






一、导入需要的包
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import copy
import time
import torch
import torch.nn as nn
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST其中,torch.nn :包含用于构建神经网络的模块和可扩展类的子包;
torchvision是pytorch中的一个图形库;torch.utils.data实现自由的数据读取。
二、数据导入
我们以FashionMNIST为例:
# 准备训练数据集
train_data = FashionMNIST(
root="./FashionMNIST", # 数据的路径
train=True, # 只使用训练数据集
transform=transforms.ToTensor(), # 用于对载入的图片数据进行类型转换,将之前构成 PIL 图片的数据转换成 Tensor 数据类型的变量,让 PyTorch 能够对其进行计算和处理。
download=False
)
# 准备测试数据集
test_data = FashionMNIST(
root="./FashionMNIST", # 数据的路径
train=False, # 只使用训练数据集
download=False
)其中,root表示数据集保存的目录名称;train=true表示导入训练集;train=false表示导入测试集;transform=transforms.ToTensor()表示将对载入的图片数据进行类型转换,将之前构成 PIL 图片的数据转换成 Tensor数据类型的变量,让pytorch 能够对其进行计算和处理。
三、预处理
# 定义一个数据加载器
train_loader = Data.DataLoader(
dataset=train_data, # 使用的数据集
batch_size=64, # 批处理样本大小
shuffle=False, # 每次迭代前不打乱数据
# num_workers=2, # 使用两个进程
)
# 获取一个batch的数据
for step, (b_x, b_y) in enumerate(train_loader):
if step > 0:
break
# 一个batch里的图片可视化
batch_x = b_x.squeeze().numpy()
batch_y = b_y.numpy()
class_label = train_data.classes
plt.figure(figsize=(12, 5))
for ii in np.arange(len(batch_y)):
plt.subplot(4, 16, ii+1)
plt.imshow(batch_x[ii, :, :], cmap=plt.cm.gray)
plt.title(class_label[batch_y[ii]], size=9)
plt.axis("off")
plt.subplots_adjust(wspace=0.05)
plt.show()
# 测试集数据预处理
test_data_x = test_data.data.type(torch.FloatTensor)/255.0
test_data_x = torch.unsqueeze(test_data_x, dim=1) # [10000, 1, 28, 28]
test_data_y = test_data.targets # 测试集的标签 [10000]
Data.DataLoader加载数据,batch_size为批量处理样本大小;shuffle是将列表的所有元素随机排序。
torch.unsqueeze函数将在指定维度插入新的维度;test_data.data提取训练数据;train_data.classes提取标签。
四、网络结构的定义
通过继承nn.Module父类来定义CNN子类,包含卷积层、池化层、全连接层结构和向前传播过程。
在此我们将搭建一个具有两层卷积层的网络结构,卷积后使用relu激活函数进行激活,采用平均池化,两个全连接层分别包含256和128个神经元,最后的分类器包含10个神经元。
# 定义网络结构
class MyConvNet(nn.Module):
def __init__(self):
super(MyConvNet, self).__init__()
# 定义第一个卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1, # 输入的图片 (1,28,28)
out_channels=16, # 经过一个卷积层之后 (16,28,28)
kernel_size=3, # 卷积核尺寸
stride=1,
# 如果想要 con2d 出来的图片长宽没有变化, padding=(kernel_size-1)/2 当 stride=1
padding=1,
),
nn.ReLU(),
nn.AvgPool2d(
kernel_size=2, # 平均池化层,2*2
stride=2, # 池化步长2
), # 经过池化层处理,维度为(16,14,14)
)
