







动机:
以往的研究主要使用传统的机器学习方法和神经网络来识别行人属性,主要判断自然场景中行人属性的存在性。但是,仅仅判断属性是否存在是不够的,获取属性的位置通常会提供更多的信息。例如,行人的位置信息有助于提高行人重新识别的能力。我们知道,人类将属性的位置作为辅助信息来判断两个行人是否为同一个人。另一方面,如果获得了属性的位置,我们可以对一些已知位置信息的属性进行进一步的研究,比如分析包包的品牌,鞋子的尺码等等。
贡献:
(1)提出了第一个自然场景中行人属性语义数据集PASD(行人属性语义数据集)。
(2)利用语义分割框架deeplabv3+进行实验,得到行人属性的mIoU参考值,为后续工作提供参考。
(3)本文从准确率、PASD行人属性类别百分比、图像分辨率三个方面对mIoU进行分析。总结了行人属性mIoU的影响因素。
mIoU(mean intersection over union)
方法:
使用deeplabv3+作为行人属性分析的基本模型。该模型结合了deeplabv3和encoderdecoder的优点。
Deeplabv3包含了基于卷积和基于空间金字塔池(ASPP)的关键结构。Deeplabv3+在基础模型中加入了Xception,大大提高了训练效率。
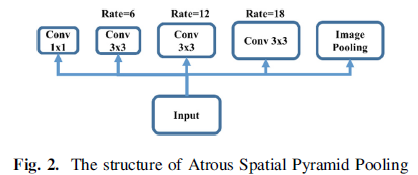
ASPP的特点是多用途以不同速率并行地进行卷积,并对每个分支的结果进行concat以得到最终结果。空间金字塔池如下图所示。
深度可分离卷积。将原始卷积分离为深度卷积和点态卷积。深度可分离卷积的结构如图3所示。在二维空间金字塔池中,Deeplabv3+还采用了深度可分离卷积,在保证精度的前提下,提高了计算效率。结构如下所示::


Xecption。最初的Xception使用了36个卷积层。该网络分为三部分:入口流、中间流和出口流。Deeplabv3+使用了Xception的改进版本,并做了以下三个改变:(1)采用与源网络相同的深度Xception,只是为了快速计算和提高内存效率而不修改入口流网络结构。(2)将所有最大pooling操作替换为带striding的深度可分离卷积,使网络能够以任意分辨率提取feature map。(3)每个3 * 3深度卷积后加入ReLU和批处理归一化。
Encoder-Decoder。Deeplabv3+使用Deeplabv3作为编码器。Deeplabv3使用阿劳斯卷积以任意分辨率提取特征图。引入了一个新的参数输出stride来表示输入图像大小与输出图像大小的比值。例如,最终的feature map通常是输入的1/32,输出stride的值是32。在语义分割中,输出stride通常设置为16或8。Deeplabv3+使用了改进的Atrous空间金字塔池,添加了一个图像级特征(由avgpool实现)和concat与Atrous卷积的不同比率。这个集中的值作为编码器的输出。
在解码器部分,deeplabv3 +提出了适合语义分段的解码器结构。 首先,将编码器的输出以4的系数进行上采样,然后将其与包含相同空间大小的编码器中的低级特征合并,并使用1 * 1卷积来减少通道数,这使得训练很容易成为低点。 编码器的高级别功能始终包含很多通道。
Deeplabv3+使用cross-entropy softmax作为损失函数。
Deeplabv3+的整体框架如下所示

PASD数据集的构建
图片的选择:
选取的是peta数据集中的图片,参照下面两个标准。以及250个由城市监控摄像机拍摄的真实场景中的行人图像。这些图像的分辨率比PETA的要高。
1.图像分辨率:选择基于人的识别选择语义分割的图像,忽略未被人识别的图像。(分辨率高的以及人能识别的吧)
2.类别的平衡。对于有些类别只有很少的数量(比如条纹、网格),尝试保持这些类别的平衡。
分类的选择:
首先参考PETA的行人属性选择方法。PETA根据人类学家选择的代表人类特征的属性和数据集本身的属性类别,将行人属性分为35个类别。考虑到属性在训练集中的分布,某些属性(如年龄、性别等)不能通过语义分割来分离和可视化。最后选取了27个行人属性。属性值如下表所示。

PASD由1711个语义分割注释组成,其中PETA数据集1461个,自己的数据集250个。
实验:
随机选取1273张图像作为训练数据。测试数据选取288幅图像,其中低分辨率图像188幅,高分辨率图像100幅。288张测试集图像的mIoU如下表所示。

mIoU与类别比关系的折线图

可以发现以下因素对类别mIoU的影响:(1)如果类别轮廓是固定的或者具有独特的可视化特征,则可以得到较高的mIoU。比如手提箱、布条、夹克衫。相反,对于类别多样性较多的类别,则得到相对较低的mIoU。比如鞋子,它在自然场景中具有可变性和不确定性,也就是说,人眼无法分辨它是哪一种鞋子。(2)图像分辨率,如太阳镜,大部分太阳镜在数据集中难以清晰识别。(3)类别比例仍然起着关键作用。
mIoU与准确性的关系:
除mIoU外,还输出了27种预测精度。这里计算精度的方法是,如果图像中某个类别的累计像素个数大于10,则认为该图像包含了该类别。288张测试集图像的计算精度如下表所示。

上表中应该是accuracy

mIoU与Resolution的关系
















 9308
9308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









