







0. 简介
MapTR这类算法在自动驾驶城区NOA中已经必不可少了,MapTR调试记录一文对MapTR解析了不少,而我们希望进一步从代码和论文结合起来,从而了解整个MapTR的整体流程,以及代码是什么样和论文对上的。我们这个系列会对MapTR和MapTR v2进行讲解,从而让读者深入了解这种建图端到端的操作。MapTR解决的是一个实时建图,与此同时也避免了高精地图,自动生成车道和车道的拓扑结构这类的问题。这里感谢疯见损人提供的讲解,大家可以对着看相关的讲解和文章
1. MapTR文章阅读
对于高精地图而言,在前几年做自驾的同学应该明白,很多高精地图厂商在那几年单子很多。但是没有办法落地推广的根本原因是没有办法实时更新,标注成本高。所以现在端到端的建图逐渐替代了高精地图方案。而且现在实时建图这套流程可以形成众包的模式,利用大规模的量产车辆对高精地图进行更新,收集大量车流轨迹信息或单车SLAM 建图结果,在云端融合为准确的语义地图。从而达到实时闭环的作用。
下图绿色的是道路边界,红色的是车道边界,蓝色的是斑马线信息。这种问题主要的解决方法就是通过拓扑结构来完成,当然也有类似Mask2Map这类分割的方法。相关的一些代码的解释可以在基于深度学习的高精地图算法(HDMapNet / VectorMapNet / MapTR / VectorNet)看到。MapTR可以保留点的特征与拓扑结构,没有后处理(端到端)并可以一次性生成所有的矢量点

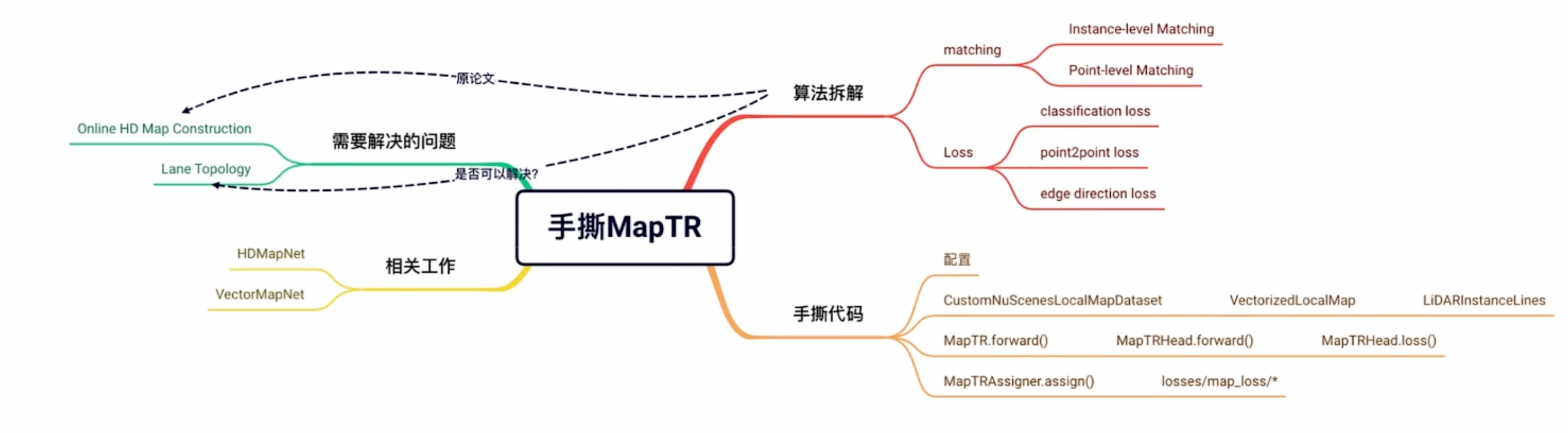
MapTR最核心的问题是,我们在构建高精地图的时候会发现对应的点会存在一个顺时针和逆时针的问题,以及点和点匹配的问题(因为包络的点集不同的shift会有不同的结果)。下面是MapTR的图,这代表了起始点顺序要怎么处理,以及顺时针和逆时针的顺序问题
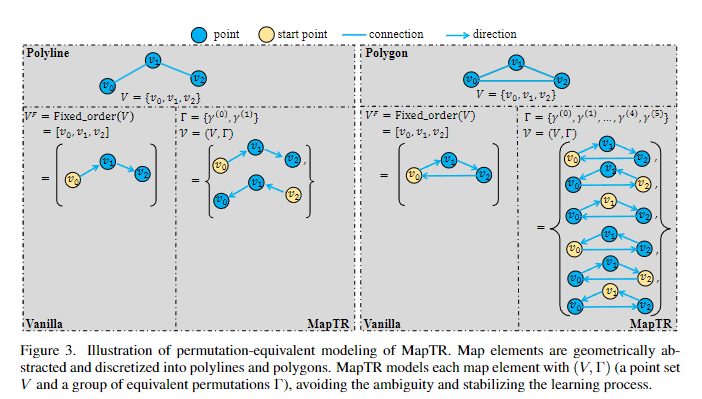
整个流程如下,其中bev feature这块就是使用类lss的方法提取到bev特征,主要的核心工作就是map decoder。其中绿色的是instance queue(每个地图都会出现很多实例),蓝色的是point queue(每个实例都会存在很多点,图中是四个实例),所以会有n*m个点—【这也是MapTRv2中重点改进的部分】。然后会做self-attention和cross-attention中,来获取bev feature的信息。从而变成新的queue。然后就会根据多个头将特征提取出来,并和真值做匹配。通过点对点的形式,使用匈牙利算法来获得匹配的距离信息【Instance-Level matching】;在获取实例化对应关系后,然后就将每个预测的值和对应的真值,找到点和点的对应关系【Point-level matching】;
在函数训练损失层面主要是三块,一个是类别的loss,一个是点对点的曼哈顿距离loss,还有一个是方向的loss【因为比如点的两两组合会产生很多联系,通过方向损失可以约束形状】。值得一提在cost函数中还存在postion的代价函数。即我们在整体数据当中还是需要考虑位置信息的,在学习训练的反馈过程中,则对位置不太敏感
损失函数(Loss Function)
- 定义:损失函数通常用于评估模型在单个训练样本上的预测性能。它计算的是模型预测值与真实值之间的差异。
- 作用:
- 在每次迭代中,它用于计算梯度,指导模型参数的更新。
- 在反馈过程中,损失函数的值可以帮助我们了解模型在特定样本上的表现,从而进行局部调整。
代价函数(Cost Function)- 定义:代价函数通常是损失函数在整个训练集上的平均或总和。它提供了对整个模型性能的整体评估。
- 作用:
- 在训练和验证阶段,代价函数用于评估模型在整个数据集上的表现。
- 它可以用于监控训练过程,判断模型是否收敛,以及进行超参数调优和模型选择。

2. 代码配置
首先我们可以来看一下maptr_nano_r18_110e.py 模型的网络结构在此进行定义,运行时,首先会对下面的模块进行注册,从上到下基本上就是forward的步骤了。当中包括了模型配置、数据集配置、优化器配置、学习率配置、训练周期配置等。每个配置项都有相应的注释说明其作用和含义。
_base_ = [
'../datasets/custom_nus-3d.py', # 数据集配置文件
'../_base_/default_runtime.py' # 默认运行时配置文件
]
#
plugin = True # 启用插件
plugin_dir = 'projects/mmdet3d_plugin/' # 插件目录
# 如果点云范围改变,模型也应相应更改点云范围
point_cloud_range = [-15.0, -30.0, -2.0, 15.0, 30.0, 2.0] # 点云范围
