










Seq2seq是现在使用广泛的一种序列到序列的深度学习算法,在图像、语音和NLP,比如:机器翻译、机器阅读、语音识别、智能对话和文档摘要生成等,都有广泛的应用。Seq2Seq模由encoder和decoder两个部分来构成,假设模型的训练样本为(X,Y),encoder负责把输入X映射到隐向量Z,再由decoder把Z映射到输出Y。现在大多数场景下使用的Seq2Seq模型基于RNN构成的,虽然取得了不错的效果,但也有一些学者发现使用CNN来替换Seq2Seq中的encoder或decoder可以达到更好的效果。最近,FaceBook帆布一篇论文:《Convolutional Sequence to Sequence Learning》,提出了完全使用CNN来构成Seq2Seq模型,用于机器翻译,超越了谷歌创造的基于LSTM机器翻译的效果。
1
论文及代码下载地址
论文下载地址:https://arxiv.org/abs/1705.03122
开源代码github地址:https://github.com/facebookresearch/fairseq
2
Convolutional Seq2Seq中采用各种trick
FaceBook发布的这篇文章的工作持续时间比较长了,依赖于《Language Modeling with Gated Convolutional Networks》文章中的工作。个人认为,FaceBook的Convolutional SeqSeq取得了超越Google翻译的成果,重要原因在于采用了很多的trick,很多工作值得借鉴:
1、Position Embedding,在输入信息中加入位置向量P=(p1,p2,....),把位置向量与词向量W=(w1,w2,.....)求和构成向量E=(w1+p1,w2+p2),做为网络输入,使由CNN构成的Encoder和Decoder也具备了RNN捕捉输入Sequence中词的位置信息的功能。
2、层叠CNN构成了hierarchical representation表示。层叠的CNN拥有3个优点:
(1)捕获long-distance依赖关系。底层的CNN捕捉相聚较近的词之间的依赖关系,高层CNN捕捉较远词之间的依赖关系。通过层次化的结构,实现了类似RNN(LSTM)捕捉长度在20个词以上的Sequence的依赖关系的功能。
(2)效率高。假设一个sequence序列长度为n,采用RNN(LSTM)对其进行建模 需要进行n次操作,时间复杂度O(n)。相比,采用层叠CNN只需要进行n/k次操作,时间复杂度O(n/k),k为卷积窗口大小。
(3)可以并行化实现。RNN对sequence的建模依赖于序列的历史信息,因此不能并行实现。相比,层叠CNN正个sequence进行卷积,不依赖序列历史信息,可以并行实现,模型训练更快,特别是在工业生产,面临处理大数据量和实时要求比较高的情况下。
3、融合了Residual connection、liner mapping的多层attention。通过attention决定输入的哪些信息是重要的,并逐步往下传递。把encoder的输出和decoder的输出做点乘(dot products),再归一化,再乘以encoder的输入X之后做为权重化后的结果加入到decoder中预测目标语言序列。
4、采用GLU做为gate mechanism。GLU单元激活方式如下公式所示:

每一层的输出都是一个线性映射X*W + b,被一个门gate:o(X*V+c)控制,通过做乘法来控制信息向下层流动的力度,o采用双曲正切S型激活函数。这个机制类似LSTM中的gate mechanism,对于语言建模非常有效,使模型可以选择那些词或特征对于预测下一个词是真的有效的。
5、进行了梯度裁剪和精细的权重初始化,加速模型训练和收敛。
3
完整的网络结构分析
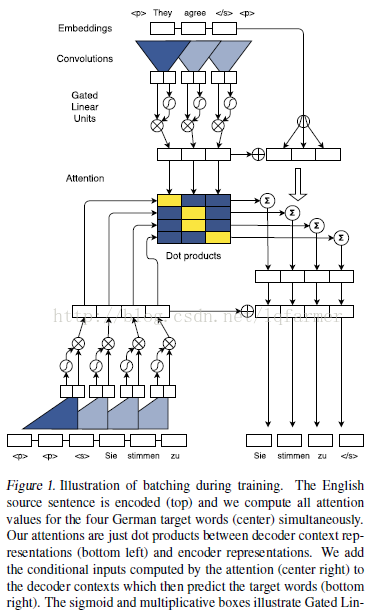
Figure1是论文中给出的的Convolutional Seq2Seq的结构,看起来有点复杂,其实挺简单的。下面简要分析下是如何与上述5个trick结合起来的:
上左encoder部分:通过层叠的卷积抽取输入源语言(英语)sequence的特征,图中直进行了一层卷积。卷积之后经过GLU激活做为encoder输出。
下左decoder部分:采用层叠卷积抽取输出目标语言(德语)sequence的特征,经过GLU激活做为decoder输出。
中左attention部分:把decoder和encoder的输出做点乘,做为输入源语言(英语)sequence中每个词权重。
中右Residual connection:把attention计算的权重与输入序列相乘,加入到decoder的输出中输出输出序列。
4
最后实验结论
在多个公开数据集上获得了新的state-of-the-art的成绩。在WMT-16、英语-罗马尼亚语翻译,高出以前方法1.8 BLEU;在WMT-14、英语-法语翻译,比以前LSTM模型所取得的成绩高出1.5 BLEU;在WMT-14、英语-德语翻译,比以前方法高出0.5 BLEU。
5
总结
个人感觉本文采用了很多简单且非常有效的trick,达到了基于LSTM的NMT方法更好的效果,正因为如此,并不能说,基于CNN seq2seq模型就一定比基于LSTM的Seq2Seq一定好。采用CNN的Seq2Seq最大的优点在于速度快,效率高,缺点就是需要调整的参数太多。上升到CNN和RNN用于NLP问题时,CNN也是可行的,且网络结构搭建更加灵活,效率高,特别是在大数据集上,往往能取得比RNN更好的结果。
6
下期预告
下期将给大家带来基于Convolutional Seq2Seq实战,尽情期待。
















 3465
3465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











