









论文链接:https://arxiv.org/pdf/2504.11514
代码链接:https://github.com/ForzaETH/LLMxRobot
0. 简介
自动驾驶领域的传统方法多依赖于数据驱动模型,通过大量标注数据训练实现路径规划和控制。然而,现实世界中道路临时施工、突发障碍物等极端场景难以完全涵盖,导致系统在特殊情况下表现不佳。与此同时,大语言模型在自然语言处理领域展现出强大的理解和推理能力,能够处理复杂指令和丰富知识推理。将LLM引入自动驾驶,尤其是本地端部署,既能利用其认知智能,又能避免云端延迟、隐私和安全隐患。
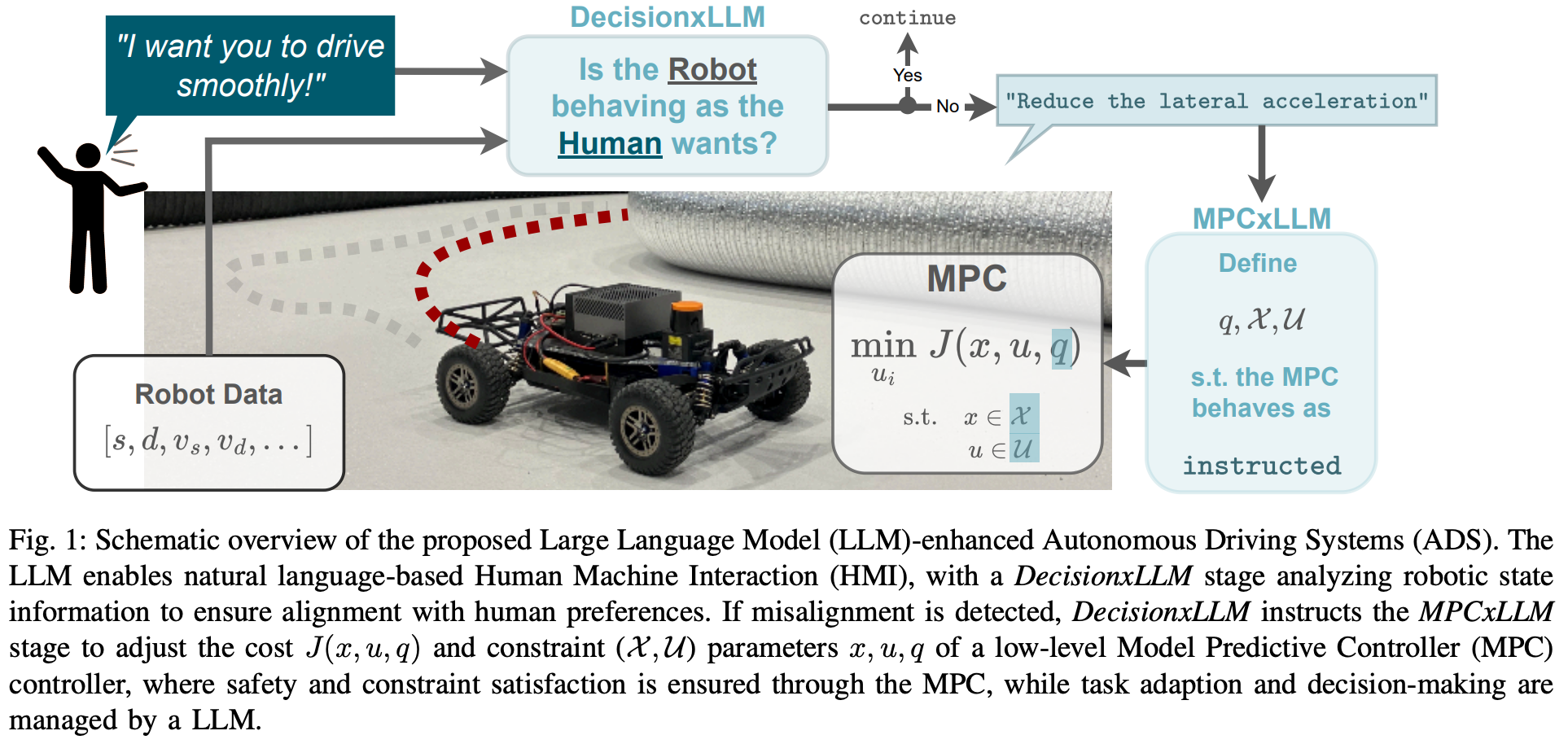
图1:所提出的增强型大型语言模型(LLM)自主驾驶系统(ADS)的示意概述。LLM使基于自然语言的人机交互(HMI)成为可能,其中DecisionxLLM阶段分析机器人状态信息,以确保与人类偏好的对齐。如果检测到不一致,DecisionxLLM将指示MPCxLLM阶段调整低级模型预测控制器(MPC)控制器的成本 J ( x , u , q ) J(x, u, q) J(x,u,q)和约束 ( X , U ) (X, U) (X,U)参数 x , u , q x, u, q x,u,q,在此过程中,MPC确保安全性和约束满足,而任务适应和决策则由LLM管理。
该论文提出的混合架构由三个核心模块组成:
- DecisionxLLM:理解人类自然语言指令,评估车辆当前状态和行为是否符合预期;
- MPCxLLM:将高层自然语言指令转化为对底层MPC控制器参数的调整建议;
- MPC控制器:基于车辆运动学模型执行具体的路径跟踪和速度控制。
1. 主要贡献
创新混合架构设计 :将LLM与MPC深度结合,通过两个协同的LLM模块(DecisionxLLM和MPCxLLM)实现从自然语言指令到具体控制参数的转换,兼顾智能决策与严格控制。
车载本地部署LLM :利用检索增强生成(RAG)、LoRA微调和模型量化等技术,优化LLM模型,使其能够在资源受限的车载硬件(例如NVIDIA Jetson Orin AGX)上高效运行,满足自动驾驶实时性需求。
提升极端场景应对能力和人机交互体验 :通过自然语言交互实现对车辆驾驶行为的灵活调整,增强系统对复杂和罕见场景的适应性,提高用户体验。
丰富的实证验证 :包括定量评估、仿真测试和1:10比例物理机器人平台实验,验证了系统在决策准确率、控制适应性和实时性能上的显著提升。