voxel_size = [0.15, 0.15, 4] # 体素大小
# 图像归一化配置
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], # 均值
std=[58.395, 57.12, 57.375], # 标准差
to_rgb=True # 转换为RGB格式
)
# nuScenes通常做10类检测
class_names = [
'car', 'truck', 'construction_vehicle', 'bus', 'trailer', 'barrier',
'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'
]
# 地图类包含:分隔线,行人过街,边界
map_classes = ['divider', 'ped_crossing', 'boundary']
fixed_ptsnum_per_gt_line = 20 # 每个真实目标线固定点数
fixed_ptsnum_per_pred_line = 20 # 每个预测目标线固定点数
eval_use_same_gt_sample_num_flag = True # 评估时是否使用相同的真实样本数量标志
num_map_classes = len(map_classes) # 地图类数量
# 输入模态配置
input_modality = dict(
use_lidar=False, # 不使用激光雷达
use_camera=True, # 使用相机
use_radar=False, # 不使用雷达
use_map=False, # 不使用地图信息
use_external=True # 使用外部信息
)
# Transformer模型参数
_dim_ = 256 # 特征维度
_pos_dim_ = _dim_ // 2 # 位置维度
_ffn_dim_ = _dim_ * 2 # 前馈网络维度
_num_levels_ = 1 # 级别数量
bev_h_ = 80 # 俯视图高度
bev_w_ = 40 # 俯视图宽度
queue_length = 1 # 每个序列包含的帧数
model = dict(
type='MapTR', # 模型类型
use_grid_mask=True, # 使用网格掩模
video_test_mode=False, # 是否为视频测试模式
pretrained=dict(img='ckpts/resnet18-f37072fd.pth'), # 预训练模型路径
img_backbone=dict(
type='ResNet', # 主干网络类型
depth=18, # 网络深度
num_stages=4, # 网络阶段数
out_indices=(3,), # 输出索引
frozen_stages=-1, # 冻结阶段
norm_cfg=dict(type='SyncBN', requires_grad=True), # 归一化配置
norm_eval=False, # 评估模式
style='pytorch' # 风格
),
img_neck=dict(
type='FPN', # 特征金字塔网络类型
in_channels=[512], # 输入通道
out_channels=_dim_, # 输出通道
start_level=0, # 起始层级
add_extra_convs='on_output', # 在输出上添加额外卷积
num_outs=_num_levels_, # 输出层数量
relu_before_extra_convs=True # 在额外卷积之前使用ReLU
),
pts_bbox_head=dict(
type='MapTRHead', # 目标检测头类型
bev_h=bev_h_, # 俯视图高度
bev_w=bev_w_, # 俯视图宽度
num_query=900, # 查询数量
num_vec=100, # 向量数量
num_pts_per_vec=fixed_ptsnum_per_pred_line, # 每个边界框的点数
num_pts_per_gt_vec=fixed_ptsnum_per_gt_line, # 每个真实边界框的点数
dir_interval=1, # 方向间隔
query_embed_type='instance_pts', # 查询嵌入类型
transform_method='minmax', # 变换方法
gt_shift_pts_pattern='v2', # 真实目标点模式
num_classes=num_map_classes, # 类别数量
in_channels=_dim_, # 输入通道数量
sync_cls_avg_factor=True, # 同步类别平均因子
