







一、理论部分介绍
1. 目标定位和特征点检测
图片检测问题:
- 分类问题:判断图中是否为汽车;
- 目标定位:判断是否为汽车,并确定具体位置;
- 目标检测:检测不同物体并定位。

目标分类和定位:
对于目标定位问题,我们卷积神经网络模型结构可能如下:
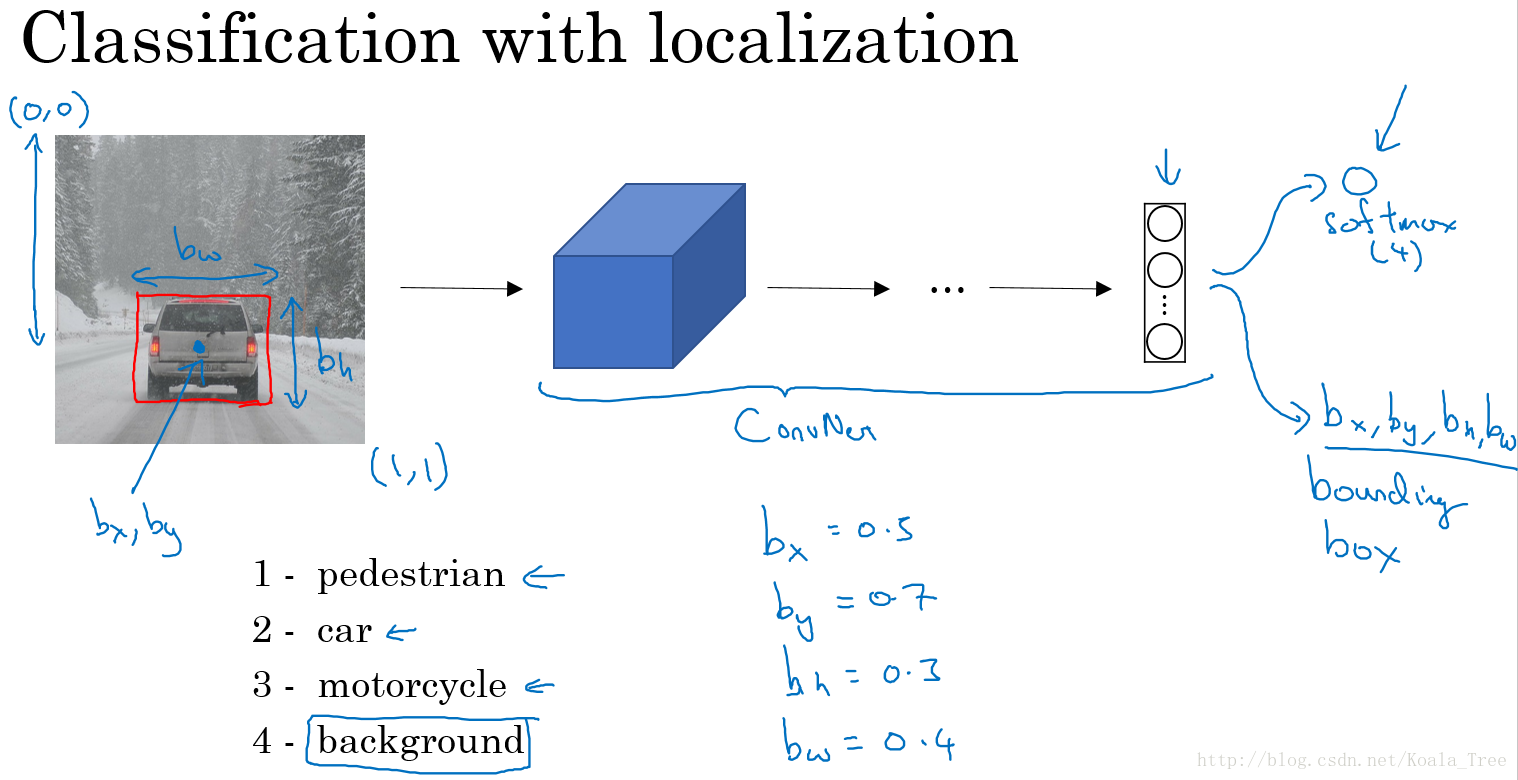
输出:包含图片中存在的对象及定位框
- 行人,0 or 1;
- 汽车,0 or 1;
- 摩托车,0 or 1;
- 图片背景,0 or 1;
- 定位框: bx、by、bh、bw
其中, bx、by 表示汽车中点, bh、bw 分别表示定位框的高和宽。以图片左上角为(0,0),以右下角为(1,1),这些数字均为位置或长度所在图片的比例大小。
目标标签 y:
- 当 Pc=1 时,表示图片中存在物体;
- 当 Pc=0 时,表示图片中不存在物体,那么此时,输出 y 的其他值为多少均没有意义,也不会参与损失函数的计算:
损失函数:
如果采用平方误差形式的损失函数:
- 当
Pc=1
时:
L(y^,y)=(y^1−y1)2+(y^2−y2)2+⋯+(y^8−y8)2
此时,我们需要关注神经网络对所有输出值的准确度; - 当
Pc=0
时:
L(y^,y)=(y^1−y1)2
此时,我们只关注神经网络对背景值的准确度。
当然在实际的目标定位应用中,我们可以使用更好的方式是:
* 对
c1、c2、c3
和softmax使用对数似然损失函数;
* 对边界框的四个值应用平方误差或者类似的方法;
* 对
Pc
应用logistic regression损失函数,或者平方预测误差。
特征点检测:
由前面的目标定位问题,我们可以知道,神经网络可以通过输出图片上特征点的坐标(x,y),来实现对目标特征的识别和定位标记。

如对于人脸表情识别的问题中,我们通过标定训练数据集中特征点的位置信息,来对人脸进行不同位置不同特征的定位和标记。AR的应用就是基于人脸表情识别来设计的,如脸部扭曲、增加头部配饰等。
在人体姿态检测中,同样可以通过对人体不同的特征位置关键点的标注,来记录人体的姿态。
目标检测采用的是基于滑动窗口的检测算法。
训练模型:

- 训练集X:将有汽车的图片进行适当的剪切,剪切成整张几乎都被汽车占据的小图或者没有汽车的小图;
- 训练集Y:对X中的图片进行标注,有汽车的标注1,没有汽车的标注0。
滑动窗口目标检测:
利用滑动窗口在实际图片中实现目标检测。