2. 相关工作
传统自动驾驶系统多采用基于感知的规划与控制方法,模型预测控制(MPC)因其对车辆动力学的良好建模和约束处理能力,被广泛应用于路径跟踪和速度控制。然而,MPC参数固定,难以灵活适应用户偏好和复杂场景变化。
近年来,LLM在自然语言理解和推理方面表现卓越,已有研究尝试将其引入机器人控制和辅助决策,但多依赖云端服务,存在通信延迟和隐私风险。此外,LLM存在生成不确定性(“幻觉”)问题,直接控制车辆存在安全隐患。
本论文基于上述背景,创新性地将LLM本地部署于车载计算单元,结合经典MPC控制器,形成高层智能指令与底层安全控制的有机融合,既利用了LLM的推理优势,也保证了MPC的实时性和安全性。
3. 核心算法与系统架构

图2:1:10比例缩放的机器人平台,使用Jetson Orin AGX作为在地面部署的LLM和ADS自主堆栈的计算执行的机载计算机(OBC)。
3.1 DecisionxLLM模块
- 功能定位:作为系统的“感知与决策中心”,DecisionxLLM模块接收人类通过自然语言下达的驾驶指令(如“请保持车道中央”或“开得更平稳”),并结合车辆传感器收集的状态数据(包括路径坐标、横向偏差、速度等时序信息),对当前车辆行为进行评估。
- 技术亮点:集成检索增强生成(RAG)机制,利用背景知识库补充上下文信息,提升模型对特定驾驶场景和安全约束的理解能力。
- 输出:判断车辆行为是否符合预期,若不符,则生成简洁的自然语言调整指令,传递给MPCxLLM模块。
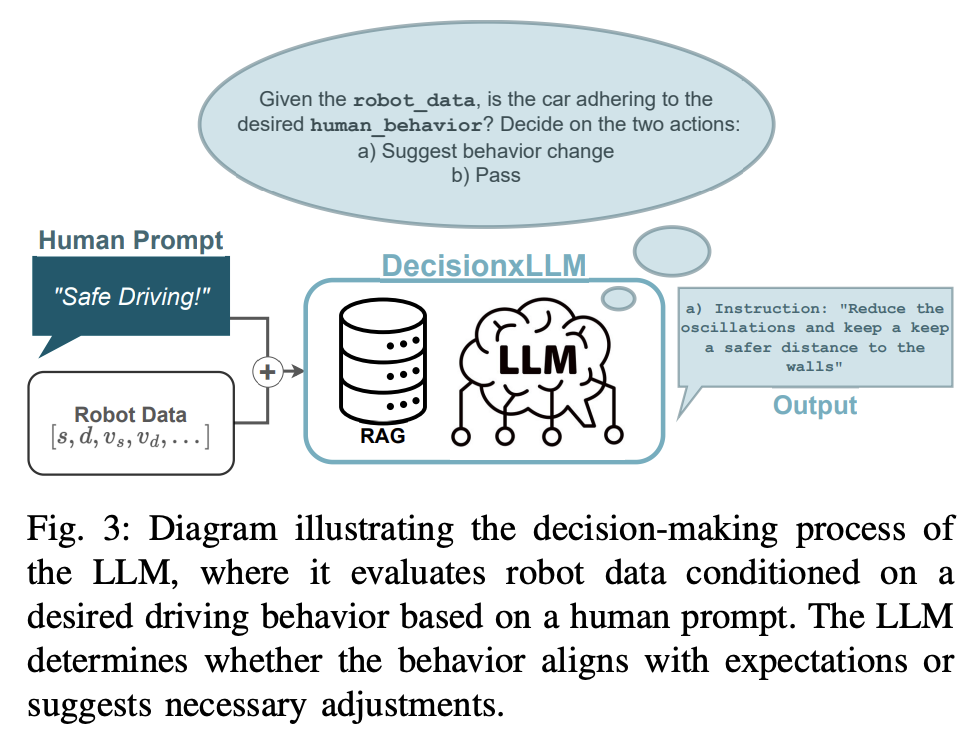
图3:示意图展示了大型语言模型(LLM)的决策过程,其中它根据人类提示评估机器人数据,以实现期望的驾驶行为。LLM判断该行为是否符合预期,或建议必要的调整。
3.2 MPCxLLM模块
- 功能定位:作为高层语义理解与底层控制执行的桥梁,MPCxLLM模块接收DecisionxLLM生成的自然语言调整指令。
- 技术原理:该模块内置的LLM模型理解MPC控制器的数学结构及其可调参数(如成本函数中的权重参数、状态和输入约束集等),将抽象的驾驶行为需求转化为具体的MPC参数调整建议。
- 优势:实现了通过自然语言灵活调整车辆控制策略,且LLM推理延迟与MPC实时控制循环解耦,保证控制稳定性和安全。
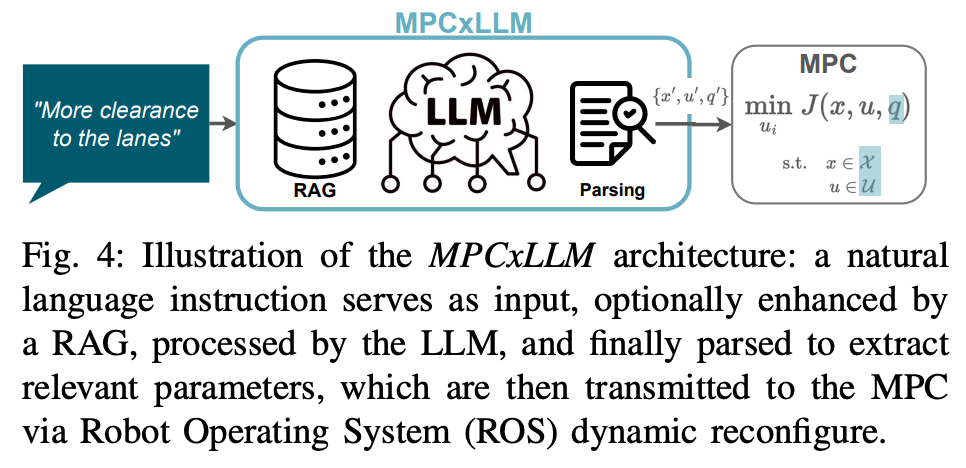