with_box_refine=True, # 是否进行边界框细化
as_two_stage=False, # 是否为两阶段模型
code_size=2, # 编码大小
code_weights=[1.0, 1.0, 1.0, 1.0], # 编码权重
transformer=dict(
type='MapTRPerceptionTransformer', # 变换器类型
rotate_prev_bev=True, # 是否旋转前一个俯视图
use_shift=True, # 是否使用位移
use_can_bus=True, # 是否使用CAN总线数据
embed_dims=_dim_, # 嵌入维度
encoder=dict(
type='BEVFormerEncoder', # 编码器类型
num_layers=1, # 层数
pc_range=point_cloud_range, # 点云范围
num_points_in_pillar=4, # 每个柱中的点数
return_intermediate=False, # 是否返回中间结果
transformerlayers=dict(
type='BEVFormerLayer', # 变换层类型
attn_cfgs=[
dict(
type='TemporalSelfAttention', # 时序自注意力
embed_dims=_dim_, # 嵌入维度
num_levels=1 # 级别数量
),
dict(
type='GeometrySptialCrossAttention', # 几何空间交叉注意力,这是BEVFormer改进模块
pc_range=point_cloud_range, # 点云范围
attention=dict(
type='GeometryKernelAttention', # 几何内核注意力
embed_dims=_dim_, # 嵌入维度
num_heads=4, # 头数量
dilation=1, # 膨胀率
kernel_size=(3, 5), # 内核大小
num_levels=_num_levels_, # 级别数量
im2col_step=192 # im2col步骤
),
embed_dims=_dim_, # 嵌入维度
)
],
feedforward_channels=_ffn_dim_, # 前馈通道数
ffn_dropout=0.1, # 前馈网络丢弃率
operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm') # 操作顺序
)
),
decoder=dict(
type='MapTRDecoder', # 解码器类型
num_layers=2, # 层数
return_intermediate=True, # 是否返回中间结果
transformerlayers=dict(
type='DetrTransformerDecoderLayer', # DETR解码器层类型
attn_cfgs=[
dict(
type='MultiheadAttention', # 多头注意力
embed_dims=_dim_, # 嵌入维度
num_heads=4, # 头数量
dropout=0.1 # 丢弃率
),
dict(
type='CustomMSDeformableAttention', # 自定义多尺度可变形注意力
embed_dims=_dim_, # 嵌入维度
num_levels=1, # 级别数量
im2col_step=192 # im2col步骤
),
],
feedforward_channels=_ffn_dim_, # 前馈通道数
ffn_dropout=0.1, # 前馈网络丢弃率
operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm') # 操作顺序
)
),
bbox_coder=dict(
type='MapTRNMSFreeCoder', # 边界框编码器类型
post_center_range=[-20, -35, -20, -35, 20, 35, 20, 35], # 后置中心范围
pc_range=point_cloud_range, # 点云范围
max_num=50, # 最大数量
voxel_size=voxel_size, # 体素大小
num_classes=num_map_classes # 类别数量
),
positional_encoding=dict(
type='LearnedPositionalEncoding', # 学习位置编码
num_feats=_pos_dim_, # 特征数量
row_num_embed=bev_h_, # 行数嵌入
col_num_embed=bev_w_, # 列数嵌入
),