- 首先选定一个特定大小的窗口,将窗口内的图片输入到模型中进行预测;
- 以固定步幅滑动该窗口,遍历图像的每个区域,对窗内的各个小图不断输入模型进行预测;
- 继续选取一个更大的窗口,再次遍历图像的每个区域,对区域内是否有车进行预测;
- 遍历整个图像,可以保证在每个位置都能检测到是否有车。
缺点:计算成本巨大,每个窗口的小图都要进行卷积运算,(但在神经网络兴起之前,使用的是线性分类器,所以滑动窗口算法的计算成本较低)。
卷积层替代全连接层:
对于卷积网络中全连接层,我们可以利用 1×1 大小卷积核的卷积层来替代。
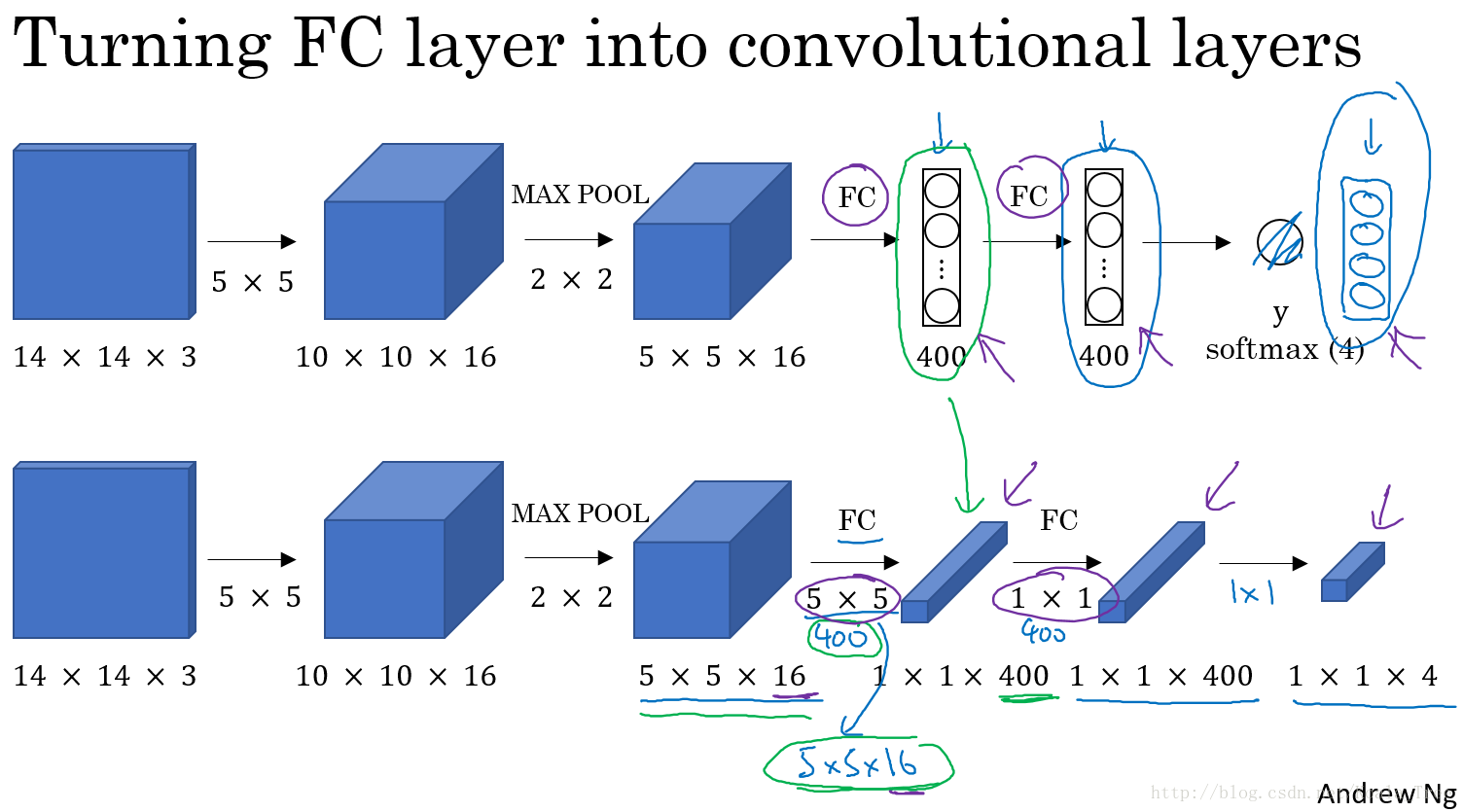
在上一周课程中,吴恩达老师讲授过 1×1 的卷积核相当于在一个三维图像的切片上应用了一个全连接的神经网络。同样,全连接层也可以由 1×1 大小卷积核的卷积层来替代。需注意卷积核的个数与隐层神经元个数相同。
滑动窗口的卷积实现:
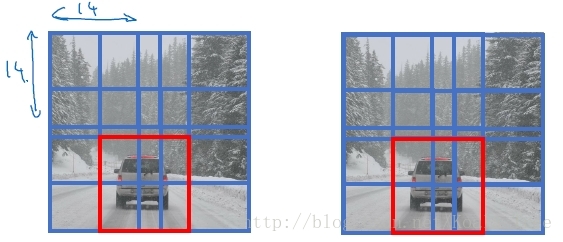
在我们实现了以卷积层替代全部的全连接层以后,在该基础上进行滑动窗口在卷积层上的操作。下面以一个小的图片为例:

我们以上面训练好的模型,输入一个 16×16×3 大小的整幅图片,图中蓝色部分代表滑动窗口的大小。我们以2为大小的步幅滑动窗口,分别与卷积核进行卷积运算,最后得到4幅 10×10×16 大小的特征图,然而因为在滑动窗口的操作时,输入部分有大量的重叠,也就是有很多重复的运算,导致在下一层中的特征图值也存在大量的重叠,所以最后得到的第二层激活值(特征图)构成一副 12×12×16 大小的特征图。对于后面的池化层和全连接层也是同样的过程。
那么由此可知,滑动窗口在整幅图片上进行滑动卷积的操作过程,就等同于在该图片上直接进行卷积运算的过程。所以卷积层实现滑动窗口的这个过程,我们不需要把输入图片分割成四个子集分别执行前向传播,而是把他们作为一张图片输入到卷积神经网络中进行计算,其中的重叠部分(公共区域)可以共享大量的计算。
汽车目标检测:
依据上面的方法,我们将整张图片输入到训练好的卷积神经网络中。无需再利用滑动窗口分割图片,只需一次前向传播,我们就可以同时得到所有图片子集的预测值。

利用卷积的方式实现滑动窗口算法的方法,提高了整体的计算效率。
3. Bounding Box 预测
前面一节的卷积方式实现的滑动窗口算法,使得在预测时计算的效率大大提高。但是其存在的问题是:不能输出最精准的边界框(Bounding Box)。
在滑动窗口算法中,我们取的一些离散的图片子集的位置,在这种情况下,有可能我们没有得到一个能够完美匹配汽车位置的窗口,也有可能真实汽车的边界框为一个长方形。所以我们需要寻找更加精确的边界框。