# 定义第二个卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16, # 输入(16,14,14)
out_channels=32, # 输出(32,12,12)
kernel_size=3,
stride=1,
padding=0,
), # 输出(32,12,12)
nn.ReLU(),
nn.AvgPool2d(
kernel_size=2, # 平均池化层,2*2
stride=2, # 池化步长2
), # 输出(32,6,6)
)
self.classifier = nn.Sequential(
nn.Linear(32 * 6 * 6, 256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128, 10),
)
# 定义网络向前传播路径
def forward(self, x):
x = self.conv1(x) # (batch_size,16,14,14)
x = self.conv2(x) # (batch_size,32,6,6)
x = x.view(x.size(0), -1) # (batch_size,32*6*6)
output = self.classifier(x) # (batch_size,10)
return output
myconvnet = MyConvNet()五、模型训练
定义训练函数train_model(),采用80%的batch进行训练,20%的batch进行验证。
在每一个epoch中分别有两个过程,当step < train_batch_num,进入训练模式;当step >= train_batch_num,进入验证模式。
这里的训练模式和验证模式的意义参考官方文档:
由于在验证或者测试时,我们不需要模型中的某些层起作用或者不希望某些层的参数被改变(i.e. BatchNorm层、Dropout层),这时就需要设置成model.eval()模式;但是在训练模型的时候又希望这些层起作用,这时候就需要用到model.train()模式。
其中,每一个epoch中损失函数loss需要叠加,最后除以训练总数计算平均损失。loss.item()将单个元素tensor转化为int或者float,避免了计算图中loss的叠加,从而避免显存爆炸。
# 定义网络训练过程函数
def train_model(model, traindataloader, train_rate, criterion, optimizer, num_epochs):
batch_num = len(traindataloader) # 获取训练总batch数
train_batch_num = round(batch_num * train_rate) # 按照train_rate比例进行训练集的划分
# 复制模型参数
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
train_loss_all = []
train_acc_all = []
val_loss_all = []
val_acc_all = []
since = time.time()
# 训练轮次循环
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs-1))
train_loss = 0.0
train_corrects = 0
train_num = 0
val_loss = 0.0
val_corrects = 0
val_num = 0
# 每个epoch有两个训练阶段
for step, (b_x, b_y) in enumerate(traindataloader):
if step < train_batch_num: # 训练集
model.train() # 设置模型为训练模式
output = model(b_x)
pre_lab = torch.argmax(output, 1)
loss = criterion(output, b_y) # 计算损失函数
optimizer.zero_grad() # 清空上一层梯度
loss.backward() # 反向传播
optimizer.step() # 更新优化器的学习率
train_loss += loss.item() * b_x.size(0)
train_corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0)
else:
model.eval() # 设置模型为评估模式
output = model(b_x)
pre_lab = torch.argmax(output, 1)
loss = criterion(output, b_y)
val_loss += loss.item() * b_x.size(0)
val_corrects += torch.sum(pre_lab == b_y.data)
val_num += b_x.size(0)
# 计算一个epoch在训练集和验证集上的损失和精度
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.double().item()/train_num)
val_loss_all.append(val_loss / val_num)