loss_cls=dict(
type='FocalLoss', # 损失函数类型
use_sigmoid=True, # 使用sigmoid
gamma=2.0, # gamma值
alpha=0.25, # alpha值
loss_weight=2.0 # 损失权重
),
loss_bbox=dict(type='L1Loss', loss_weight=0.0), # 边界框损失
loss_iou=dict(type='GIoULoss', loss_weight=0.0), # IoU损失
loss_pts=dict(type='PtsL1Loss', loss_weight=5.0), # 点损失
loss_dir=dict(type='PtsDirCosLoss', loss_weight=0.005) # 方向损失
),
# 模型训练和测试设置
train_cfg=dict(pts=dict(
grid_size=[512, 512, 1], # 网格大小
voxel_size=voxel_size, # 体素大小
point_cloud_range=point_cloud_range, # 点云范围
out_size_factor=4, # 输出大小因子
assigner=dict(
type='MapTRAssigner', # 分配器类型
cls_cost=dict(type='FocalLossCost', weight=2.0), # 类别成本
reg_cost=dict(type='BBoxL1Cost', weight=0.0, box_format='xywh'), # 回归成本
iou_cost=dict(type='IoUCost', iou_mode='giou', weight=0.0), # IoU成本
pts_cost=dict(type='OrderedPtsL1Cost', weight=5), # 点成本
pc_range=point_cloud_range # 点云范围
)
))
)
dataset_type = 'CustomNuScenesLocalMapDataset' # 数据集类型
data_root = 'data/nuscenes/' # 数据根目录
file_client_args = dict(backend='disk') # 文件客户端参数
train_pipeline = [
dict(type='LoadMultiViewImageFromFiles', to_float32=True), # 加载多视角图像
dict(type='PhotoMetricDistortionMultiViewImage'), # 光度失真
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, with_attr_label=False), # 加载3D标注
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range), # 对象范围过滤
dict(type='ObjectNameFilter', classes=class_names), # 对象名称过滤
dict(type='NormalizeMultiviewImage', **img_norm_cfg), # 归一化多视角图像
dict(type='RandomScaleImageMultiViewImage', scales=[0.2]), # 随机缩放图像
dict(type='PadMultiViewImage', size_divisor=32), # 填充多视角图像
dict(type='DefaultFormatBundle3D', class_names=class_names), # 默认格式打包3D数据
dict(type='CustomCollect3D', keys=['gt_bboxes_3d', 'gt_labels_3d', 'img']) # 自定义收集3D数据
]
test_pipeline = [
dict(type='LoadMultiViewImageFromFiles', to_float32=True), # 加载多视角图像
dict(type='NormalizeMultiviewImage', **img_norm_cfg), # 归一化多视角图像
dict(
type='MultiScaleFlipAug3D', # 多尺度翻转增强
img_scale=(1600, 900), # 图像缩放
pts_scale_ratio=1, # 点云缩放比例
flip=False, # 不翻转
transforms=[
dict(type='RandomScaleImageMultiViewImage', scales=[0.2]), # 随机缩放图像
