测试数据输入可以说是构建评估中最困难的部分。这是因为良好的测试数据必须能够代表模型在生产中接收到的各种输入。
以我们的电影评论用例为例。如果我们的所有测试用例都是由同一个人写的负面评论,那么这将不是一个很好的测试数据集。我们理想情况下希望正面和负面评论的比例与现实观察到的比例相匹配,并且由不同作者撰写。
在生成测试数据集时,你有几种选择:
- 你可以找到一个与你的用例相匹配的现有开源数据集
- 你可以创建一个合成数据集,既可以由人类也可以由模型生成满足你规格的测试输入
- 你可以从你的应用程序的实际生产使用中创建一个数据集
第三种选择是最理想的,因为它很可能与你的应用程序将面临的现实相类似。如果你已经在使用 OpenAI,你可能考虑使用 存储完成内容 来处理你的 API 流量。将 store: true 设置在完成内容上会让它们显示在 仪表板这里,在那里你可以过滤它们以创建用于评估、微调 或 蒸馏 的数据集。
在 API 中存储带有元数据的完成内容
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: "You are a corporate IT support expert." },
{ role: "user", content: "How can I hide the dock on my Mac?"},
],
store: true,
metadata: {
role: "manager",
department: "accounting",
source: "homepage"
}
});
console.log(response.choices[0]);
对于本指南的目的,然而,我们将使用来自 Hugging Face 的 开源数据集。您可以从这里下载 数据的 CSV 版本。