YOLO:
YOLO算法可以使得滑动窗口算法寻找到更加精准的边界框。
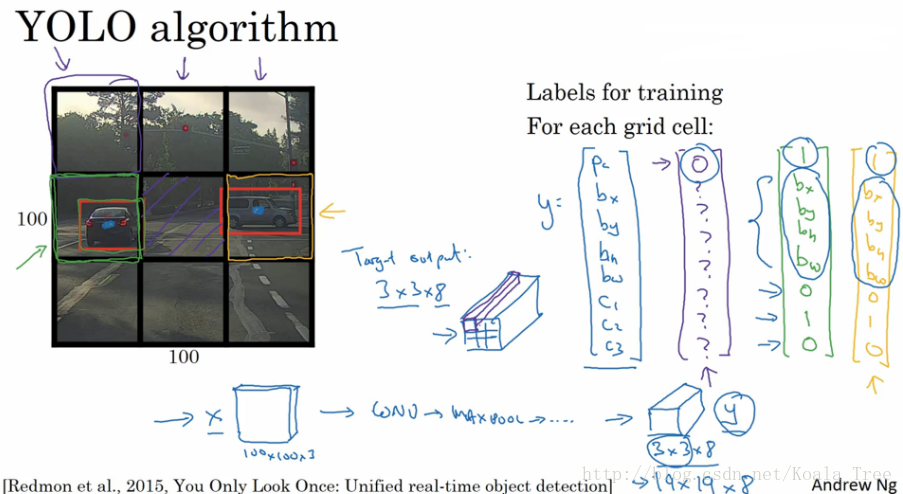
- 在整幅图片上加上较为精细的网格,将图片分割成 n×n 个小的图片;
- 采用图像分类和定位算法,分别应用在图像的 n×n 个格子中。
- 定义训练标签:(对于每个网格,定义如前面的向量
yi
)
yi=[Pc bx by bh bw c1 c2 c3]
对于不同的网格 i 有不同的标签向量 yi 。 - 将 n×n 个格子标签合并在一起,最终的目标输出Y的大小为: n×n×8 (这里8是因为例子中的目标值有8个)。
通过这样的训练集训练得到目标探测的卷积网络模型。我们利用训练好的模型,将与模型输入相同大小的图片输入到训练好的网络中,得到大小为 n×n×8 的预测输出。通过观察 n×n 不同位置的输出值,我们就能知道这些位置中是否存在目标物体,然后也能由存在物体的输出向量得到目标物体的更加精准的边界框。
YOLO notation:
- 将对象分配到一个格子的过程是:观察对象的中点,将该对象分配到其中点所在的格子中,(即使对象横跨多个格子,也只分配到中点所在的格子中,其他格子记为无该对象,即标记为“0”);
- YOLO显式地输出边界框,使得其可以具有任意宽高比,并且能输出更精确的坐标,不受滑动窗口算法滑动步幅大小的限制;
- YOLO是一次卷积实现,并不是在 n×n 网格上进行 n2 次运算,而是单次卷积实现,算法实现效率高,运行速度快,可以实现实时识别。
bounding boxes 细节:
利用YOLO算法实现目标探测的时候,对于存在目标对象的网格中,定义训练标签Y的时候,边界框的指定参数的不同对其预测精度有很大的影响。这里给出一个较为合理的约定:(其他定值方式可阅读论文)

- 对于每个网格,以左上角为(0,0),以右下角为(1,1);
- 中点 bx、by 表示坐标值,在0~1之间;
- 宽高 bh、bw 表示比例值,存在>1的情况。
4. 交并比(Intersection-over-Union)
交并比函数用来评价目标检测算法是否运作良好。

对于理想的边界框和目标探测算法预测得到的边界框,交并比函数计算两个边界框交集和并集之比。
IoU=交集面积并集面积
一般在目标检测任务中,约定如果 IoU⩾0.5 ,那么就说明检测正确。当然标准越大,则对目标检测算法越严格。得到的IoU值越大越好。
5. 非最大值抑制(non-max suppression,NMS)
对于我们前面提到的目标检测算法,可能会对同一个对象做出多次的检测,非最大值抑制可以确保我们的算法对每个对象只检测一次。
多网格检测同一物体:
对于汽车目标检测的例子中,我们将图片分成很多精细的格子。最终预测输出的结果中,可能会有相邻的多个格子里均检测出都具有同一个对象。

NMS算法思想:

- 在对 n×n 个网格进行目标检测算法后,每个网格输出的 Pc 为一个0~1的值,表示有车的概率大小。其中会有多个网格内存在高概率;
- 得到对同一个对象的多次检测,也就是在一个对象上有多个具有重叠的不同的边界框;
- 非最大值抑制对多种检测结果进行清理:选取最大 Pc 的边界框,对所有其他与该边界框具有高交并比或高重叠的边界框进行抑制;
- 逐一审视剩下的边界框,寻找最高的 Pc 值边界框,重复上面的步骤。
- 非最大值抑制,也就是说抑制那些不是最大值,却比较接近最大值的边界框。
NMS算法:
以单个对象检测为例:
- 对于图片每个网格预测输出矩阵: yi=[Pc bx by bh bw] ,其中 Pc 表示有对象的概率;
- 抛弃 Pc⩽0.6 的边界框;
- 对剩余的边界框(while):
- 选取最大 Pc 值的边界框,作为预测输出边界框;
- 抛弃和选取的边界框 IoU⩾0.5 的剩余的边界框。
对于多对象检测,输出标签中就会有多个分量。正确的做法是:对每个输出类别分别独立进行一次非最大值抑制。
6. Anchor box
通过上面的各种方法,目前我们的目标检测算法在每个格子上只能检测出一个对象。使用Anchor box 可以同时检测出多个对象。
重叠目标:
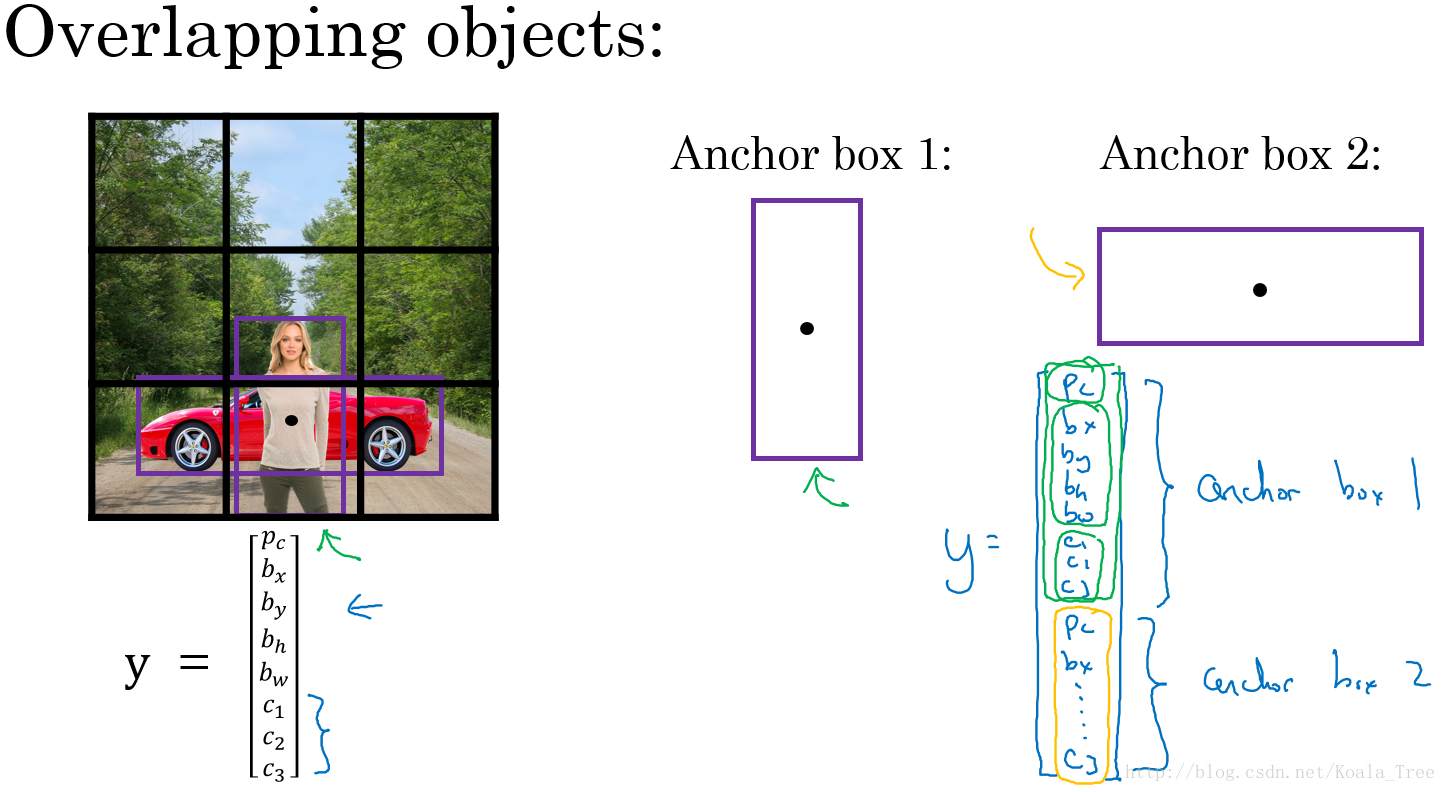
对于重叠的目标,这些目标的中点有可能会落在同一个网格中,对于我们之前定义的输出: yi=[Pc bx by bh bw c1 c2 c3] ,只能得到一个目标的输出。
而Anchor box 则是预先定义多个不同形状的Anchor box,我们需要把预测目标对应地和各个Anchor box 关联起来,所以我们重新定义目标向量:
yi=[Pc bx by bh bw c1 c2 c3 Pc bx by bh bw c1 c2 c3⋯]
用这样的多目标向量分别对应不同的Anchor box,从而检测出多个重叠的目标。
- 不使用Anchor box:训练图片中的每个对象,根据对象的中点,分配到对应的格子中。输出大小(例如8): n×n×8 ;
- 使用Anchor box:训练图片的每个对象,根据对象的中点,分配到对应的格子中,同时还分配到一个和对象形状的IoU最高的Anchor box 中。输出大小(例如两个Anchor box): n×n×16 。
例子:
如下面的图片,里面有行人和汽车,我们为其分配两个Anchor box。对于行人形状更像Anchor box 1,汽车形状更像Anchor box 2,所以我们将人和汽车分配到不同的输出位置。
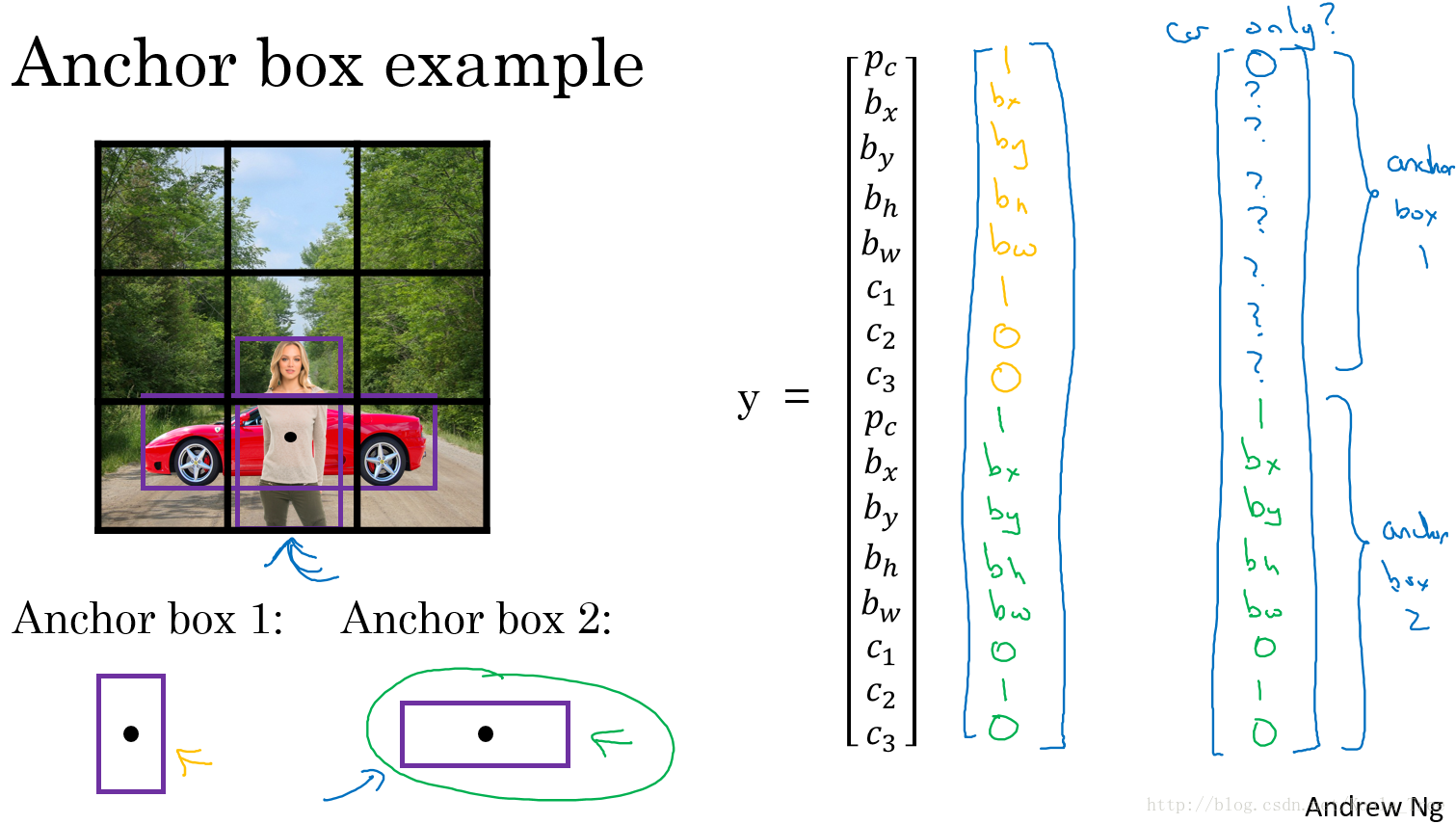
如果格子中只有汽车的时候,我们使用了两个Anchor box,那么此时我们的目标向量就成为:
yi=[0 ? ? ? ? ? ? ? 1 bx by bh bw 0 1 0]
其中,“?”代表的是该位置是什么样的参数我们都不关系。
难点问题:
- 如果我们使用了两个Anchor box,但是同一个格子中却有三个对象的情况,此时只能用一些额外的手段来处理;
- 同一个格子中存在两个对象,但它们的Anchor box 形状相同,此时也需要引入一些专门处理该情况的手段。
但是以上的两种问题出现的可能性不会很大,对目标检测算法不会带来很大的影响。
Anchor box 的选择:
- 一般人工指定Anchor box 的形状,选择5~10个以覆盖到多种不同的形状,可以涵盖我们想要检测的对象的形状;
- 高级方法:K-means 算法:将不同对象形状进行聚类,用聚类后的结果来选择一组最具代表性的Anchor box,以此来代表我们想要检测对象的形状。
7. YOLO算法目标检测
假设我们要在图片中检测三种目标:行人、汽车和摩托车,同时使用两种不同的Anchor box。
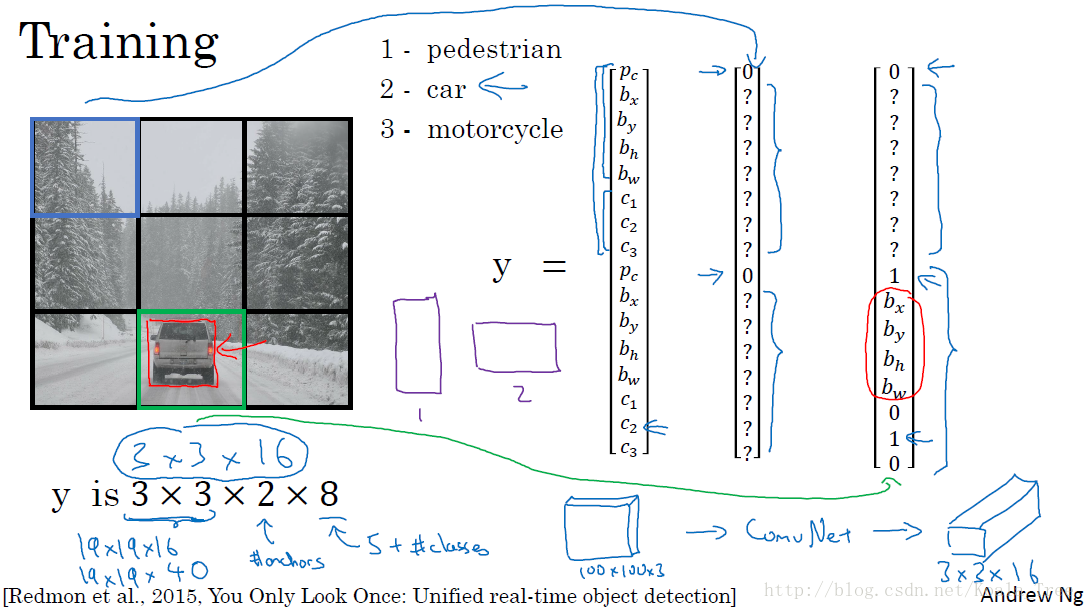
训练集:
- 输入X:同样大小的完整图片;
- 目标Y:使用 3×3 网格划分,输出大小 3×3×2×8 ,或者 3×3×16
- 对不同格子中的小图,定义目标输出向量Y。
模型预测:
输入与训练集中相同大小的图片,同时得到每个格子中不同的输出结果: 3×3×2×8 。
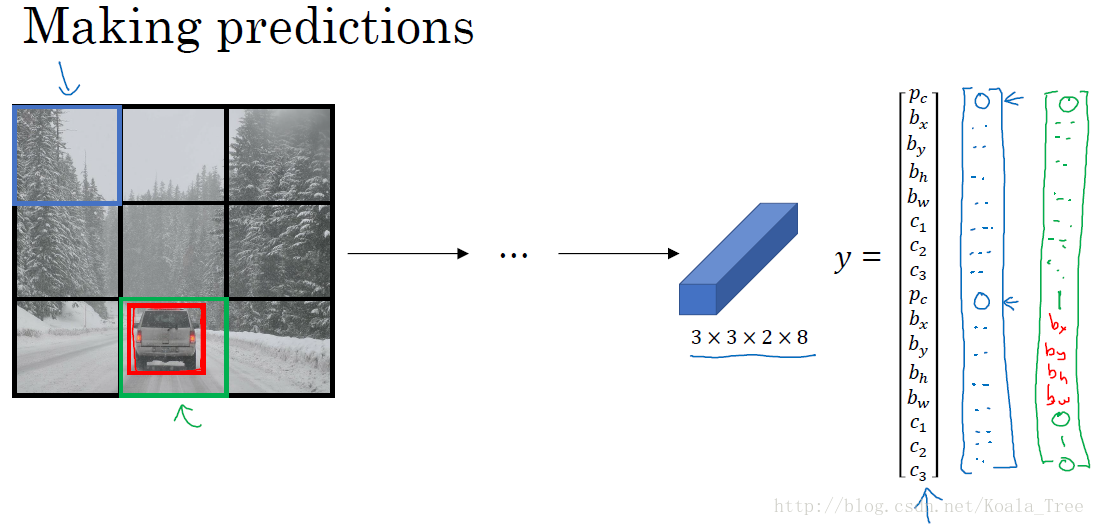
运行非最大值抑制(NMS):
- 假设使用了2个Anchor box,那么对于每一个网格,我们都会得到预测输出的2个bounding boxes,其中一个
Pc
比较高;
- 抛弃概率
Pc
值低的预测bounding boxes;
- 对每个对象(如行人、汽车、摩托车)分别使用NMS算法得到最终的预测边界框。



