







4.指标定义系统
序
在拥有了各种数据之后,我们打造了对应的数据仓库,接下来我们就要统计各种各样的数据指标。这些数据指标用来提供给产品、运营相关人员进行相关业务的分析,成为快速的调整业务策略、制定决策方案的数据依据。但是由于产品、运营人员的背景认知不同,对一个相同指标的理解定义可能不同,就会造成数据产品在最终呈现上产生各种各样的歧义。那目前我们面临的问题如下
- 同名指标在不同看板下数据不一致问,经常需要反复确认与排查**(指标同名不同义)**
- 现有的各种需求管理软件并不适合数据指标知识的记录与沉淀积累**(无法按主题沉淀指标)**
- 一个需求一个标准,各种各样的指标定义,人员离职之后,新同学不能快速的理解之前的口径,又需要按照新同学的理解重新开发定义对应的数据报表**(数据理解使用成本高)**
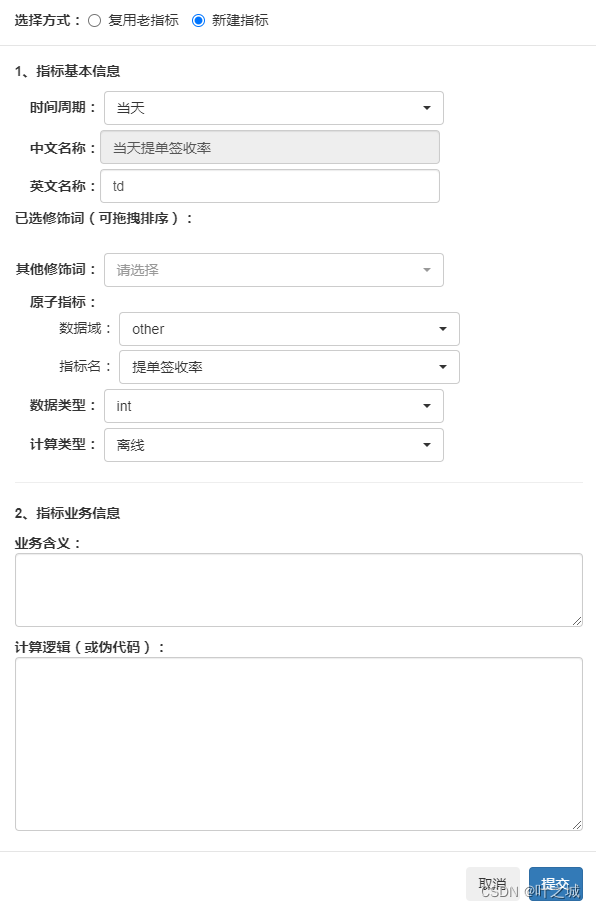
为了解决上述的问题,我们也做过一些尝试,比如:做了一套指标描述的系统,用修饰词+原子指标+时间周期的方式定义指标,这个指标绑定在了结果数据上,虽然在一定程度上解决了问题,但是没办法保证数据统计程序的一致,数据来源一致,还是无法彻底解决 指标同名不同义的问题。