dict(type='PadMultiViewImage', size_divisor=32), # 填充多视角图像
dict(
type='DefaultFormatBundle3D',
class_names=class_names,
with_label=False # 不带标签
),
dict(type='CustomCollect3D', keys=['img']) # 自定义收集3D数据
]
)
]
data = dict(
samples_per_gpu=24, # 每个GPU样本数
workers_per_gpu=4, # 每个GPU工作线程数
train=dict(
type=dataset_type, # 数据集类型
data_root=data_root, # 数据根目录
ann_file=data_root + 'nuscenes_infos_temporal_train.pkl', # 训练标注文件
pipeline=train_pipeline, # 训练管道
classes=class_names, # 类别名称
modality=input_modality, # 输入模态
test_mode=False, # 测试模式
use_valid_flag=True, # 使用验证标志
bev_size=(bev_h_, bev_w_), # 俯视图大小
pc_range=point_cloud_range, # 点云范围
fixed_ptsnum_per_line=fixed_ptsnum_per_gt_line, # 每条线的固定点数
eval_use_same_gt_sample_num_flag=eval_use_same_gt_sample_num_flag, # 评估时使用相同真实样本数量
padding_value=-10000, # 填充值
map_classes=map_classes, # 地图类
queue_length=queue_length, # 队列长度
box_type_3d='LiDAR' # 3D框类型
),
val=dict(
type=dataset_type, # 数据集类型
data_root=data_root, # 数据根目录
ann_file=data_root + 'nuscenes_infos_temporal_val.pkl', # 验证标注文件
map_ann_file=data_root + 'nuscenes_map_anns_val.json', # 地图标注文件
pipeline=test_pipeline, # 测试管道
bev_size=(bev_h_, bev_w_), # 俯视图大小
pc_range=point_cloud_range, # 点云范围
fixed_ptsnum_per_line=fixed_ptsnum_per_gt_line, # 每条线的固定点数
eval_use_same_gt_sample_num_flag=eval_use_same_gt_sample_num_flag, # 评估时使用相同真实样本数量
padding_value=-10000, # 填充值
map_classes=map_classes, # 地图类
classes=class_names, # 类别名称
modality=input_modality, # 输入模态
samples_per_gpu=1 # 每个GPU样本数
),
test=dict(
type=dataset_type, # 数据集类型
data_root=data_root, # 数据根目录
ann_file=data_root + 'nuscenes_infos_temporal_val.pkl', # 测试标注文件
map_ann_file=data_root + 'nuscenes_map_anns_val.json', # 地图标注文件
pipeline=test_pipeline, # 测试管道
bev_size=(bev_h_, bev_w_), # 俯视图大小
pc_range=point_cloud_range, # 点云范围
fixed_ptsnum_per_line=fixed_ptsnum_per_gt_line, # 每条线的固定点数
eval_use_same_gt_sample_num_flag=eval_use_same_gt_sample_num_flag, # 评估时使用相同真实样本数量
padding_value=-10000, # 填充值
map_classes=map_classes, # 地图类
classes=class_names, # 类别名称
modality=input_modality # 输入模态
),
