







量大核心设计:
mapreduce:
- map:任务的分解
- reduce:任务的汇总
HDFS:
- namenode
- datanode
- client
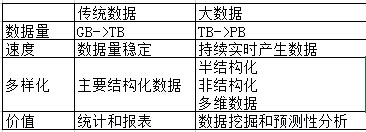
大数据VS传统数据
关系型数据库
适合复杂的需要事务处理的应用
MPP和hadoop
数据仓库和离线数据分析
大规模在线实时应用
子项目:
core:
HDFS:分布式文件系统
Mapreduce:
zookeeper:分布式系统系统
pig:
hive:分布式数据仓库,hiveQL
hbase:可扩展的数据库系统
flume:
mahout:
sqoop:
HDFS:
namenode:存储元数据,保存在内存中(磁盘有一份),保存文件、block、datanode之间的映射关系
datanode:存储文件内容,保存在磁盘中,维护了block id到datanode本地文件的映射关系
一个namenode和多个datanode,采用冗余机制,机架感知策略,故障检测,空间回收机制
HDFS架构
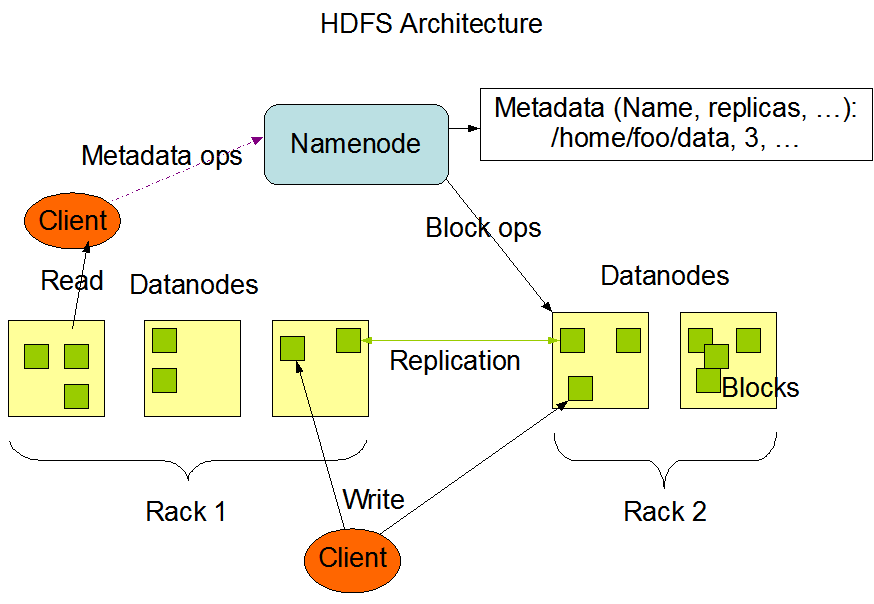
namenode(NN)功能:
接受客户端的读写服务
namenode保存metadata信息包括;
- 文件 ownership和permissions
- 文件包含哪些块
- block 保存在那个datanode(由datanode启动时上报)
namenode的metadata信息再启动时会加载到内存
metadata存储在磁盘中的文件名为fsiimage
block位置信息不会保存在fsimage
edits记录对metadata的操作日志
secondaryNamenode:
不是NN的备份,主要工作是帮助NN合并edits log,减少NN启动时间
DataNode:
存储数据
启动DN线程时回想NN会报block信息
通过向NN发送心跳保持联系(3秒一次),如果NN10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其他DN
副本放置策略:
第一个副本:放置在上传文件的DN,如果是集群外提交,则随机挑选一台磁盘不太慢,cpu不太忙的节点
第二个副本:放置在与第一个副本不同机架上的节点
第三个副本:与第二个副本相同的机架的节点
更多副本:随机节点
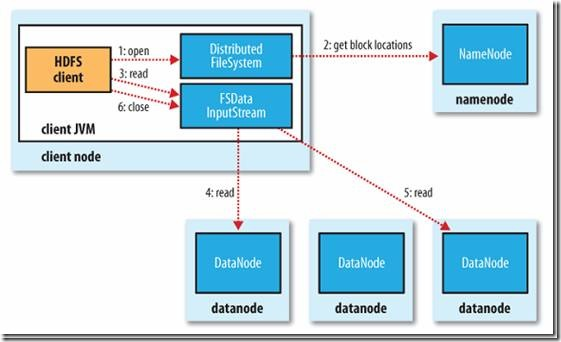
HDFS读流程:
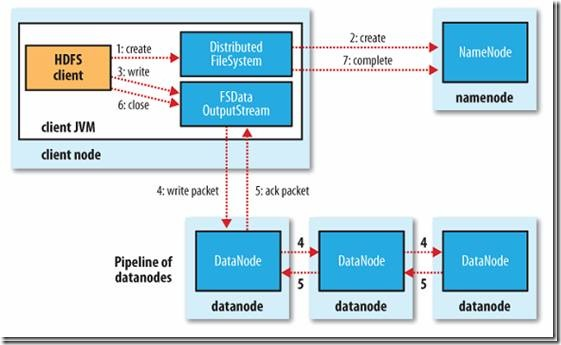
HDFS写流程:
HDFS文件权限:
与linux文件权限类似
安全模式,初始化的阶段,此时namenode的文件系统对于客户端来说是只读阶段:
namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志中的各项操作















 5109
5109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









