







3.数据仓库设计
序
数据仓库是为了让人人都可以低成本的使用数据,按照一定标准打造的全量数据资料的集合。
目标

- 数据仓库设计的目标,就是把过去已经发生的非结构化的日志数据转成结构化的数据与后端关系型的数据库里的数据资源进行有效的整合和存储;
- 数据按照特定的逻辑生成不同层级的数据表,以供业务分析人员低成本的使用数据;
- 良好的数仓设计可以保证逻辑的复用、节约计算资源、保证数据质量,降低数据分析成本,提高数据使用效率与价值。
开发原则
- 避免烟囱式数据开发,优先根据主题域设计对应的数据仓库表
- 统计数据严禁从底层数据表直接统计
- 统一库、表、SQL规范
- 数仓地图、逻辑文档的沉淀与推广,形成共识
数仓设计
数据仓库与传统的关系型数据库,由于应用场景与实现技术的差异,数据仓库在设计的时候大多数都是违反关系型数据库三范式进行设计的开发的。
分层

ODS:数据来源层,主要包含业务数据库快照数据(rawdb)、埋点数据(rawdata)、其他业务等数据。
TMP:临时层,数据处理的辅助处理层,服务于DW、DM层,主要是一些中间结果临时存储的数据,包括:计算任务的中间结果数据、ODS层轻度综合和汇总统计的数据等,定期清理。
DIM:维度数据层,主要包含一些字典表、维度数据。实例:品类字典表、城市字典表、终端类型表
DW:data warehouse,存储经过标准规范化处理(即数据清洗)后的运营数据,是基础事实数据明细层。实例:后端日志明细表、前端埋点日志明细表、mysql各业务数据经过ETL处理后的表。
DM:data market(也叫DWS:data warehouse service),数据主题层或者宽表层,按部门按专题进行划分,支持OLAP分析、数据分发等,其信息主要来源于DW 或TMP层汇总数据。实例:新激活用户业务分析表、日活用户业务分析表、历史激活用户业务分析表、用户行为轨迹表、红包业务表、交易品类来源多维表、商业广告多维分析报表
ADS:application database service,应用数据层, 面向具体应用的表,要创建在这层,可导入hbase或mysql等使用。实例:按天、小时、5分钟粒度计算汇总的结果存入mysql、hbase的报表
模型
- 星型模型:核心是一个事实表及多个非正规化描述的维度表组成。
- 雪花模型:是星型模型的扩展,不同的是维度表被规范化,进一步分解到附加表中
- 大星座模型:由多个事实表组合,维表是公共的,可以被多个事实表共享。星座模型是数据仓库最常使用的模型。
数据仓库规范
库规范
数据库命名(集群名_公司名_数据分层_部门)
表规范
ODS:
- raw_业务数据库表名(保持一致)_更新方式(如果增量同步加“_inc”,全量“_full”)_时间粒度
- log_前端/后端日志_更新方式(如果增量同步加“_inc”,全量“_full”)_时间粒度
TMP:
- tmp_数据层类型(dw|dm)_{业务过程描述}
DIM:
- dim_维度类型(cate|city|channel|group)
DW:
- 日志:dw_log_{业务主题域}_{业务过程描述}_更新方式_时间粒度
- 业务数据库:dw_数据库类型(mysql|hbase|wtable|redis){业务主题域}{业务过程描述}_更新方式_时间粒度