此数据集包含两列 - 评论的 text 和一个 label,该 label 要么是 0,要么是 1,分别表示评论是负面还是正面。数据看起来如下所示:
text,label
"I love sci-fi and am willing...",0
"Worth the entertainment value ...",1
"its a totally average film ...",0
在这个案例中,测试数据包含了模型的测试输入,以及我们为评论内容设定的真实标签。现在我们有了包含真实标签的评估数据集,我们可以生成模型输出进行测试。
生成模型输出
接下来,您需要定义将用于生成模型输出的提示,该提示基于您测试数据集中的数据输入。此提示的输出将在您的评估运行期间按准确性和质量进行评分。
对于电影评论用例,我们将使用如下所示的提示:
系统消息
You are an expert in analyzing the sentiment of movie reviews.
- If the movie review is positive, you will output a 1
- If the movie review is negative, you will output a 0
- Only output 1 or 0 as a response - do not output any other text
用户消息
Determine if the following review is positive or negative:
<review text here>
使用上面配置的测试数据和提示,我们准备好在仪表板上配置和运行一个评估了!
设置并运行您的评估
所有配料都已准备就绪,我们现在可以设置并运行我们的评估,在 OpenAI API 仪表板中。前往 评估页面 并点击 创建。有几个选项可以帮助您设置评估,但让我们选择 自定义 选项,从头开始设置一切。
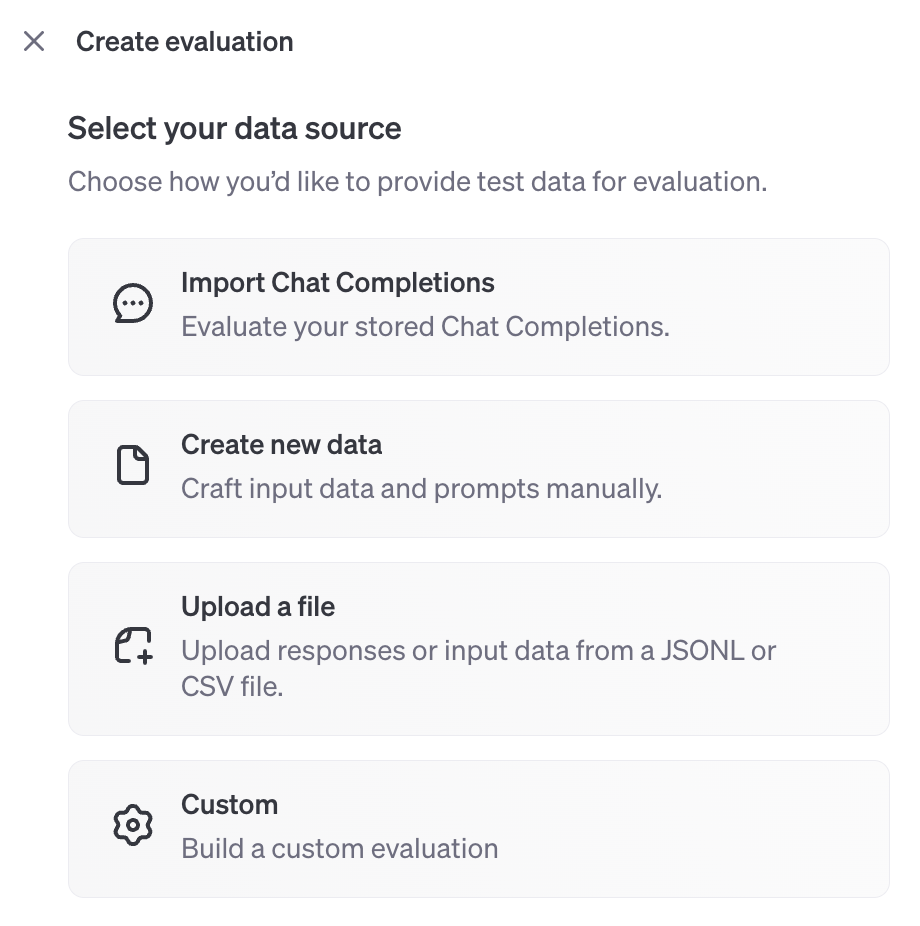
在您创建新的自定义评估后,给该评估起一个名字,然后上传从此处获取的IMDB电影评论数据的[CSV版本]。数据上传位于 测试数据 标题下。
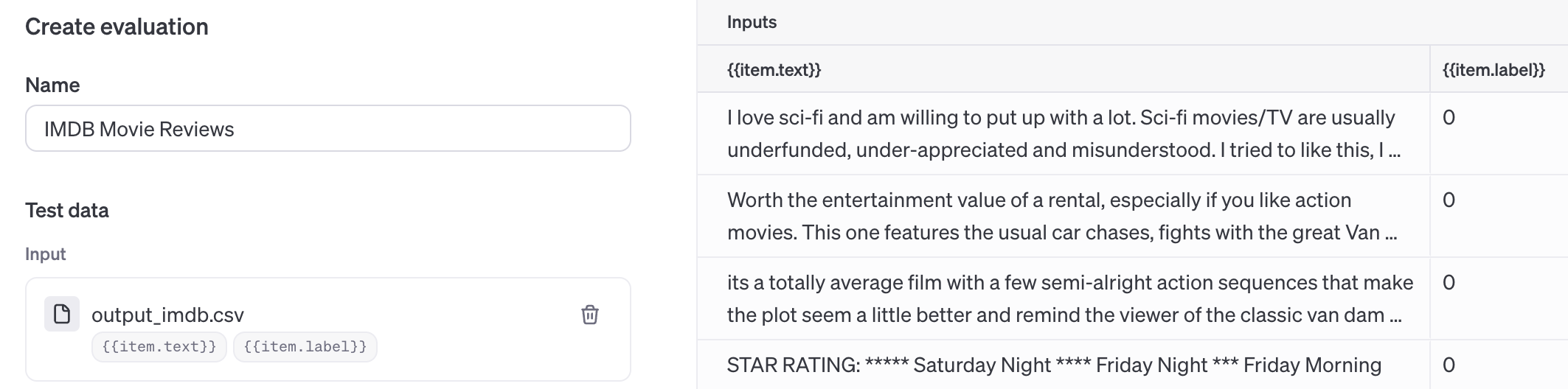
接下来,我们将配置我们想要使用的提示,以生成要测试的模型输出。在 响应 标题下,使用上面显示的系统消息和用户消息来为每个测试案例生成模型输出。{{ item.text }} 表达式将替换你数据文件CSV中 text 列的值。
您可以使用您喜欢的任何OpenAI模型生成响应。
最后,我们需要在 测试标准 标题下配置评估的测试标准。这些标准将用于确定我们的模型输出是否符合预期。
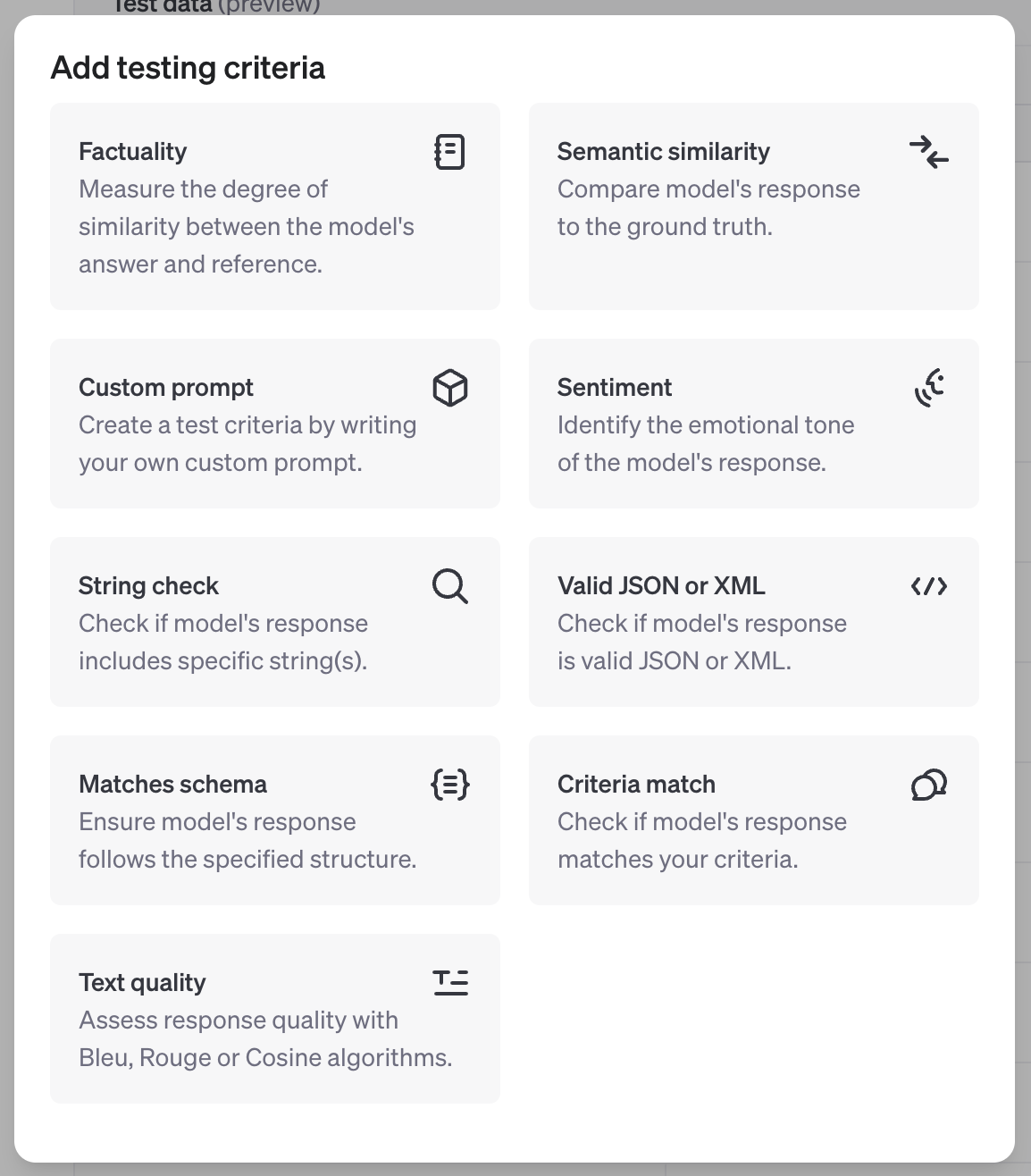
以下是翻译结果:
您可以选择多个评分器,例如评估文本质量或从提示中创建自定义模型评分器。在这种情况下,我们想要测试模型的输出与一个真实的输出(要么是 0 要么是 1)进行对比。对于这种比较,我们可以使用 字符串检查 评分器。
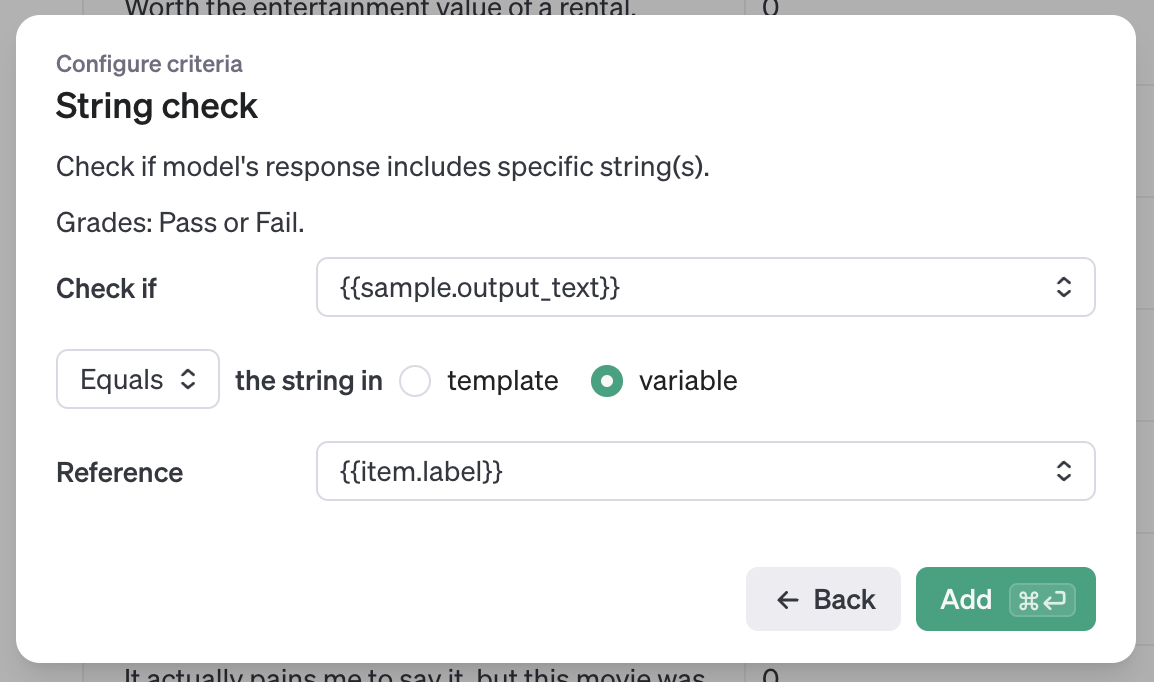
在本标准中,我们将确保模型输出与我们的真实值匹配。
{{ sample.output_text }}- 模型的输出{{ item.label }}- 数据集中的真实标签
当您的评估配置成功后,您可以按下 运行 按钮来运行评估!