所以需要从指标口径的源头开始去梳理和定义指标,打造一套指标定义系统,这个系统就是数据开发、产品、运营、数据产品、业务RD各方用户对指标定义描述,形成指标共识的地方。在该系统下按照主题划分,在提出数据需求之前,就应该根据日志、表、数仓等相关数据配置与形成对应的数据口径,如果是已有口径,满足需求也无需再次定义与数据开发,让同一个业务线的人员形成统一的标准。后续各种指标开发都依据系统当中定义的规则,对接指标实时、离线模式化统计模块,根据配置直接统计出各个指标数据。
通过该系统从根源上解决上述,指标同名不同义、指标描述、指标沉淀等问题。
系统设计
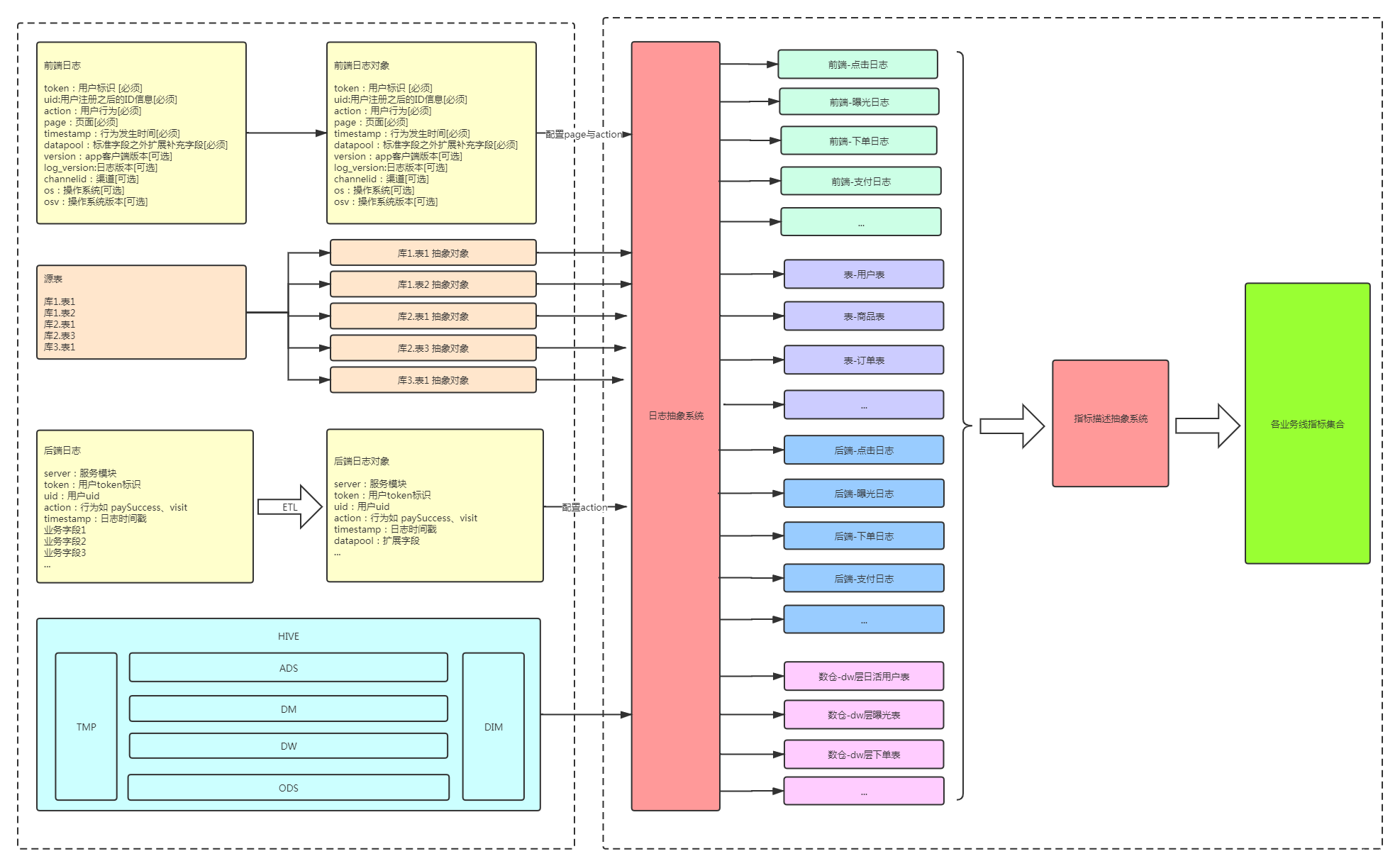
1.数据对象抽象
数据对象抽象包括前端日志、后端日志、源表、数仓表,抽象的对象需要是可解析结构化的数据。
-
日志抽象:日志因为有前端日志、后端日志,前端日志在天然上采用了结构化的日志所以无需进行提前清洗;后端日志根据采用的数据格式,需要提前通过ETL清洗成结构化的数据。结构化的日志最终也是保存在hive对应的表当中,表结构就是一个表抽象对象,可以直接用来表述各个指标的统计规则;
-
源表、数仓表抽象:对应的表结构就是抽象的对象,以此描述指标信息;
2.指标规则描述
-
主题域划分:根据不同的主题划分指标的定义,比如A业务线在提数据需求之前或者需要了解统计指标定义的时候,可以通过系统快速查找到对应主题域下的各类指标信息,未定义的指标可以通过配置完成新指标的创建与规则描述;
-
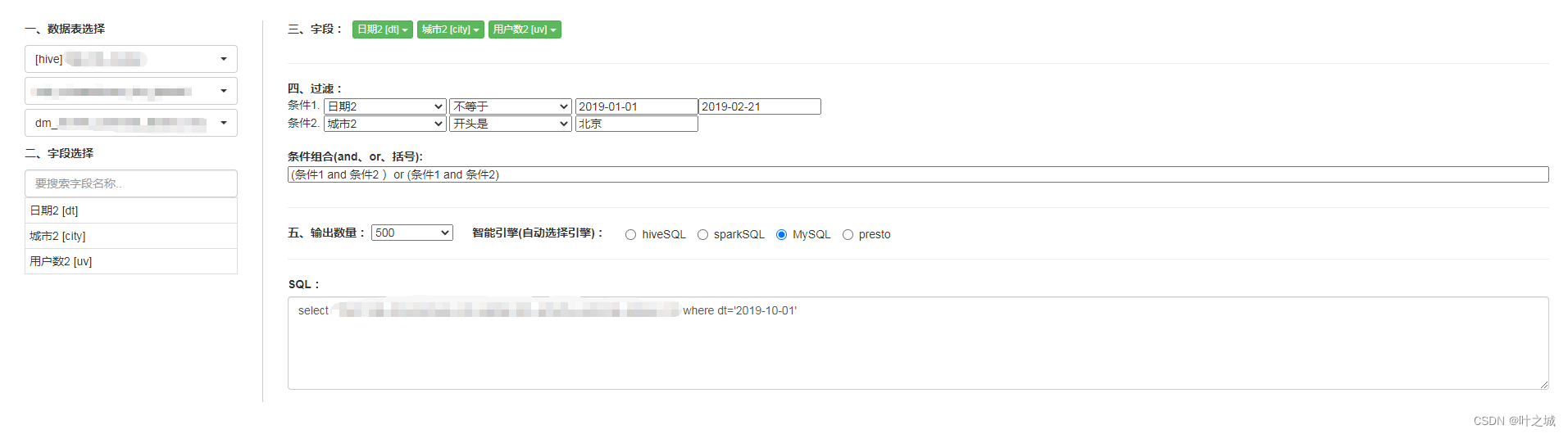