shuffler_sampler=dict(type='DistributedGroupSampler'), # 分布式分组采样器
nonshuffler_sampler=dict(type='DistributedSampler') # 分布式采样器
)
optimizer = dict(
type='AdamW', # 优化器类型
lr=4e-3, # 学习率
paramwise_cfg=dict(
custom_keys={
'img_backbone': dict(lr_mult=0.1), # 主干网络的学习率倍数
}),
weight_decay=0.01 # 权重衰减
)
optimizer_config = dict(grad_clip=dict(max_norm=50, norm_type=2)) # 梯度裁剪配置
# 学习策略
lr_config = dict(
policy='CosineAnnealing', # 学习率策略
warmup='linear', # 预热策略
warmup_iters=500, # 预热迭代次数
warmup_ratio=1.0 / 3, # 预热比例
min_lr_ratio=1e-3 # 最小学习率比例
)
total_epochs = 110 # 总训练轮数
# evaluation = dict(interval=1, pipeline=test_pipeline) # 评估配置
evaluation = dict(interval=2, pipeline=test_pipeline, metric='chamfer') # 评估配置,使用Chamfer距离
runner = dict(type='EpochBasedRunner', max_epochs=total_epochs) # 运行器配置
log_config = dict(
interval=50, # 日志记录间隔
hooks=[
dict(type='TextLoggerHook'), # 文本日志钩子
dict(type='TensorboardLoggerHook') # Tensorboard日志钩子
]
)
fp16 = dict(loss_scale=512.) # 半精度训练配置
checkpoint_config = dict(interval=5) # 检查点配置
3. 代码学习-----Encoder部分回顾
…详情请参照古月居
# @auto_fp16(apply_to=('img', 'points'))
@force_fp32(apply_to=('img', 'points', 'prev_bev'))
def forward_train(self,
points=None,
img_metas=None,
gt_bboxes_3d=None,
gt_labels_3d=None,
gt_labels=None,
gt_bboxes=None,
img=None,
proposals=None,
gt_bboxes_ignore=None,
img_depth=None,
img_mask=None,
):
"""前向训练函数。
参数:
points (list[torch.Tensor], optional): 每个样本的点云数据。
默认值为 None。
img_metas (list[dict], optional): 每个样本的元信息。
默认值为 None。
gt_bboxes_3d (list[:obj:`BaseInstance3DBoxes`], optional):
真实的3D边界框。默认值为 None。
gt_labels_3d (list[torch.Tensor], optional): 真实的3D边界框标签。
默认值为 None。
gt_labels (list[torch.Tensor], optional): 真实的2D边界框标签。
默认值为 None。
gt_bboxes (list[torch.Tensor], optional): 真实的2D边界框。
默认值为 None。
img (torch.Tensor optional): 每个样本的图像,形状为 (N, C, H, W)。
默认值为 None。
proposals ([list[torch.Tensor], optional): 用于训练 Fast RCNN 的预测提案。
默认值为 None。
gt_bboxes_ignore (list[torch.Tensor], optional): 在图像中要忽略的真实2D边界框。
默认值为 None。
返回:
dict: 不同分支的损失字典。
"""
lidar_feat = None
# 如果模态为 'fusion',提取激光雷达特征
if self.modality == 'fusion':