8. 候选区域(region proposals)
R-CNN:
R-CNN(Regions with convolutional networks),会在我们的图片中选出一些目标的候选区域,从而避免了传统滑动窗口在大量无对象区域的无用运算。
所以在使用了R-CNN后,我们不会再针对每个滑动窗口运算检测算法,而是只选择一些候选区域的窗口,在少数的窗口上运行卷积网络。
具体实现:运用图像分割算法,将图片分割成许多不同颜色的色块,然后在这些色块上放置窗口,将窗口中的内容输入网络,从而减小需要处理的窗口数量。

更快的算法:
- R-CNN:给出候选区域,对每个候选区域进行分类识别,输出对象 标签 和 bounding box,从而在确实存在对象的区域得到更精确的边界框,但速度慢;
- Fast R-CNN:给出候选区域,使用滑动窗口的卷积实现去分类所有的候选区域,但得到候选区的聚类步骤仍然非常慢;
- Faster R-CNN:使用卷积网络给出候选区域。
(一)目标应用
- 在汽车检测数据集上使用目标检测
- 处理边界框(bounding boxes)
1、项目描述
假设你正在开一辆自动驾驶汽车,作为这个项目的重要组成部分,你想先建立一个汽车检测系统。为了收集数据,你已经把摄像头安装在汽车的引擎盖上,在驾驶时每隔几秒就会拍摄前方的道路。已经将所有这些图像收集到一个文件夹中,并通过在找到的每辆车周围绘制边界框来标记它们。下面是边界框的举例:

假设有80个类别需要YOLO算法来识别,可以表示:类别标签C 为一个从1到80的整数,或者为一个80维向量(有80个数字),其中一个分量是1,其余的是0。将YOLO算法应用于汽车检测,由于YOLO模型在训练时计算起来非常耗时,我们将加载预先训练的权重参数来使用。
YOLO(“你只看一次”)是一个流行的算法,因为它实现了高精度,同时也能够实时运行。该算法在图像上“只看一次”,因为只需要一次前向传播就可以通过网络进行预测。在非极大值抑制之后,它将识别的对象与边界框一起输出。
2、模型的细节
—— 输入是一批形状(m,608,608,3)的图像
—— 输出 是一个边界框和识别的类别的列表。每个边界框由6个数字表示:
如果你扩大 C,转换成80维向量,然后用85个数字表示每个边界框。
我们将使用5个anchor boxes,假设一幅图片中可能会有5种物体(如:汽车、路灯、交通指示灯、树木、天空)。
所以将YOLO体系结构看作如下:
IMAGE(m,608,608,3) - > DEEP CNN - > ENCODING(m,19,19,5,85)。
m:代表输入图片的数目;图片的大小为:608*306*3;19*19:代表将图片应用19*19大小的网格;
5:代表anchor boxes的数目;85:每一个anchor box的维度大小,包括一个表示是否含有目标的标志Pc,
边框信息4个参数和80个类别,共计85个参数,这样经过卷积神经网络后输出维度变为(m,19,19,425),
425=5*85,表示每一个标签y的维度有85维。

如果一个对象/目标的中心/中点落入某一个网格单元中,那么该网格单元负责检测该对象,即:对象目标的预测标签值由该对象的中点落入的网格的标签值决定。由于我们使用了5个anchor boxes,所以19x19个单元中的每一个都编码了5个边框的信息。anchor boxes的定义仅由其宽度和高度来定义。为了简单起见,我们将形状(19,19,5,85)编码的最后两个维度扁平化,所以Deep CNN的输出是(19,19,425)。

现在,对于每个边框(每个单元),我们将计算下面的内容,并提取边框包含某个类别的概率。

以下是YOLO算法在图像上进行预测的一种可视化方法:
- 对于19x19的网格中的每个单元,找到概率分数的最大值(从5个anchor boxes中和不同类别取最大值)。
- 对每个网格单元根据最可能考虑的对象进行颜色填充。
注意,这种可视化不是YOLO算法本身进行预测的核心部分; 这只是一个可视化算法的中间结果的好方法。

另一种YOLO算法的可视化输出的方法是绘制它输出的边界框。

注:每个单元给出5个anchor boxes。总的来说,该模型预测:19x19x5 = 1805个anchor boxes,只需对图像进行一次正向传播,不同的颜色表示不同的类别。在上面的图中,我们只绘制了模型分配给它的概率高的anchor box,但这仍然是太多anchor box。然后应算法对输出进行过滤,使得检测到的对象数量更少。为此将使用非极大值抑制。具体来说,你将执行这些步骤:
-- 抛弃概率低的anchor box(也就是说,anchor box 对于检测的类别并不是很有把握)
-- 当几个anchor box相互重叠并且检测到相同的对象时,只选择一个盒子。
3、在类别得分概率上用阈值进行过滤
抛弃掉任何类别的“分数”小于选定的阈值的边界框。
该模型给你总共19x19x5x85个数字,每个anchor box由85个数字描述。将(19,19,5,85)(或(19,19,425))维张量重新排列成以下变量将是很方便的:
- box_confidence形状为(19×19,5 ,1)张量,在19x19个单元及5个框中的每一个包含预测的Pc(目标的置信概率)。
- boxes:张量的形状(19×19,5 ,4)张量,在19x19个单元及5个框中的每一个包含(bx,by,bw,bh).
- box_class_probs:张量的形状为(19×19,5 ,80)的张量,在19x19个单元及5个框中的每一个包含检测的类别(c1,c2,...,c80)。
该功能在文件yolo_utils.py的yolo_filter_boxes()函数中实现。
def yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold=.6):
"""
基于目标和类别的置信度来过滤YOLO边界框.
Arguments:
box_confidence -- 形状为(19, 19, 5, 1)的张量,包含预测的Pc(目标的置信概率)
boxes -- 形状为(19, 19, 5, 4)的张量,包含角点坐标(x1,y1,x2,y2)
box_class_probs -- 形状为(19, 19, 5, 80)的张量,包含(c1,c2,...,c80)
threshold -- 真实值,如果[最高的目标置信概率<阈值],则抛弃相应的框
Returns:
scores -- 维度为(None,)的张量, 包含所选择框的目标类别的置信概率
boxes -- 维度为(None, 4)的张量, 包含(b_x, b_y, b_h, b_w)所选择的边框的坐标信息
classes -- 维度为(None,)的张量, 包含所选择的边框检测到的类别的索引
注: 这里的"None" ,因为你不知道所选框的确切数量,因为它取决于阈值。
例如,如果选择10个框,则scores的实际输出大小将是(10,)。
"""
#计算边框的scores(选择框的目标类别的置信概率)
box_scores = tf.multiply(box_confidence, box_class_probs) #(19*19, 5, 80)
#根据最大box_scores找到box_classes,并求出相应的score分数
## axis=-1, 表示倒数第1个轴axis, 即80个scores中的最大值
box_classes = K.argmax(box_scores, axis=-1) #(19*19,5)
box_class_scores = K.max(box_scores, axis=-1) #(19*19,5)
#使用“阈值threshold”创建基于“box_class_scores”的过滤掩码。
#过滤掩码应具有与box_class_scores相同的维度,对于要保留的边界框(其概率>=阈值)为True
filtering_mask = box_class_scores > threshold #(19*19,5)
#过滤掉score低于threshold的box
boxes = tf.boolean_mask(boxes, filtering_mask)
scores = tf.boolean_mask(box_class_scores, filtering_mask)
classes = tf.boolean_mask(box_classes, filtering_mask)
return scores,boxes, classes即使经过对类别分数的筛选,仍然会导致很多重叠的框。用于选择正确边框的第二个过滤器称为非极大值抑制(NMS)。