根据数据集的大小,您的评估可能会在后台运行相当长一段时间。完成前,您可以离开评估页面。运行完成后,您可以在仪表板中查看结果:
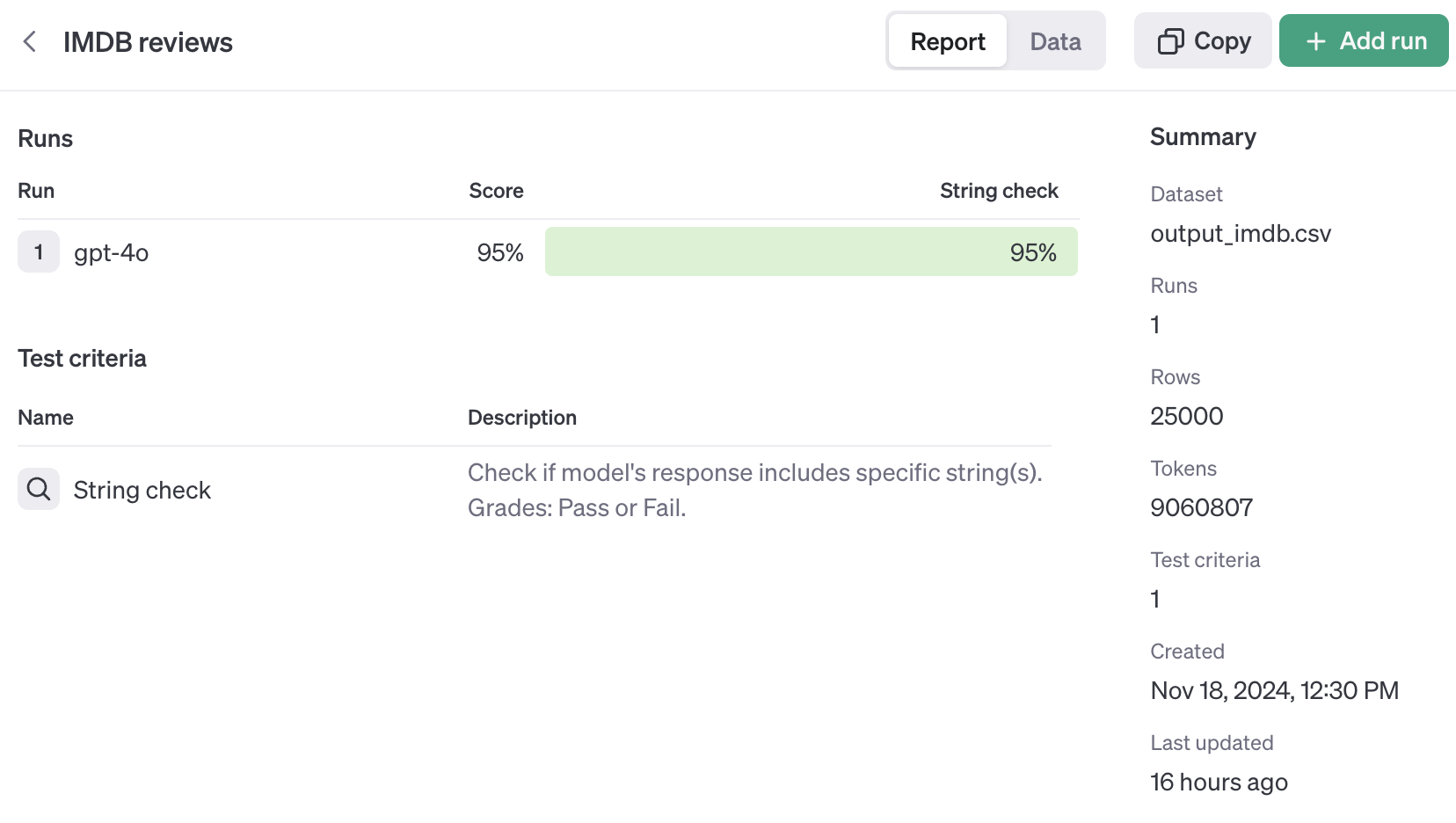
您可以深入数据以查看哪些检查失败,并通过清理测试数据(可能是一些评论被错误地标记了)或尝试改进提示来调试结果。
很快,你将成为一个专家,能够确定你的LLM应用是否产生了你预期的输出。
批量 API
使用批量 API 异步处理作业。
https://platform.openai.com/docs/guides/batch
学习如何使用 OpenAI 的批量 API 以降低 50% 的成本发送异步请求组,一个显著更高的速率限制池,以及清晰的 24 小时周转时间。该服务非常适合处理不需要即时响应的工作。您还可以直接在此处探索 API 参考。
概述
虽然使用 OpenAI 平台的一些用例需要您发送同步请求,但有许多情况下请求不需要立即响应,或者 速率限制 阻止您快速执行大量查询。批量处理作业在以下用例中通常很有帮助:
- 运行评估
- 对大型数据集进行分类
- 嵌入内容存储库
批量 API 提供了一套直观的端点,允许您将一组请求收集到一个单独的文件中,启动一个批量处理作业以执行这些请求,在底层请求执行期间查询该批次的状况,并在批次完成后最终检索收集到的结果。
与直接使用标准端点相比,批量 API 具有以下优势:
- 更好的成本效益: 相比同步 API,提供 50% 的成本折扣
- 更高的速率限制: 大幅增加的可用空间 相比同步 API
- 快速完成时间: 每个批次在 24 小时内完成(并且通常更快)
入门
1. 准备您的批处理文件
批处理从包含单个请求到API的详细信息的 .jsonl 文件开始。目前可用的端点是 /v1/responses (响应API), /v1/chat/completions (聊天完成API), /v1/embeddings (嵌入API), 和 ‘/v1/completions’ (完成API)。对于给定的输入文件,每行 body 字段中的参数与底层端点的参数相同。每个请求都必须包含一个唯一的 custom_id 值,您可以使用该值在完成后引用结果。以下是一个包含2个请求的输入文件示例。请注意,每个输入文件只能包含对单个模型的请求。
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-3.5-turbo-0125", "messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Hello world!"}],"max_tokens": 1000}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-3.5-turbo-0125", "messages": [{"role": "system", "content": "You are an unhelpful assistant."},{"role": "user", "content": "Hello world!"}],"max_tokens": 1000}}
2. 上传您的批处理输入文件
类似于我们的 微调 API,您首先需要上传您的输入文件,以便在启动批处理时能够正确引用。使用 文件 API 上传您的 .jsonl 文件。
上传批处理 API 文件
from openai import OpenAI
client = OpenAI()
batch_input_file = client.files.create(
file=open("batchinput.jsonl", "rb"),
purpose="batch"
)
print(batch_input_file)
3. 创建批次
一旦您成功上传了您的输入文件,您可以使用输入文件对象的 ID 来创建一个批次。在这种情况下,让我们假设文件 ID 是 file-abc123。目前,完成窗口只能设置为 24h。您还可以通过可选的 metadata 参数提供自定义元数据。
创建批次
from openai import OpenAI
client = OpenAI()
batch_input_file_id = batch_input_file.id
client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "nightly eval job"
}
)
此请求将返回一个 批处理对象 ,其中包含有关您的批处理的元数据:
{
"id": "batch_abc123",
"object": "batch",
"endpoint": "/v1/chat/completions",
"errors": null,
"input_file_id": "file-abc123",
"completion_window": "24h",
"status": "validating",
"output_file_id": null,
"error_file_id": null,
"created_at": 1714508499,
"in_progress_at": null,
"expires_at": 1714536634,
"completed_at": null,
"failed_at": null,
"expired_at": null,
"request_counts": {
"total": 0,
"completed": 0,
"failed": 0
},
"metadata": null
}
4. 检查批次状态
您可以在任何时候检查批次状态,这也会返回一个批次对象。
检查批次状态
from openai import OpenAI
client = OpenAI()
const batch = client.batches.retrieve("batch_abc123")
print(batch)
The status of a given Batch object can be any of the following:
| 状态 | 描述 |
|---|---|
validating | 在批量开始之前正在验证输入文件 |
failed | 输入文件未通过验证过程 |
in_progress | 输入文件已成功验证,批处理目前正在运行 |
finalizing | 批次已完成且结果正在准备中 |
completed | 批次已完成,结果已准备好 |
expired | 批次未能在大致 24 小时的时间窗口内完成 |
cancelling | 批次正在被取消(可能需要10分钟) |
cancelled | 批次已取消 |
5. 获取结果
一旦批次完成,您可以通过对 Files API 发送请求,使用批次的 output_file_id 字段,并将结果写入您机器上的文件,在这种情况下为 batch_output.jsonl,来下载输出。
获取批次结果
from openai import OpenAI
client = OpenAI()
file_response = client.files.content("file-xyz123")
print(file_response.text)
输出 .jsonl 文件将为输入文件中的每一条成功请求行包含一个响应行。批次中的任何失败请求都将其错误信息写入一个错误文件,可以通过批次的 error_file_id 找到该错误文件。
请注意,输出行的顺序可能不匹配输入行的顺序。不要依赖于顺序来处理您的结果,而是使用每个输出行中都会出现的 custom_id 字段,这将允许您将输入中的请求映射到输出中的结果。