lidar_feat = self.extract_lidar_feat(points)
len_queue = img.size(1) # 获取图像序列的长度
prev_img = img[:, :-1, ...] # 获取之前的图像帧
img = img[:, -1, ...] # 获取当前的图像帧
prev_img_metas = copy.deepcopy(img_metas) # 深拷贝图像元信息
# 根据之前的图像帧获取历史的鸟瞰图(BEV)
prev_bev = self.obtain_history_bev(prev_img, prev_img_metas) if len_queue > 1 else None
# 更新图像元信息,仅保留当前帧的信息
img_metas = [each[len_queue - 1] for each in img_metas]
# 如果之前的鸟瞰图不存在,则将其设置为 None
if not img_metas[0]['prev_bev_exists']:
prev_bev = None
# 提取当前图像的特征
img_feats = self.extract_feat(img=img, img_metas=img_metas)
losses = dict() # 初始化损失字典
# 根据提取的特征和真实标签进行点云的训练
losses_pts = self.forward_pts_train(img_feats, lidar_feat, gt_bboxes_3d,
gt_labels_3d, img_metas,
gt_bboxes_ignore, prev_bev)
losses.update(losses_pts) # 更新总损失字典
return losses # 返回损失字典
在forward_pts_train中,我们会调用pts_bbox_head来处理整个的encoder和decoder流程,并计算loss来完成模型回馈的操作
def forward_pts_train(self,
pts_feats,
lidar_feat,
gt_bboxes_3d,
gt_labels_3d,
img_metas,
gt_bboxes_ignore=None,
prev_bev=None):
"""前向传播函数,用于训练阶段
参数:
pts_feats (list[torch.Tensor]): 点云分支的特征
gt_bboxes_3d (list[:obj:`BaseInstance3DBoxes`]): 每个样本的真实框
gt_labels_3d (list[torch.Tensor]): 每个样本的真实框标签
img_metas (list[dict]): 样本的元信息
gt_bboxes_ignore (list[torch.Tensor], optional): 需要忽略的真实框. 默认为 None
prev_bev (torch.Tensor, optional): 上一帧的 BEV 特征
返回:
dict: 每个分支的损失
"""
# 使用点云特征、激光雷达特征、图像元信息和上一帧的 BEV 特征作为输入,得到模型的输出
outs = self.pts_bbox_head(
pts_feats, lidar_feat, img_metas, prev_bev)
# 将真实框、真实标签和模型输出组合成损失计算的输入
loss_inputs = [gt_bboxes_3d, gt_labels_3d, outs]
# 计算损失,传入真实框、真实标签和模型输出
losses = self.pts_bbox_head.loss(*loss_inputs, img_metas=img_metas)
# 返回计算得到的损失
return losses
3.1 MapTRHead部分
然后下面我们将需要看一下projects/mmdet3d_plugin/maptr/dense_heads/maptr_head.py文件中Head部分。这部分主要包含了所有的MapTR中所有主要流程
# @auto_fp16(apply_to=('mlvl_feats'))
@force_fp32(apply_to=('mlvl_feats', 'prev_bev'))
def forward(self, mlvl_feats, lidar_feat, img_metas, prev_bev=None, only_bev=False):
"""前向传播函数。
参数:
mlvl_feats (tuple[Tensor]): 来自上游网络的特征,每个特征是一个形状为
(B, N, C, H, W) 的5D张量。
prev_bev: 先前的BEV特征。
only_bev: 仅计算BEV特征,使用编码器。
返回:
all_cls_scores (Tensor): 分类头的输出,形状为 [nb_dec, bs, num_query, cls_out_channels]。其中
