






我们以下面这句话为例子来说明一下Transformer中的自注意力机制:
我 是 小 狗
一、将token嵌入
首先要将每一个字(token)嵌入为一个向量,这里可以采用one-hot编码等。假设每个嵌入向量的维度都为512维。我们将“我”表示为,“是”嵌入的向量表示为
...那么由所有嵌入向量组成的嵌入矩阵就为:
将该嵌入矩阵(Input Embedding)加上位置编码就得到了输入矩阵,将该矩阵记作,表示为:
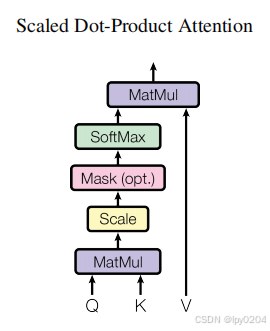
二、生成Q、K、V向量
我们首先随机生成三个矩阵,
,
,意为Query、Key以及value,他们的第一维度一定都为512维(要与
相乘),我们假设它的第二维度都是64维,即
(与原始论文一致)。它们的作用相当于神经网络中各层的权重,是要逐渐地被训练的。将
和以上三个矩阵分别相乘得到了Q、K、V三个矩阵,即最上面图片中的"Scaled Dot-Product Attention"中的三个输入。
其中是"我"的Query向量,
是"是"的Query向量......
三、MatMul
然后将Q和K的转置相乘:
我们知道相当于是
在
上的投影,投影数值的大小反映了
对
的注意力大小。在该矩阵中第
行反映了
对其他
的注意力大小(包括自己)。
四、Scale
这一步就是简单地将的值除以
(原论文中采用的),这样做的目的是防止向量内积过大(因为这些大数值在缩放后要通过softmax函数,由于softmax函数的性质,它会放大数值差异,导致数值稳定性问题。在反向传播时,这可能会导致梯度消失或爆炸)。
五、Mask(可选)
从前面的推导可以得知,Transformer会同时计算每一个token对其他所有token的注意力。但是当我们进行预测时,我们是不能看到(注意到)当前token往后的所有token的,所以不能计算当前token对后面的token的注意力。方法就是将中的上三角区域(除去主对角线)全部变为-inf,这样在进行softmax后值为-inf的部分就全部变为0。
六、Softmax
用softmax将每一行转换为一个概率分布,每行中的所有元素和为1。
其中表示了一个权重,即
应该放多少比例的注意力到
上。例如当
进行Mask和Softmax操作后,它的第一行会变成
,也就是说
应该把全部注意力放在
上,而对于其他
则不应该关注。
七、MatMul
将这个比例再乘以value(值)矩阵进行点乘,得到了注意力
的最终形式:
第一行由四项相加,即应该放到
上的注意力比例乘以
的值
+ 应该放到
上的注意力比例乘以
的值
+ 应该放到
上的注意力比例乘以
的值
+ 应该放到
上的注意力比例乘以
的值
若该结果和比较接近,则说明
的值很接近1,而其他
则很接近于0,则
更应该把注意力放到
上。总而言之就是重要的信息更关注,不重要的信息被忽视了,这时我们就能根据该值来更好地进行预测。


















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