{"id": "batch_req_123", "custom_id": "request-2", "response": {"status_code": 200, "request_id": "req_123", "body": {"id": "chatcmpl-123", "object": "chat.completion", "created": 1711652795, "model": "gpt-3.5-turbo-0125", "choices": [{"index": 0, "message": {"role": "assistant", "content": "Hello."}, "logprobs": null, "finish_reason": "stop"}], "usage": {"prompt_tokens": 22, "completion_tokens": 2, "total_tokens": 24}, "system_fingerprint": "fp_123"}}, "error": null}
{"id": "batch_req_456", "custom_id": "request-1", "response": {"status_code": 200, "request_id": "req_789", "body": {"id": "chatcmpl-abc", "object": "chat.completion", "created": 1711652789, "model": "gpt-3.5-turbo-0125", "choices": [{"index": 0, "message": {"role": "assistant", "content": "Hello! How can I assist you today?"}, "logprobs": null, "finish_reason": "stop"}], "usage": {"prompt_tokens": 20, "completion_tokens": 9, "total_tokens": 29}, "system_fingerprint": "fp_3ba"}}, "error": null}
6. 取消一个批次
如果需要,您可以取消正在进行的批次。批次的状态将变为 cancelling,直到飞行中的请求完成(最多10分钟),之后状态将变为 cancelled。
取消一个批次
from openai import OpenAI
client = OpenAI()
client.batches.cancel("batch_abc123")
7. 获取所有批次的列表
在任何时候,您都可以查看您所有的批次。对于批次数量较多的用户,您可以使用 limit 和 after 参数来分页您的结果。
获取所有批次的列表
from openai import OpenAI
client = OpenAI()
client.batches.list(limit=10)
模型可用性
Batch API 当前可以用于执行以下模型的查询。Batch API 支持以下模型端点的相同格式进行文本和视觉输入:
o1o3-minigpt-4ogpt-4o-minigpt-4-turbogpt-4gpt-4-32kgpt-4.5-previewgpt-3.5-turbogpt-3.5-turbo-16kgpt-4-turbo-previewgpt-4-vision-previewgpt-4-turbo-2024-04-09gpt-4-0314gpt-4-32k-0314gpt-4-32k-0613gpt-3.5-turbo-0301gpt-3.5-turbo-16k-0613gpt-3.5-turbo-1106gpt-3.5-turbo-0613text-embedding-3-largetext-embedding-3-smalltext-embedding-ada-002
Batch API 还支持 微调模型。
速率限制
批量 API 的速率限制与现有的按模型速率限制分开。批量 API 有两种新的速率限制类型:
- 每批限制:单个批量可以包含最多 50,000 个请求,批量输入文件的大小可达 200 MB。请注意,
/v1/embeddings批量也对所有请求中的嵌入输入量限制在最多 50,000 个。 - 按模型入队提示token :每个模型都有允许批量处理的入队提示token 的最大数量。您可以在 平台设置页面 上找到这些限制。
今天批量 API 对于输出token 或提交请求的数量没有限制。由于批量 API 的速率限制是一个新的、独立的池,**使用批量 API 不会消耗您标准按模型速率限制中的token **,因此为您提供了方便地增加在查询我们的 API 时可以使用的请求数量和处理token 数量的方式。
批量过期
未能按时完成的批次最终会移动到 过期 状态;该批次中的未完成请求将被取消,并对已完成请求的任何响应将通过批次的输出文件提供。您将为任何已完成的请求消耗的token 付费。
过期请求将被写入您的错误文件,如下所示的消息。您可以使用 custom_id 来检索过期请求的请求数据。
{"id": "batch_req_123", "custom_id": "request-3", "response": null, "error": {"code": "batch_expired", "message": "This request could not be executed before the completion window expired."}}
{"id": "batch_req_123", "custom_id": "request-7", "response": null, "error": {"code": "batch_expired", "message": "This request could not be executed before the completion window expired."}}
提示生成
在Playground中生成提示和模式。
https://platform.openai.com/docs/guides/prompt-generation
生成按钮位于Playground中,您可以通过对任务的描述来生成提示、函数和模式。本指南将详细介绍其工作原理。
概述
从头开始创建提示和模式可能非常耗时,因此生成它们可以帮助您快速开始。生成按钮使用两种主要方法:
- 提示: 我们使用元提示,它结合了最佳实践来生成或改进提示。
- 模式: 我们使用元模式,它可以生成有效的 JSON 和函数语法。
虽然我们目前使用元提示和模式,但我们可能在将来集成更高级的技术,如 DSPy 和 “梯度下降”。
提示
元提示指导模型根据您的任务描述创建一个良好的提示,或者改进现有的提示。在游乐场中,元提示借鉴了我们的提示工程最佳实践和与用户的实际经验。
我们使用特定的元提示来针对不同的输出类型,如音频,以确保生成的提示符合预期的格式。
Meta-prompts
文本-输出音频-输出
文本元提示
from openai import OpenAI
client = OpenAI()
META_PROMPT = """
Given a task description or existing prompt, produce a detailed system prompt to guide a language model in completing the task effectively.
