







1、关于编码
从明文到编码文本的转换称为“编码”,从编码文本又转回成明文则为“解码”。
(1)ASCII
计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。即:计算机只懂二进制数字!
目标是:将我们能识别的符号唯一的与一组二进制数字对应。出现通过一个电平的高低状态来代指0或1,8个电平做为一组就可以表示出256种不同状态,每种状态就唯一对应一个字符,比如A--->00010001,而英文只有26个字符,算上一些特殊字符和数字,128个状态也够用了;每个电平称为一个比特位,约定8个比特位构成一个字节,这样计算机就可以用127个不同字节来存储英文字符,这就是ASCII编码。
扩展ANSI编码
最开始,一个字节有八位,但是最高位没用上,默认为0;后来为了计算机也可以表示拉丁文,就将最后一位也用上了,从128到255的字符集对应拉丁文,至此,一个字节就用满了!
(2)GB2312
计算机来到中,没法显示中文,发明可以识别中文的编码,将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了;这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
(3)GBK 和 GB18030编码
由于汉字太多,GB2312也不够用,于是规定:只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
(4)Unicode编码:
很多其它国家都有自己的编码标准,彼此间却相互不支持,带来很多问题。于是,国际标谁化组织为了统一编码:提出了标准编码准:Unicode,它是用两个字节来表示为一个字符,它总共可以组合出65535不同的字符,这足以覆盖世界上所有符号(包括甲骨文)
(5)UTF-8:
对于英文世界的人们来讲,一个字节完全够了,比如要存储A,本来00010001就可以了,现在用国际标准Unicode,得用两个字节:00000000 00010001才行,浪费太严重!基于此,提出了UTF-8.
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间!这也是为什么utf8是我们的推荐编码方式。
2、Python种编码注意事项:
(1)在python2默认编码是ASCII,python3里默认是Unicode
(2)Unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), 所以utf-16就是现在最常用的Unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
(3)在py3中encode,在编码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
3、Python中的string编码
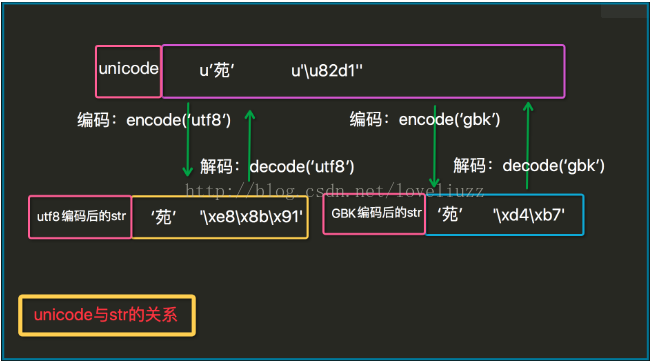
无论是utf8还是gbk都只是一种编码规则,一种把unicode数据编码成字节数据的规则。
无论py2,还是py3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
(1)Python2中的string编码
在python2中,有两种字符串类型:str类型和unicode类型;注意,这仅仅是两个名字,str和unicode分别存的是字节数据和unicode数据;那么两种数据之间如何转换就涉及到编码(encode)和解码(decode)。
内置函数repr可以显示存储内容。
#coding:utf8
#python2
s1='苑'
print type(s1) # <type 'str'>
print repr(s1) #'\xe8\x8b\x91
s2=u'苑'
print type(s2) # <type 'unicode'>
print repr(s2) # u'\u82d1's1=u'苑'
print repr(s1) #u'\u82d1'
b=s1.encode('utf8')
print b
print type(b) #<type 'str'>
print repr(b) #'\xe8\x8b\x91'
s2='苑昊'
u=s2.decode('utf8')
print u # 苑昊
print type(u) # <type 'unicode'>
print repr(u) # u'\u82d1\u660a'
#注意
u2=s2.decode('gbk')
print u2 #鑻戞槉
print len('苑昊') #6
另外,Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,
那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。py2编码让程序在处理 ASCII 的时候更加简单。你复出的代价就是在处理非 ASCII 的时候将会失败。
(2)Python3中的string编码
python3也有两种数据类型:str和bytes。str类型存unicode数据,bytse类型存bytes数据,与py2比只是换了一下名字而已。

import json
s='苑昊'
print(type(s)) #<class 'str'>
print(json.dumps(s)) # "\u82d1\u660a"
b=s.encode('utf8')
print(type(b)) # <class 'bytes'>
print(b) # b'\xe8\x8b\x91\xe6\x98\x8a'
u=b.decode('utf8')
print(type(u)) #<class 'str'>
print(u) #苑昊
print(json.dumps(u)) #"\u82d1\u660a"
print(len('苑昊')) # 2注:Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
4、总结:
(1)Python3默认字符编码是Unicode
(2)utf-8是Unicode的扩展集,在Python3中,Unicode在utf-8之间可以直接打印;而Unicode与GBK之间需要转换。
(3)所有不同字符集之间的转换,中间需通过Unicode。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#Python3中实现gb2312编码转utf-8编码转gbk编码
s = "你好"
print(type(s))
print(s)
unicode_to_gb2312 = s.encode("gb2312")
print(type(unicode_to_gb2312))
print(unicode_to_gb2312)
gb2312_to_utf8 = unicode_to_gb2312.decode("gb2312").encode("utf-8")
print(type(gb2312_to_utf8))
print(gb2312_to_utf8)
utf8_to_gbk = gb2312_to_utf8.decode("utf-8").encode("gbk")
print(type(utf8_to_gbk))
print(utf8_to_gbk)
#运行结果:
#<class 'str'>
#你好
#<class 'bytes'>
#b'\xc4\xe3\xba\xc3'
#<class 'bytes'>
#b'\xe4\xbd\xa0\xe5\xa5\xbd'
#<class 'bytes'>
#b'\xc4\xe3\xba\xc3'详细参考文章网址:http://www.cnblogs.com/yuanchenqi/articles/5956943.html















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