图 4: MPCxLLM 架构的示意图:自然语言指令作为输入, optionally 通过 RAG 进行增强,随后由 LLM 进行处理,最终解析以提取相关参数,这些参数通过机器人操作系统 (ROS) 的动态重新配置传输给 MPC
3.3 基础MPC控制器
- 模型基础:采用车辆运动学模型,描述车辆状态(包括沿参考轨迹的弧长、横向偏差、航向角误差、速度等)随时间的演变。
- 控制目标:通过优化预测时域内的成本函数,实现路径和速度的精准跟踪,同时满足车辆动力学约束和安全约束。
- 参数可调:MPC的权重参数和约束条件由MPCxLLM模块动态调整,以适应不同驾驶风格和环境需求。
3.4 车载部署优化技术
- 检索增强生成(RAG):通过查询相关上下文信息,补充模型输入,减少对超大模型的依赖,提高小型LLM性能。
- LoRA微调:采用参数高效微调技术,利用合成数据对小型LLM进行针对性训练,提升其对机器人任务和MPC参数的理解。
- 模型量化:降低模型参数精度,显著减少内存占用和计算需求,加速推理速度,满足车载计算资源限制。

4. 实验验证
论文通过多层次实验展示了系统性能:
-
DecisionxLLM模块评估
集成RAG和LoRA微调后,基于Qwen2.5-7b模型的DecisionxLLM在判断车辆状态是否符合人类指令的准确率上,最高提升了10.45%。模型量化对性能影响甚微,验证了优化策略的有效性。 -
MPCxLLM模块控制适应性测试
在仿真环境中,不同自然语言指令驱动下,MPCxLLM成功调整MPC参数,实现了车辆行为的显著变化。与固定参数基线相比,路径跟踪和速度跟踪误差(RMSE)平均改善达52.2%。 -
物理机器人平台实测
在1:10比例的自动驾驶小车上,系统能够根据指令(如“离墙远一点”)调整行驶轨迹,遇障碍时自主倒车脱困,表现出良好的鲁棒性和实际应用潜力。 -
推理效率提升
通过模型量化,推理速度提升达10.5倍,满足自动驾驶系统对实时性的严格要求。
5. 结论
本文提出的基于车载部署大语言模型与模型预测控制器相结合的自动驾驶系统架构,有效弥补了传统数据驱动方法在复杂极端场景下的不足。通过DecisionxLLM实现对人类自然语言指令的深度理解与车辆行为评估,MPCxLLM将抽象指令转化为具体控制参数调整,保证了控制的安全性和灵活性。多种优化技术的应用使得强大的LLM能够在资源受限的车载环境中高效运行。


















 6494
6494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