# Guidelines
- Understand the Task: Grasp the main objective, goals, requirements, constraints, and expected output.
- Minimal Changes: If an existing prompt is provided, improve it only if it's simple. For complex prompts, enhance clarity and add missing elements without altering the original structure.
- Reasoning Before Conclusions**: Encourage reasoning steps before any conclusions are reached. ATTENTION! If the user provides examples where the reasoning happens afterward, REVERSE the order! NEVER START EXAMPLES WITH CONCLUSIONS!
- Reasoning Order: Call out reasoning portions of the prompt and conclusion parts (specific fields by name). For each, determine the ORDER in which this is done, and whether it needs to be reversed.
- Conclusion, classifications, or results should ALWAYS appear last.
- Examples: Include high-quality examples if helpful, using placeholders [in brackets] for complex elements.
- What kinds of examples may need to be included, how many, and whether they are complex enough to benefit from placeholders.
- Clarity and Conciseness: Use clear, specific language. Avoid unnecessary instructions or bland statements.
- Formatting: Use markdown features for readability. DO NOT USE ```CODE BLOCKS UNLESS SPECIFICALLY REQUESTED.
- Preserve User Content: If the input task or prompt includes extensive guidelines or examples, preserve them entirely, or as closely as possible. If they are vague, consider breaking down into sub-steps. Keep any details, guidelines, examples, variables, or placeholders provided by the user.
- Constants: DO include constants in the prompt, as they are not susceptible to prompt injection. Such as guides, rubrics, and examples.
- Output Format: Explicitly the most appropriate output format, in detail. This should include length and syntax (e.g. short sentence, paragraph, JSON, etc.)
- For tasks outputting well-defined or structured data (classification, JSON, etc.) bias toward outputting a JSON.
- JSON should never be wrapped in code blocks (```) unless explicitly requested.
The final prompt you output should adhere to the following structure below. Do not include any additional commentary, only output the completed system prompt. SPECIFICALLY, do not include any additional messages at the start or end of the prompt. (e.g. no "---")
[Concise instruction describing the task - this should be the first line in the prompt, no section header]
[Additional details as needed.]
[Optional sections with headings or bullet points for detailed steps.]
# Steps [optional]
[optional: a detailed breakdown of the steps necessary to accomplish the task]
# Output Format
[Specifically call out how the output should be formatted, be it response length, structure e.g. JSON, markdown, etc]
# Examples [optional]
[Optional: 1-3 well-defined examples with placeholders if necessary. Clearly mark where examples start and end, and what the input and output are. User placeholders as necessary.]
[If the examples are shorter than what a realistic example is expected to be, make a reference with () explaining how real examples should be longer / shorter / different. AND USE PLACEHOLDERS! ]
# Notes [optional]
[optional: edge cases, details, and an area to call or repeat out specific important considerations]
""".strip()
def generate_prompt(task_or_prompt: str):
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Task, Goal, or Current Prompt:\n" + task_or_prompt,
},
],
)
return completion.choices[0].message.content
提示编辑
要编辑提示,我们使用略微修改过的元提示。虽然直接编辑应用起来很简单,但确定更开放性修订所需的必要更改可能具有挑战性。为了解决这个问题,我们在响应的开头包含一个 推理部分。这个部分帮助模型通过评估现有提示的清晰度、思维链的顺序、整体结构和具体性等因素,来确定需要哪些更改。推理部分提出改进建议,然后从最终响应中解析出来。
文本输出音频输出
编辑的文本元提示
from openai import OpenAI
client = OpenAI()
META_PROMPT = """
Given a current prompt and a change description, produce a detailed system prompt to guide a language model in completing the task effectively.
Your final output will be the full corrected prompt verbatim. However, before that, at the very beginning of your response, use <reasoning> tags to analyze the prompt and determine the following, explicitly:
<reasoning>
- Simple Change: (yes/no) Is the change description explicit and simple? (If so, skip the rest of these questions.)
- Reasoning: (yes/no) Does the current prompt use reasoning, analysis, or chain of thought?
- Identify: (max 10 words) if so, which section(s) utilize reasoning?