val_acc_all.append(val_corrects.double().item()/val_num)
print('{} Train Loss: {:.4f} Train Acc: {:.4f}'.format(epoch, train_loss_all[-1],
train_acc_all[-1]))
print('{} Val Loss: {:.4f} Val Acc: {:.4f}'.format(epoch, val_loss_all[-1], val_acc_all[-1]))
# 当精度创新高,复制模型最高精度下的参数
if val_acc_all[-1] > best_acc:
best_acc = val_acc_all[-1]
best_model_wts = copy.deepcopy(model.state_dict())
time_use = time.time() - since
print("Train and val complete in {:.0f}m {:.0f}s".format(time_use // 60, time_use % 60))
# 使用最好模型的参数
model.load_state_dict(best_model_wts)
train_process = pd.DataFrame(
data={"epoch": range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all": train_acc_all,
"val_acc_all": val_acc_all,
}
)
return model, train_process六、模型训练
# 对模型进行训练
optimizer = torch.optim.Adam(myconvnet.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss() # 损失函数
myconvnet, train_process = train_model(
myconvnet, train_loader, 0.8,
criterion, optimizer, num_epochs=25
)
# 对测试集进行预测,并可视化预测效果
myconvnet.eval()
output = myconvnet(test_data_x)
pre_lab = torch.argmax(output, 1)
acc = accuracy_score(test_data_y, pre_lab)七、结果可视化
# 训练结果可视化
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process.epoch, train_process.train_loss_all, "ro-", label="train loss")
plt.plot(train_process.epoch, train_process.val_loss_all, "bs-", label="val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.subplot(1, 2, 2)
plt.plot(train_process.epoch, train_process.train_acc_all, "ro-", label="train acc")
plt.plot(train_process.epoch, train_process.val_acc_all, "bs-", label="val acc")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.show()
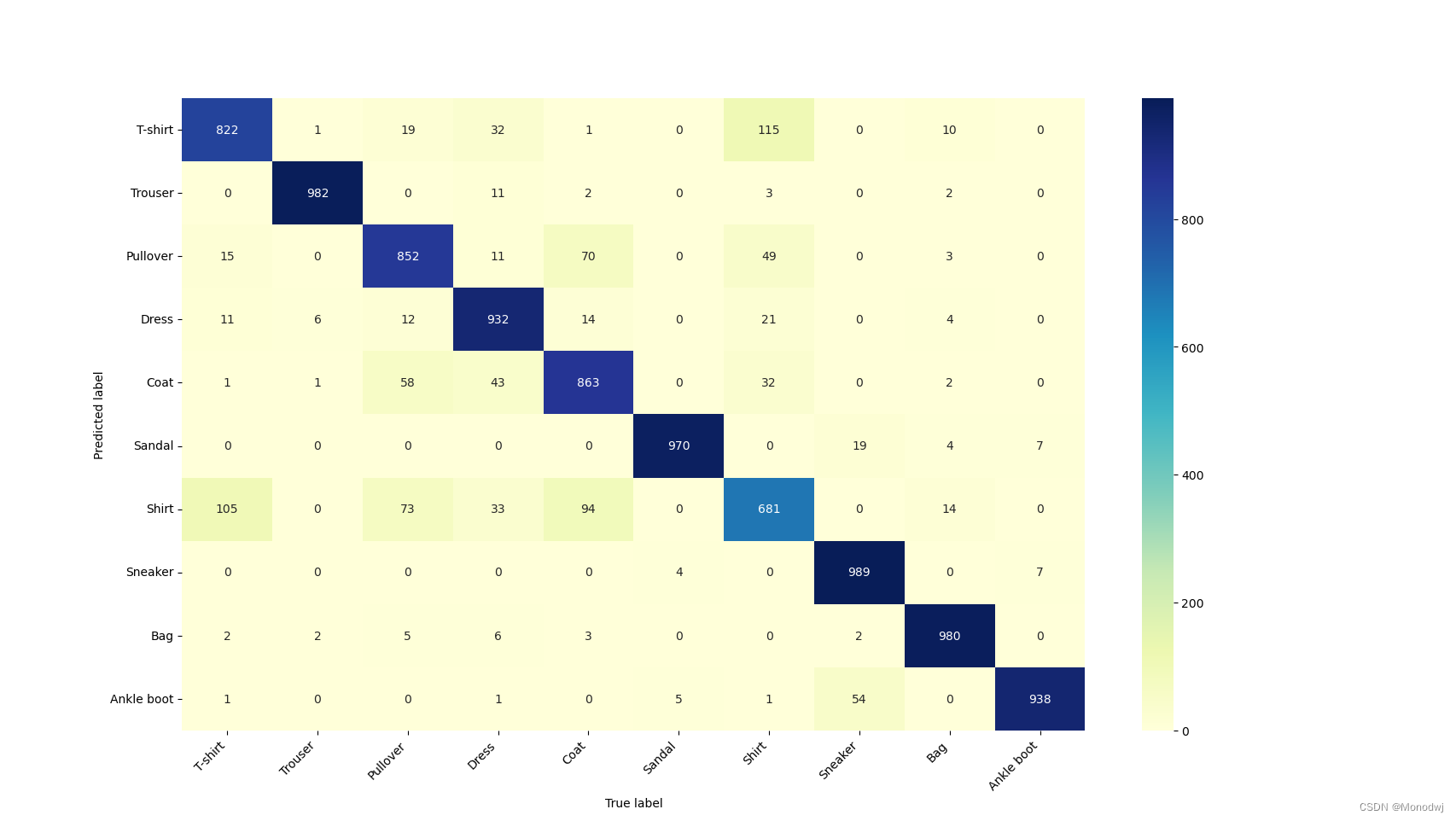
# 计算混淆矩阵可视化
con_mat = confusion_matrix(test_data_y, pre_lab)
con_mat_df = pd.DataFrame(con_mat, index=class_label, columns=class_label)
plt.figure(figsize=(12, 12))
heatmap = sns.heatmap(con_mat_df, annot=True, fmt="d", cmap="YlGnBu")
heatmap.yaxis.set_ticklabels(heatmap.yaxis.set_ticklabels(class_label), rotation=0, ha='right')
heatmap.yaxis.set_ticklabels(heatmap.xaxis.set_ticklabels(class_label), rotation=45, ha='right')
plt.xlabel("True label")
plt.ylabel("Predicted label")
plt.show()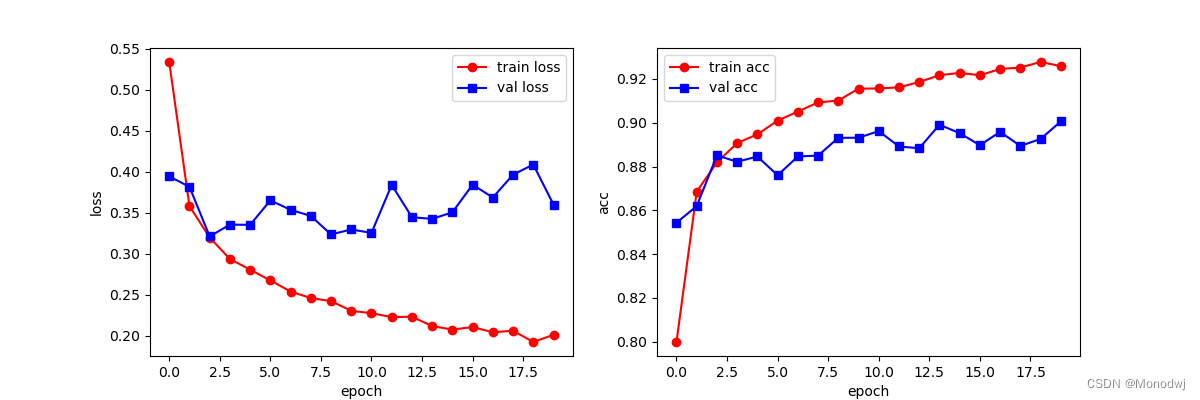
 文中参数以及结果无参考价值,仅供展示。
文中参数以及结果无参考价值,仅供展示。
文章仅作为学习用途,侵权删。















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









