







 不足之处Kmeans聚类时间长词袋表征特征的过程其实牵涉到量化的过程,这其实损失了特征的精度。检索模块设计的太粗糙,速度太慢没有设计反馈系统,系统无法自动升级主要还是慢和精度不高(这么点图片,聚类就花了很久)1、使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。有方法是在海量图片中抽取部分训练集分类,使用朴素贝叶斯分类的方法对图库中其余图片进行自动分类。另外,由于图片爬虫在不断更新后台图像集,重新聚类的代价显而易见。2、字典大小的
不足之处Kmeans聚类时间长词袋表征特征的过程其实牵涉到量化的过程,这其实损失了特征的精度。检索模块设计的太粗糙,速度太慢没有设计反馈系统,系统无法自动升级主要还是慢和精度不高(这么点图片,聚类就花了很久)1、使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。有方法是在海量图片中抽取部分训练集分类,使用朴素贝叶斯分类的方法对图库中其余图片进行自动分类。另外,由于图片爬虫在不断更新后台图像集,重新聚类的代价显而易见。2、字典大小的
文章目录
一、Bow(Bag of words)模型简介
1.1 原理
- Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。
- 简单说就是将每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后根据袋子里装的词汇对其进行分类。如文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
- 根据每个单词在文本中出现的权重,便可构造单词的频率直方图。词表就相当于直方图的基,新来要表述的文档向这个基上映射。

1.2 模型应用到图像检索中
为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇之间没有顺序。


1.2.1 特征提取
- 由于图像中的词汇不像文本文档那样是现成的单词,所以我们首先要从图像中提取出相互独立的视觉词汇。然后为创建视觉单词词汇,第一步要做的就是提取特征描述子。
- SIFT算法是提取图像中局部不变特征的应用最广的算法,所以我们可以采用SIFT算法才进行特征提取。
- 将每幅图像提取出的描述子保存在一个文件中,构建视觉词典。
1.2 2 学习 “视觉词典(visual vocabulary)”
聚类是实现 visual vocabulary /codebook的关键 ,最常见的聚类方法就是,K-means 聚类算法。
(1)随机初始化 K 个聚类中心
(2)对应每个特征,根据距离关系赋值给某个中心/类别 。其中距离的计算可采用欧式距离:
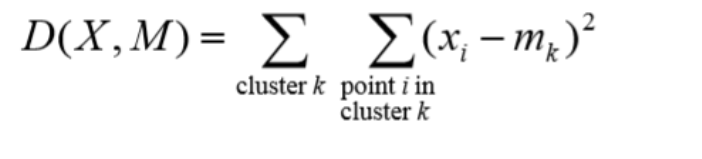
(3)对每个类别,根据其对应的特征集重新计算聚类中心
重复(2)、(3)步骤,直至算法收敛
1.2.3 针对输入特征集,根据视觉词典进行量化
对于输入特征,量化的过程是将该特征映射到距离其最接近的视觉单词,并实现计数 。选择合适的视觉词典的规模是我们需要考虑的问题,若规模太少,会出现视觉单词无法覆盖所有可能出现的情况 。若规模太多,又会计算量大,容易过拟合 。只能通过不断的测试,才能找到最合适的词典规模。
1.2.4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