- Conclusion: (yes/no) is the chain of thought used to determine a conclusion?
- Ordering: (before/after) is the chain of though located before or after
- Structure: (yes/no) does the input prompt have a well defined structure
- Examples: (yes/no) does the input prompt have few-shot examples
- Representative: (1-5) if present, how representative are the examples?
- Complexity: (1-5) how complex is the input prompt?
- Task: (1-5) how complex is the implied task?
- Necessity: ()
- Specificity: (1-5) how detailed and specific is the prompt? (not to be confused with length)
- Prioritization: (list) what 1-3 categories are the MOST important to address.
- Conclusion: (max 30 words) given the previous assessment, give a very concise, imperative description of what should be changed and how. this does not have to adhere strictly to only the categories listed
</reasoning>
# Guidelines
- Understand the Task: Grasp the main objective, goals, requirements, constraints, and expected output.
- Minimal Changes: If an existing prompt is provided, improve it only if it's simple. For complex prompts, enhance clarity and add missing elements without altering the original structure.
- Reasoning Before Conclusions**: Encourage reasoning steps before any conclusions are reached. ATTENTION! If the user provides examples where the reasoning happens afterward, REVERSE the order! NEVER START EXAMPLES WITH CONCLUSIONS!
- Reasoning Order: Call out reasoning portions of the prompt and conclusion parts (specific fields by name). For each, determine the ORDER in which this is done, and whether it needs to be reversed.
- Conclusion, classifications, or results should ALWAYS appear last.
- Examples: Include high-quality examples if helpful, using placeholders [in brackets] for complex elements.
- What kinds of examples may need to be included, how many, and whether they are complex enough to benefit from placeholders.
- Clarity and Conciseness: Use clear, specific language. Avoid unnecessary instructions or bland statements.
- Formatting: Use markdown features for readability. DO NOT USE ```CODE BLOCKS UNLESS SPECIFICALLY REQUESTED.
- Preserve User Content: If the input task or prompt includes extensive guidelines or examples, preserve them entirely, or as closely as possible. If they are vague, consider breaking down into sub-steps. Keep any details, guidelines, examples, variables, or placeholders provided by the user.
- Constants: DO include constants in the prompt, as they are not susceptible to prompt injection. Such as guides, rubrics, and examples.
- Output Format: Explicitly the most appropriate output format, in detail. This should include length and syntax (e.g. short sentence, paragraph, JSON, etc.)
- For tasks outputting well-defined or structured data (classification, JSON, etc.) bias toward outputting a JSON.
- JSON should never be wrapped in code blocks (```) unless explicitly requested.
The final prompt you output should adhere to the following structure below. Do not include any additional commentary, only output the completed system prompt. SPECIFICALLY, do not include any additional messages at the start or end of the prompt. (e.g. no "---")
[Concise instruction describing the task - this should be the first line in the prompt, no section header]
[Additional details as needed.]
[Optional sections with headings or bullet points for detailed steps.]
# Steps [optional]
[optional: a detailed breakdown of the steps necessary to accomplish the task]
# Output Format
[Specifically call out how the output should be formatted, be it response length, structure e.g. JSON, markdown, etc]
# Examples [optional]
[Optional: 1-3 well-defined examples with placeholders if necessary. Clearly mark where examples start and end, and what the input and output are. User placeholders as necessary.]
[If the examples are shorter than what a realistic example is expected to be, make a reference with () explaining how real examples should be longer / shorter / different. AND USE PLACEHOLDERS! ]
# Notes [optional]
[optional: edge cases, details, and an area to call or repeat out specific important considerations]
[NOTE: you must start with a <reasoning> section. the immediate next token you produce should be <reasoning>]
""".strip()
def generate_prompt(task_or_prompt: str):
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Task, Goal, or Current Prompt:\n" + task_or_prompt,
},
],
)
return completion.choices[0].message.content
架构
结构化输出 架构和函数架构本身是 JSON 对象,因此我们利用结构化输出来生成它们。这需要定义一个期望输出的架构,在这种情况下,这个输出本身也是一个架构。为此,我们使用一个自描述的架构——元架构。
因为函数架构中的 parameters 字段本身也是一个架构,所以我们使用相同的元架构来生成函数。
定义一个约束元模式
结构化输出支持两种模式:strict=true 和 strict=false。两种模式都使用相同的模型来遵循提供的模式,但只有“严格模式”通过约束采样保证了完美的遵从。
我们的目标是使用严格模式本身来生成严格模式的模式。然而,由 JSON 模式规范提供的官方元模式依赖于严格模式当前不支持的特征 https://platform.openai.com/docs/guides/structured-outputs#some-type-specific-keywords-are-not-yet-supported。这给输入和输出模式都带来了挑战。
因为我们需要在输出模式中生成新的键,所以输入元模式必须使用 additionalProperties。这意味着我们目前不能使用严格模式来生成模式。然而,我们仍然希望生成的模式符合严格模式约束。
为了克服这种限制,我们定义了一个 伪元模式——一个使用严格模式不支持的功能来描述仅支持在严格模式中的功能的元模式。基本上,这种方法在元模式定义中跳出了严格模式,同时仍然确保生成的模式遵循严格模式约束。
深入了解:我们如何设计伪元模式
输出清理
严格模式保证了完美的模式遵循。然而,由于我们无法在生成时使用它,因此我们需要在生成后验证和转换输出。
在生成模式后,我们执行以下步骤:
- 将所有对象的
additionalProperties设置为false。 - 标记所有属性为必需。
- 对于结构化输出模式,将它们包裹在
json_schema对象中。 - 对于函数,将它们包裹在
function对象中。
Realtime API 函数 对象与 Chat Completions API 略有不同,但使用相同的模式。
元数据模式
每个元数据模式都有一个相应的提示,其中包含少量示例。当与结构化输出的可靠性相结合——即使在不严格模式下——我们能够使用 gpt-4o-mini 进行模式生成。