逻辑表达:通过配置化,最大化支持各种情况下指标逻辑的表达,比如过滤、join、聚合、明细等等,最终形成一个可解析的指标配置,后续各种统计系统可以对接配置信息,实现自动化指标的统计与hive数仓表的生成。记录指标规则的各种信息与版本,清晰明了指标口径的变更记录等相关信息。(下图为SQL图形化编辑器,简单示意逻辑表达方式)
系统应用
1、hive数仓表
通过对应离线数据统计系统,配置输入指标配置信息、输出的目的地。由各个指标组合dm层相关的数据表、明细表等。
2、实时、离线指标数据统计
通过对接指标系统,由统计系统解析指标配置,自动化计算与输出结果,达到实时、离线指标统计的自动化。
总结
我们有了这样的一个系统之后,后续的数仓表、数据统计等相关功能都可以与之对接,形成统一口径标准化的数据。整体大数据相关的系统要向着系统化、工具化、配置化、SQL化的方向发展,尽可能的减少人工SQL统计与开发。不光产品、运营通过图形化的SQL完成数据分析等工作,数据开发人员也可以通过图形化SQL配置生成对应的统计逻辑。再通过各个系统之间数据的打通,我们就有着清晰的数据脉络与数据流向。
- 指标来自于业务,沉淀于业务,应用于业务
- 复杂的问题在数据流程越靠前的位置上处理,之后设计的各种系统就会越简单,事半功倍















 2734
2734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