交并比的功能实现在yolo_utils.py的iou()函数中。
---我们使用它的两个角(左上角和右下角)来定义一个方框:(x1,y1,x2,y2),而不是中点和高度/宽度。
--要计算矩形区域,需要将其高度(y2 - y1)乘以其宽度(x2 - x1)
--还需要找到两个边界框的交集的坐标(xi1,yi1,xi2,yi2)。
xi1 =两个边界框的x1坐标的最大值
yi1 =两个边界框的y1坐标的最大值
xi2 =两个边界框的x2坐标的最小值
yi2 =两个边界框的y2坐标的最小值
在这个代码中,我们使用约定,(0,0)是图像的左上角,(1,0)是右上角,(1,1)是右下角。
def iou(box1,box2):
"""
在box1和box2之间计算交并比IoU
param :
box1 -- 第一个边框的坐标为(x1,y1,x2,y2),用列表存储
box2-- 第二个边框的坐标为(x1,y1,x2,y2),用列表存储
return:
iou -- 交并比
"""
#计算box1和box2交集的(xi1,yi1,xi2,yi2)坐标,计算其面积。
xi1 = np.max([box1[0],box2[0]])
yi1 = np.max([box1[1],box2[1]])
xi2 = np.min([box1[2],box2[2]])
yi2 = np.min([box1[3],box2[3]])
inter_area = (xi2-xi1)*(yi2-yi1) #相交的面积
#使用公式计算并集区域:Union(A,B) = A + B - Inter(A,B)
box1_area = (box1[2]-box1[0])*(box1[3]-box1[1])
box2_area = (box2[2]-box2[0])*(box2[3]-box2[1])
union_area = box1_area + box2_area - inter_area
#计算IoU
iou = inter_area/union_area
return iou下面构建非极大值抑制。关键步骤是:
(1)去掉所有预测概率/分数scores比较低的输出边界框。
(2)选择预测概率/分数scores最高的边界框,将其输出为预测结果。
(3)计算其与所有其他框的重叠面积(交并比),并移除与其重叠面积(交并比)很高的边界框,用函数iou_threshold实现。
(4)返回到步骤2并迭代,直到没有比当前选定边界框更低的预测概率/分数scores的边界框。
这将删除所有与所选边界框重叠很多的其他边界框,只剩下“最好”的边界框。
创建:使用TensorFlow实现yolo_non_max_suppression()。TensorFlow有两个内置函数用于实现非极大值抑制
(所以你实际上不需要使用你的iou()函数实现):
- tf.image.non_max_suppression()
- K.gather()
#非极大值抑制
def yolo_non_max_supperssion(scores,boxes,classes,max_boxes=10,iou_threshold=0.5):
"""
用极大值抑制设置过滤边界框
param :
scores --维度为(None,)的张量, 包含所选择框的目标类别的置信概率,yolo_filter_boxes()的输出
boxes --维度为(None, 4)的张量, 包含(b_x, b_y, b_h, b_w)所选择的边框的坐标信息,yolo_filter_boxes()的输出
classes --维度为(None,)的张量, 包含所选择的边框检测到的类别的索引,yolo_filter_boxes()的输出
max_boxes -- 整数,想要预测的边界框的最大数量
iou_threshold -- 实际值,非极大值抑制方法的交并比的阈值
return:
scores -- 维度为(,None)的张量, 预测的每一个边界框的分数score
boxes -- 维度为(4,None)的张量,预测的每一个边界框的坐标信息
classes -- 维度为(,None)的张量, 预测的每一个边界框的类别
Note: 输出张量的维度“None”显然要小于max_boxes。
还要注意,这个函数改变了scores,boxes,classes的形状。
"""
max_box_tensor = K.variable(max_boxes,dtype="int32") #张量,在tf.image.non_max_suppression()中使用
K.get_session().run(tf.variables_initializer([max_box_tensor])) #初始化变量max_boxes_tensor
#使用tf.image.non_max_suppression()来获取与要保留的边界框相对应的索引列表
nms_indices = tf.image.non_max_suppression(boxes=boxes,scores=scores,max_output_size=max_boxes,iou_threshold=iou_threshold)
#使用K.gather()从scores,boxes和classes中只选择一个nms_indices
scores = K.gather(scores,nms_indices)
boxes = K.gather(boxes,nms_indices)
classes = K.gather(classes,nms_indices)
return scores,boxes,classes实现一个采用深度的卷积神经网络CNN使得输出的尺寸为(19x19x5x85尺寸编码),并使用刚实现的函数对所有框进行过滤。
创建:实现yolo_eval()函数采用YOLO编码的输出,并使用分数score阈值和非极大值抑制NMS过滤边界框。
有几种方法来表示边界框,比如通过角落或通过中点和高度/宽度。YOLO使用以下函数在不同的时候在几个这样的格式之间进行转换:

上面的函数实现从(x,y,w,h)转换为边界框角落的坐标(x1,y1,x2,y2),以适应函数yolo_filter_boxes()的输入。
def yolo_boxes_to_corners(box_xy, box_wh):
"""Convert YOLO box predictions to bounding box corners.
将预测的YOLO边界框转换为边界框角点。
"""
box_mins = box_xy - (box_wh / 2.)
box_maxes = box_xy + (box_wh / 2.)
return K.concatenate([
box_mins[..., 1:2], # y_min
box_mins[..., 0:1], # x_min
box_maxes[..., 1:2], # y_max
box_maxes[..., 0:1] # x_max
])
YOLO的网络被训练在608x608图像上运行,如果您要在不同大小的图像上测试这些数据(例如,汽车检测数据集具有720x1280图像),则此步骤会对这些边界框进行缩放,使其可以绘制在原始720x1280图像的顶部。
def scale_boxes(boxes, image_shape):
"""
Scales the predicted boxes in order to be drawable on the image
缩放预测框以便在图像上绘制
"""
height = image_shape[0]
width = image_shape[1]
image_dims = K.stack([height, width, height, width])
image_dims = K.reshape(image_dims, [1, 4])
boxes = boxes * image_dims
return boxes#yolo算法
def yolo_eval(yolo_outputs,image_shape=(720.,1280.),max_boxes=10,score_threshold=0.6,iou_threshold=0.5):
"""
将YOLO编码的输出(很多框)转换为预测的边界框以及它们的scores,boxes和classes。
param :
yolo_outputs -- 为图像形状(608, 608, 3)输出的编码模型,包含4个张量:
box_confidence: 张量,形状为(None, 19, 19, 5, 1)
box_xy: 张量,形状为(None, 19, 19, 5, 2)
box_wh: 张量,形状为(None, 19, 19, 5, 2)
box_class_probs:张量,形状为(None, 19, 19, 5, 80)
image_shape --张量,包含输入形状为(2,),使用(608.,608.)(必须是float32的类型)
max_boxes -- 整数,想要的最大数量的预测边界框
score_threshold -- 实际值,如果[最高概率得分<阈值],则抛弃相应的边界框
iou_threshold -- 实际值,用于非极大值抑制的交并比的阈值
return:
scores -- 张量,形状为(None, ), 预测的每一个边界框的分数score
boxes -- 张量,形状为(None, 4), 预测的每一个边界框的信息
classes -- 张量,形状为(None,), 预测的每一个边界框的类别class
"""
#恢复展开YOLO模型的输出
box_confidence,box_xy,box_wh,box_class_probs = yolo_outputs
#从(x,y,w,h)转换为边界框角落的坐标(x1,y1,x2,y2)
boxes = yolo_boxes_to_corners(box_xy,box_wh)
#基于目标和类别的置信度来过滤分数较低的YOLO边界框.
scores,boxes,classes = yolo_filter_boxes(box_confidence,boxes,box_class_probs,score_threshold)
#将边界框放大到原始图像形状
boxes = scale_boxes(boxes,image_shape)
#非极大值抑制操作,其阈值为iou_threshold
scores, boxes, classes = yolo_non_max_supperssion(scores,boxes,classes,max_boxes,iou_threshold)
return scores, boxes, classes
---输入图像 (608,608,3)
--- 输入图像通过CNN,产生(19,19,5,85)尺寸输出。
--- 平坦化后两个维度后,输出为一个形状体积(19,19,425 ):
输入图像上19x19格子中的每个单元格给出425个数字。
425 = 5 x 85,因为每个单元格包含5个方框的预测,对应于5个anchor box。
85 = 5 + 80,其中5是因为(Pc,bx,by,bh,bw)和80是我们想要检测的类的数量
- 然后您只能根据以下几项选择几个框:
- 分数阈值:丢弃检测到分数小于阈值的分类的盒子
- 非最大抑制:计算联合交汇点,避免选择重叠盒
- 这给你YOLO的最终输出。
6、在图像上测试YOLO预训练模型
使用预训练模型并在汽车检测数据集上进行测试,像往常一样,开始创建一个session会话来开始图形计算graph。
(1)定义类别classes、边界框anchor box、图像的形状
我们试图检测80个类别,并使用5个anchor box。我们收集了两个文件“coco_classes.txt”和“yolo_anchors.txt”中
关于80个类别和5个anchor box的信息,将数量加载到模型中。
(2)加载预训练的模型
训练一个YOLO模型需要很长时间,并且需要一个相当大的标签边界框的数据集来处理大量的目标类别。将加载存储在“yolo.h5”中的现有预训练Keras YOLO模型。(这些权重来自官方的YOLO网站,并使用由Allan Zelener编写的函数进行转换,从技术上说,这些是来自“YOLOv2”模型的参数)。
通过python语句 yolo_model.summary() 可以查看模型包含的层的信息。
该模型将预处理的一批输入图像(形状:(m,608,608,3))转换为形状(m,19,19,5,85)的张量。
(3)将模型的输出转化为可视的边界框信息
输出yolo_model是一个(m,19,19,5,85)张量,需要经过函数yolo_head()函数的处理和转换。
def yolo_head(feats, anchors, num_classes):
"""Convert final layer features to bounding box parameters.
Parameters
----------
feats : tensor
Final convolutional layer features.
anchors : array-like
Anchor box widths and heights.
num_classes : int
Number of target classes.
Returns
-------
box_xy : tensor
x, y box predictions adjusted by spatial location in conv layer.
box_wh : tensor
w, h box predictions adjusted by anchors and conv spatial resolution.
box_conf : tensor
Probability estimate for whether each box contains any object.
box_class_pred : tensor
Probability distribution estimate for each box over class labels.
"""
num_anchors = len(anchors)
# Reshape to batch, height, width, num_anchors, box_params.
anchors_tensor = K.reshape(K.variable(anchors), [1, 1, 1, num_anchors, 2])
# Static implementation for fixed models.
# TODO: Remove or add option for static implementation.
# _, conv_height, conv_width, _ = K.int_shape(feats)
# conv_dims = K.variable([conv_width, conv_height])
# Dynamic implementation of conv dims for fully convolutional model.
conv_dims = K.shape(feats)[1:3] # assuming channels last
# In YOLO the height index is the inner most iteration.
conv_height_index = K.arange(0, stop=conv_dims[0])
conv_width_index = K.arange(0, stop=conv_dims[1])
conv_height_index = K.tile(conv_height_index, [conv_dims[1]])
# TODO: Repeat_elements and tf.split doesn't support dynamic splits.
# conv_width_index = K.repeat_elements(conv_width_index, conv_dims[1], axis=0)
conv_width_index = K.tile(K.expand_dims(conv_width_index, 0), [conv_dims[0], 1])
conv_width_index = K.flatten(K.transpose(conv_width_index))
conv_index = K.transpose(K.stack([conv_height_index, conv_width_index]))
conv_index = K.reshape(conv_index, [1, conv_dims[0], conv_dims[1], 1, 2])
conv_index = K.cast(conv_index, K.dtype(feats))
feats = K.reshape(feats, [-1, conv_dims[0], conv_dims[1], num_anchors, num_classes + 5])
conv_dims = K.cast(K.reshape(conv_dims, [1, 1, 1, 1, 2]), K.dtype(feats))
# Static generation of conv_index:
# conv_index = np.array([_ for _ in np.ndindex(conv_width, conv_height)])
# conv_index = conv_index[:, [1, 0]] # swap columns for YOLO ordering.
# conv_index = K.variable(
# conv_index.reshape(1, conv_height, conv_width, 1, 2))
# feats = Reshape(
# (conv_dims[0], conv_dims[1], num_anchors, num_classes + 5))(feats)
box_confidence = K.sigmoid(feats[..., 4:5])
box_xy = K.sigmoid(feats[..., :2])
box_wh = K.exp(feats[..., 2:4])
box_class_probs = K.softmax(feats[..., 5:])
# Adjust preditions to each spatial grid point and anchor size.
# Note: YOLO iterates over height index before width index.
box_xy = (box_xy + conv_index) / conv_dims
box_wh = box_wh * anchors_tensor / conv_dims
return box_confidence, box_xy, box_wh, box_class_probsyolo_outputs为yolo_model提供了正确格式的所有预测框,现在已经准备好执行过滤并只选择最佳的框,应用前面构建的函数yolo_eval()。
(5)在图像上运行构建的graph
实现predict()函数运行图形graph来在图像上测试的YOLO算法。
你将需要运行一个TensorFlow会话session来计算它scores, boxes, classes。
图像预处理函数preprocess_image() 的代码:
def preprocess_image(img_path, model_image_size):
image_type = imghdr.what(img_path)
image = Image.open(img_path)
resized_image = image.resize(tuple(reversed(model_image_size)), Image.BICUBIC)
image_data = np.array(resized_image, dtype='float32')
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
return image, image_data为边界框生成颜色的generate_colors()函数代码:
def generate_colors(class_names):
hsv_tuples = [(x / len(class_names), 1., 1.) for x in range(len(class_names))]
colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
colors = list(map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), colors))
random.seed(10101) # Fixed seed for consistent colors across runs.
random.shuffle(colors) # Shuffle colors to decorrelate adjacent classes.
random.seed(None) # Reset seed to default.
return colors
def draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors):
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=colors[c])
draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
#预测
def predict(sess,image_file):
"""
运行存储在“sess”中的graph图表以预测“image_file”的边界框,打印和绘制预测的结果
param :
sess -- 包含yolo算法的tensorflow/Keras会话
image_file -- 存储在“image”文件夹中的图像的名称
return:
out_scores -- 形状为(None, )的张量, 预测的边界框的分数
out_boxes -- 形状为(None, 4)的张量, 预测的边界框的坐标信息
out_classes -- 形状为(None, )的张量, 预测的边界框的类别索引
"""
#预处理图片
image, image_data = preprocess_image("images/"+image_file,model_image_size=(608,608) )
#运行会话,并在feed_dict中选择相关的占位符
#因为BatchNorm,需要使用feed_dict = {yolo_model.input:...,K.learning_phase():0}
out_scores,out_boxes,out_classes = sess.run([scores, boxes, classes],feed_dict={yolo_model.input:image_data,K.learning_phase():0})
#打印预测信息
print('Found {} boxes for {}'.format(len(out_boxes), image_file))
# 为边界框生成颜色
colors = generate_colors(class_names)
# 在图片画出检测的物体的边界框
draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors)
# 保存在图片上预测的边界框
image.save(os.path.join("out", image_file), quality=90)
# Display the results in the notebook
output_image = scipy.misc.imread(os.path.join("out", image_file))
imshow(output_image)
return out_scores, out_boxes, out_classes
out_scores, out_boxes, out_classes = predict(sess,"test.jpg")
Found 7 boxes for test.jpg
car 0.60 (925, 285) (1045, 374)
car 0.66 (706, 279) (786, 350)
bus 0.67 (5, 266) (220, 407)
car 0.70 (947, 324) (1280, 705)
car 0.74 (159, 303) (346, 440)
car 0.80 (761, 282) (942, 412)
car 0.89 (367, 300) (745, 648)


















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