cls_out_channels应包括背景。
all_bbox_preds (Tensor): 回归头的Sigmoid输出,采用归一化坐标格式
(cx, cy, w, l, cz, h, theta, vx, vy)。形状为 [nb_dec, bs, num_query, 9]。
"""
# 从mlvl_feats中获取批次大小和相机数量
bs, num_cam, _, _, _ = mlvl_feats[0].shape
dtype = mlvl_feats[0].dtype
# 根据查询嵌入类型初始化对象查询嵌入
if self.query_embed_type == 'all_pts':
object_query_embeds = self.query_embedding.weight.to(dtype)
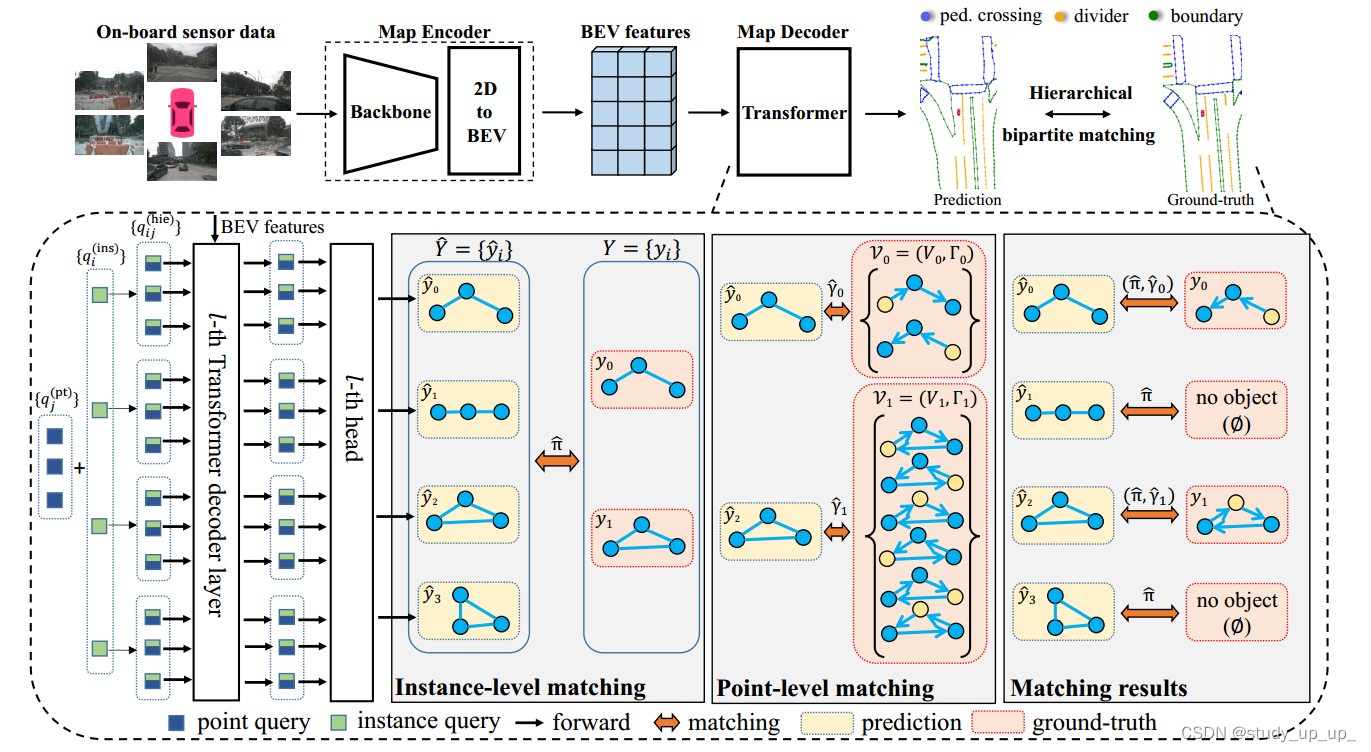
elif self.query_embed_type == 'instance_pts':#这里是双层结构,这套操作对应的是下图的操作
pts_embeds = self.pts_embedding.weight.unsqueeze(0)# 获取点嵌入的权重,并在第0维上增加一个维度,1* M*D包含postion query和 本身query
instance_embeds = self.instance_embedding.weight.unsqueeze(1)# 获取实例嵌入的权重,并在第1维上增加一个维度,N*1*D
# 将点嵌入和实例嵌入相加,然后将结果展平为一维张量
# flatten(0, 1)表示将第0维和第1维展平,形成一个新的张量
# 最后,将结果转换为指定的数据类型(dtype) N*M*D----> NM*D
object_query_embeds = (pts_embeds + instance_embeds).flatten(0, 1).to(dtype)
# 如果存在BEV嵌入,则初始化BEV查询和位置编码,这个是给bevformer用的
if self.bev_embedding is not None:
bev_queries = self.bev_embedding.weight.to(dtype)
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w),
device=bev_queries.device).to(dtype)
bev_pos = self.positional_encoding(bev_mask).to(dtype)
else:
bev_queries = None
bev_mask = None
bev_pos = None
# 如果only_bev为真,仅使用编码器获取BEV特征
if only_bev:
return self.transformer.get_bev_features(
mlvl_feats,
lidar_feat,
bev_queries,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
img_metas=img_metas,
prev_bev=prev_bev,
)
else:
# 通过transformer进行前向传播,这是bevformer的机制,对应下图的Bev Features 部分
outputs = self.transformer(
mlvl_feats,
lidar_feat,
bev_queries,
object_query_embeds,
self.bev_h,
self.bev_w,
grid_length=(self.real_h / self.bev_h,
self.real_w / self.bev_w),
bev_pos=bev_pos,
reg_branches=self.reg_branches if self.with_box_refine else None,
cls_branches=self.cls_branches if self.as_two_stage else None,
img_metas=img_metas,
prev_bev=prev_bev
)
instance_pts操作
然后到Transformer当中做encoder和decoder的操作。这里我们下一节再讲
4. 参考链接
https://blog.csdn.net/weixin_44580210/article/details/128262829


















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