- 多数据源:dw_{业务主题域}_{业务过程描述}_更新方式_时间粒度
DM:
- dm_{数据主题域}_{业务过程描述}_更新方式_时间粒度
ADS:
- ads_{业务过程描述}_更新方式_时间粒度
数据主题域
- 交易:trade
- 收入:income
- 推送:push
- 流量:traffic
- 营销:market
- 服务:service
- 商业广告:biz
- 渠道:channel
- 地址:address
- 财务:finance
- 风控:spam
- 竞品:compete
- ……
更新方式命名规范:
- 增量:inc
- 全量:full
- ……
分区表表名时间粒度命名规范:
- 小时(hour):1h
- 天(day):1d
- 周(week):1w
- 月(month):1m
- 季度(quarter):1q
- 年(year):1y
- …
分区字段: 日期分区统一命名为:dt,格式:yyyy-MM-dd or yyyy-MM or yyyy
**非分区表表名时间粒度后面加:**统一为”_0p”
字段
字段命名规范:seller_id、buyer_id、first_from、order_source、xxx_date、xxx_time
日期字段:<业务主体>_date
时间字段:<业务主体>_time
属性字段:属性自身英文单词;如:status
id 字段:<标识主体>id;
标识字段:is<标识主体>;如:is_true
指标字段:时间周期+修饰词+原子指标
计次字段:<计数主体>_pv;如:visit_pv
排重计数字段:<计数主体>_uv;如:visit_uv
价格字段:<业务主体>_price;如:pay_price
来源字段:<业务主体>_source;如:order_source
比例字段:<业务主体>_rate;如:gmv_yoy_rate
元数据管理
1.描述哪些数据在数据仓库中;
2.定义要进入数据仓库中的数据和从数据仓库中产生的数据;
3.记录根据业务事件发生而随之进行的数据抽取工作时间安排;
4.记录并检测系统数据一致性的要求和执行情况;
5.衡量数据质量。
脉络地图
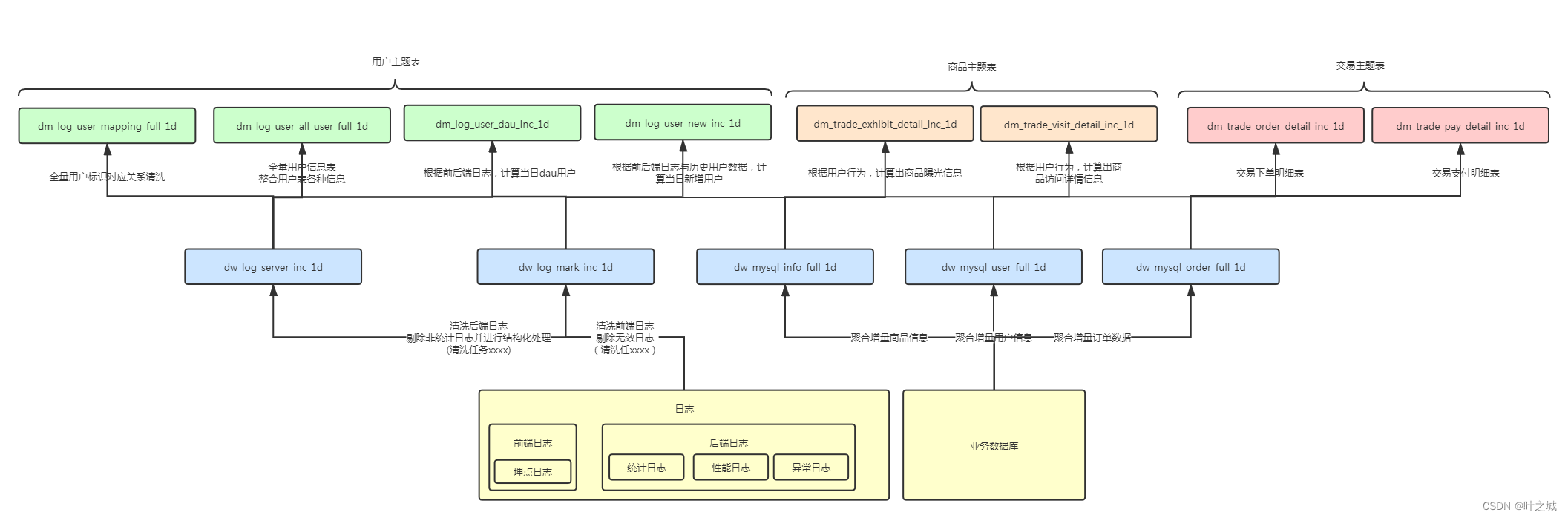
在收集整理了各种日志、业务系统数据之后,我们创建了自己的数据仓库,根据数据仓库的元信息等等,我们应该生成一个数据仓库核心脉络地图,以供其他人员清洗明了的掌握数据仓库的核心表逻辑与结构。当开发一个数据统计需求时,我们可以快速的定位到自己所需使用的表并清晰明了表中数据的逻辑,做到表可用、表敢用、大大降低数据仓库使用沟通成本。
实时数仓
随着技术的发展,大数据处理不断的朝着SQL化,批流合一的方向发展。我们处理数据的速度越来越快,与之对应的就是我们可以带来更快的数据产出,投入到对应的分析场景当中,提升数据时效性充分发掘数据价值。实时数仓可以为我们带来以下几个有点:
- 整体提升数据时效性与价值
- 接入各类实时分析查询引擎提供实时分析能力,比如 druid
- 合理平滑的利用计算资源,无需在凌晨大量离线任务启动,造成资源使用高峰、任务堆积等待。















 3291
3291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