结构化输出模式函数模式
结构化输出元数据模式
from openai import OpenAI
import json
client = OpenAI()
META_SCHEMA = {
"name": "metaschema",
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The name of the schema"
},
"type": {
"type": "string",
"enum": [
"object",
"array",
"string",
"number",
"boolean",
"null"
]
},
"properties": {
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/schema_definition"
}
},
"items": {
"anyOf": [
{
"$ref": "#/$defs/schema_definition"
},
{
"type": "array",
"items": {
"$ref": "#/$defs/schema_definition"
}
}
]
},
"required": {
"type": "array",
"items": {
"type": "string"
}
},
"additionalProperties": {
"type": "boolean"
}
},
"required": [
"type"
],
"additionalProperties": False,
"if": {
"properties": {
"type": {
"const": "object"
}
}
},
"then": {
"required": [
"properties"
]
},
"$defs": {
"schema_definition": {
"type": "object",
"properties": {
"type": {
"type": "string",
"enum": [
"object",
"array",
"string",
"number",
"boolean",
"null"
]
},
"properties": {
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/schema_definition"
}
},
"items": {
"anyOf": [
{
"$ref": "#/$defs/schema_definition"
},
{
"type": "array",
"items": {
"$ref": "#/$defs/schema_definition"
}
}
]
},
"required": {
"type": "array",
"items": {
"type": "string"
}
},
"additionalProperties": {
"type": "boolean"
}
},
"required": [
"type"
],
"additionalProperties": False,
"if": {
"properties": {
"type": {
"const": "object"
}
}
},
"then": {
"required": [
"properties"
]
}
}
}
}
}
META_PROMPT = """
# Instructions
Return a valid schema for the described JSON.
You must also make sure:
- all fields in an object are set as required
- I REPEAT, ALL FIELDS MUST BE MARKED AS REQUIRED
- all objects must have additionalProperties set to false
- because of this, some cases like "attributes" or "metadata" properties that would normally allow additional properties should instead have a fixed set of properties
- all objects must have properties defined
- field order matters. any form of "thinking" or "explanation" should come before the conclusion
- $defs must be defined under the schema param
Notable keywords NOT supported include:
- For strings: minLength, maxLength, pattern, format
- For numbers: minimum, maximum, multipleOf
- For objects: patternProperties, unevaluatedProperties, propertyNames, minProperties, maxProperties
- For arrays: unevaluatedItems, contains, minContains, maxContains, minItems, maxItems, uniqueItems
Other notes:
- definitions and recursion are supported
- only if necessary to include references e.g. "$defs", it must be inside the "schema" object
# Examples
Input: Generate a math reasoning schema with steps and a final answer.
Output: {
"name": "math_reasoning",
"type": "object",
"properties": {
"steps": {
"type": "array",
"description": "A sequence of steps involved in solving the math problem.",
"items": {
"type": "object",
"properties": {
"explanation": {
"type": "string",
"description": "Description of the reasoning or method used in this step."
},
"output": {
"type": "string",
"description": "Result or outcome of this specific step."
}
},
"required": [
"explanation",
"output"
],
"additionalProperties": false
}
},
"final_answer": {
"type": "string",
"description": "The final solution or answer to the math problem."
}
},
"required": [
"steps",
"final_answer"
],
"additionalProperties": false
}
Input: Give me a linked list
Output: {
"name": "linked_list",
"type": "object",
"properties": {
"linked_list": {
"$ref": "#/$defs/linked_list_node",
"description": "The head node of the linked list."
}
},
"$defs": {
"linked_list_node": {
"type": "object",
"description": "Defines a node in a singly linked list.",
"properties": {
"value": {
"type": "number",
"description": "The value stored in this node."
},
"next": {
"anyOf": [
{
"$ref": "#/$defs/linked_list_node"
},
{
"type": "null"
}
],
"description": "Reference to the next node; null if it is the last node."
}
},
"required": [
"value",
"next"
],
"additionalProperties": false
}
},
"required": [
"linked_list"
],
"additionalProperties": false
}
Input: Dynamically generated UI
Output: {
"name": "ui",
"type": "object",
"properties": {
"type": {
"type": "string",
"description": "The type of the UI component",
"enum": [
"div",
"button",
"header",
"section",
"field",
"form"
]
},
"label": {
"type": "string",
"description": "The label of the UI component, used for buttons or form fields"
},
"children": {
"type": "array",
"description": "Nested UI components",
"items": {
"$ref": "#"
}
},
"attributes": {
"type": "array",
"description": "Arbitrary attributes for the UI component, suitable for any element",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The name of the attribute, for example onClick or className"
},
"value": {
"type": "string",
"description": "The value of the attribute"
}
},
"required": [
"name",
"value"
],
"additionalProperties": false
}
}
},
"required": [
"type",
"label",
"children",
"attributes"
],
"additionalProperties": false
}
""".strip()
def generate_schema(description: str):
completion = client.chat.completions.create(
model="gpt-4o-mini",
response_format={"type": "json_schema", "json_schema": META_SCHEMA},
messages=[
{
"role": "system",
"content": META_PROMPT,
},
{
"role": "user",
"content": "Description:\n" + description,
},
],
)
return json.loads(completion.choices[0].message.content)
2025-03-29(六)



















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











