







abstract
摘要音频(含kk音标)
Recent transformer-based solutions have been introduced to estimate 3D human pose from 2D keypoint(关键点) sequence by considering body joints among all frames globally to learn spatio-temporal correlation(相关性).1
最近的基于transformer2的解决方案已经被引入来从2D关键点序列估计3D人体姿态,通过考虑所有帧之间的身体关节来学习空间时间相关性。
We observe that the motions of different joints differ(v.不同) significantly(显著).
我们观察到不同关节的运动差异很大。
However, the previous methods cannot efficiently model the solid(强的,牢固的) inter-frame correspondence(关系) of each joint, leading to(导致) insufficient(不足) learning of spatial-temporal correlation(相关性).
但是,之前的方法不能有效地对每个关节的帧间对应关系建模,导致对空间时间相关性的学习不足。
We propose MixSTE (Mixed Spatio-Temporal Encoder), which has a temporal transformer block to separately(单独地) model the temporal motion of each joint and a spatial transformer block to learn inter-joint spatial correlation.
我们提出了MixSTE(混合空间时间编码器),其中一个时间transformer模块用于独立建模每个关节的时间运动,一个空间transformer模块用于学习关节间的空间相关性。
These two blocks are utilized(使用) alternately(交替地) to obtain better spatio-temporal feature encoding.
这两个模块交替使用以获得更好的空间时间特征编码。
In addition, the network output is extended(扩展) from the central frame to entire(全部的) frames of the input video, thereby(从而) improving the coherence(一致性) between the input and output sequences.
此外,网络输出从输入视频的中心帧扩展到全部帧,从而改善输入和输出序列之间的一致性。(而不是seq2frame)
Extensive(大量的) experiments(实验) are conducted on three benchmarks (i.e.Human3.6M, MPI-INF-3DHP, and HumanEva).
在三个基准测试集上进行了大量实验(即Human3.6M,MPI-INF-3DHP和HumanEva)。
The results show that our model outperforms(胜过) the state-of-the-art approach by 10.9% P-MPJPE and 7.6% MPJPE.
结果表明,与最先进的方法相比,我们的模型P-MPJPE提高了10.9%,MPJPE提高了7.6%。
The code is available at this URL.
代码可以在这个URL获得。3
这篇论文提出了MixSTE,这是一种基于transformer的新型方法,用于从单目视频中估计3D人体姿势。关键思路有:
分别建模每个关节点的时间运动,而不是把所有关节点放在一起建模。这样可以捕捉到每个关节点随时间变化的不同运动轨迹。
以seq2seq的方式交替使用空间和时间transformer模块。空间模块建模关节点之间的相关性,时间模块建模运动。交替使用可以更好地学习时空依赖性。
使用seq2seq模型而不是seq2frame。这可以在一次推理中估计全视频的3D姿势,改进序列的连贯性和效率。
在Human3.6M、MPI-INF-3DHP和HumanEva数据集上,该方法的效果超过了目前最先进的方法,将误差降低了7-10%,同时也提高了效率。
ablation study4展示了分别建模关节点、交替使用模块、seq2seq方法以及所使用的loss function的好处。
总之,MixSTE通过在seq2seq流水线中交替使用空间和时间transformer,有效地捕捉了每个关节点的时间运动模式。这改进了视频单目3D人体姿势估计的时空建模、序列连贯性、效率和精度。 ↩︎Transformer是近年来在自然语言处理和计算机视觉领域广泛应用的一种基于注意力机制的模型架构。其主要特点包括:
弃用循环结构,全部采用基于注意力机制的模块。这使得模型可以高效地并行计算,不受序列长度的限制。
多头注意力机制(Multi-Head Attention)。将输入进行多路线性映射,得到Query,Key和Value向量,然后计算Query和Key的点积相似度作为注意力权重,再用权重与Value加权求和,得到输出。多头可以学习到输入的不同表示子空间。
位置编码(Positional Encoding)。在输入向量中加入位置信息,让模型学习序列顺序。
残差连接和层规范化(Residual Connections and Layer Normalization)。简化 gradient 流动,加速训练。
Transformer通常由Encoder和Decoder组成。Encoder端使用自注意力和前馈全连接网络;Decoder端除了这两者,还使用Encoder输出的注意力。
在MixSTE方法中,空间和时间模块都采用了Transformer Encoder的结构,前者建模关节点间关系,后者建模时间关联,两者交替连接以学习时空信息。这种设计在3D人体姿势估计任务中取得了state-of-the-art的效果。
Attention is all you need
Transformer是在2017年由Google提出的 Attention is all you need 这篇论文中首次提出的。该篇论文完全抛弃了RNN等循环结构,而是完全依靠Attention Mechanism来建模序列数据。主要的创新和贡献有:
提出了Transformer网络结构,仅基于Attention Mechanism,不再使用RNN等循环结构。
提出了Scaled Dot-Product Attention,即缩放点积注意力,用来计算Query和Key的相似度。
使用Multi-Head Attention,不同的head学习输入的不同子空间表示。
使用Position Encoding来代表词元在序列中的位置信息。
提出了Transformer Encoder和Decoder的结构设计。
在WMT 2014英德和英法机器翻译任务上,Transformer取得了state-of-the-art的性能。
这篇论文开创了仅基于Attention的新网络结构在序列建模中的应用,显示了Attention Mechanism的强大能力,因此对自然语言处理和计算机视觉领域产生了深远的影响。很多后续工作都是在这个架构基础上进行改进的。 ↩︎这篇文章和MotionBERT: A Unified Perspective on Learning Human Motion Representations的模型设计很接近,MotionBERT应该就是在这篇文章基础上改进的,具体来说,MixSTE"空-时-空-时……“简单交替,而MotionBERT使用自适应融合的双流设计,即"自适应融合(空-时,时-空)-自适应融合(空-时,时-空)…”,所以就不详细解读这篇文章了。下面给出两篇论文的模型结构图,详细解读可见【笔记及概念、代码解释】MotionBERT: A Unified Perspective on Learning Human Motion Representations
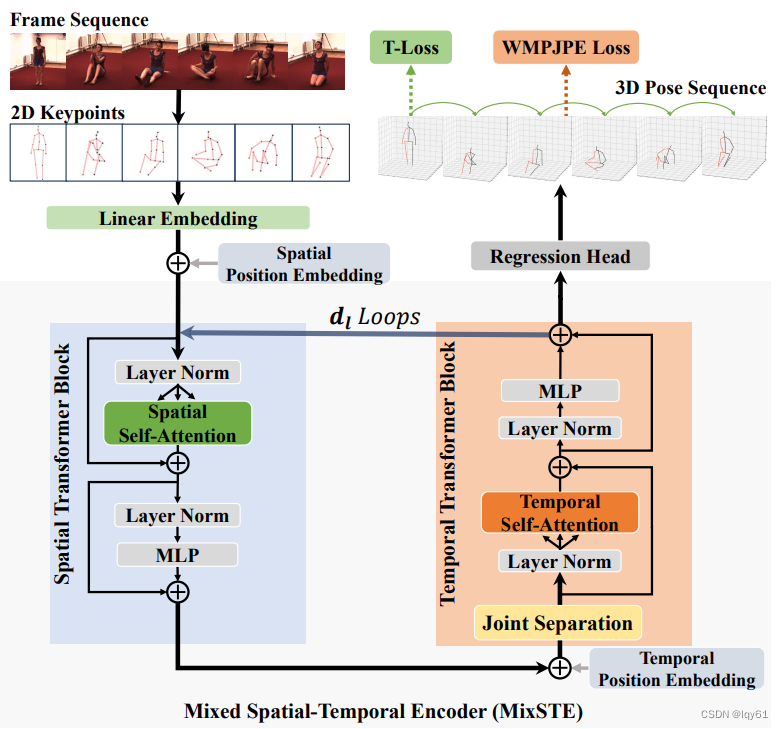
5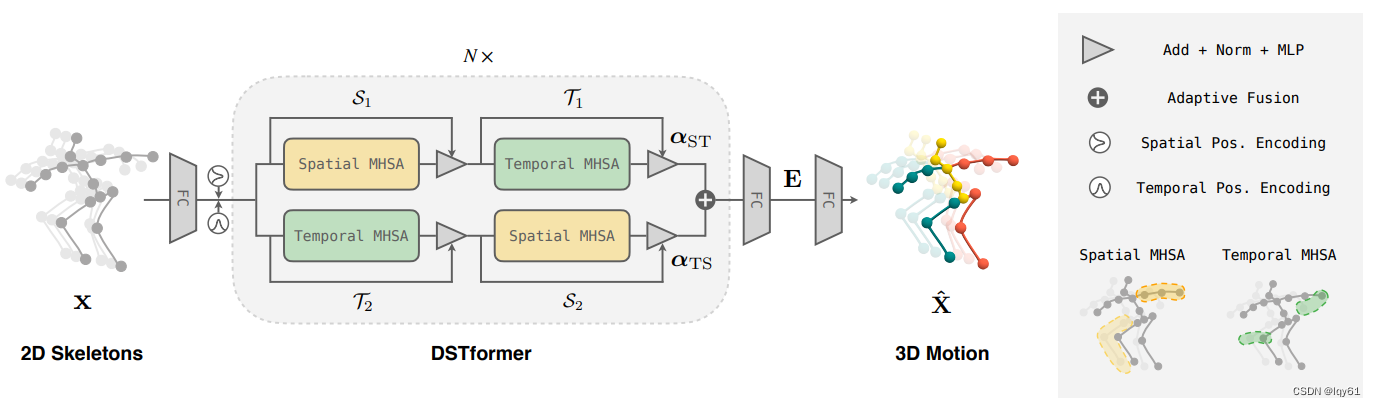 ↩︎
↩︎MixSTE论文中的ablation study(消融实验)主要评估了以下方面的影响:
每个组件的效果
从central frame输出改为sequence输出,错误率减少6.2mm
加入joint separation,进一步减少错误率4mm左右,同时降低计算量
使用设计的loss function,结果达到最优
Loss function的效果
WMPJPE loss提高关节点精度
TCLoss改进时间连贯性(降低MPJVE 1.0)
MPJVE loss进一步优化时间连贯性(MPJVE降低到2.6)
超参数设置
探究不同的模块深度、隐层大小和输入序列长度对结果的影响
综合考虑精度和参数量,选择了最优配置
总体而言,ablation study充分验证了MixSTE中的各个组件设计选择的有效性,尤其是joint separation、alternating设计、seq2seq框架和loss function的设计,都对提高姿势估计的精度和连贯性起到了重要作用。这为MixSTE的结构设计和训练提供了重要参考。 ↩︎在MixSTE论文中,使用了两种自定义的loss函数:
T-Loss是时间连贯性损失(Temporal Consistency Loss)的缩写,用于增强预测姿态序列的平滑性。它结合了两部分:(1) TCLoss:基于骨骼动力学的损失函数,惩罚预测序列表示的加速度变化。(2) MPJVE:平均关节速度误差,直接最小化预测结果和ground truth在速度上的误差。
综合这两部分,T-Loss能够有效改善姿态序列的时间平滑性。
WMPJPE是加权平均关键点位置误差(Weighted Mean Per-Joint Position Error)的缩写。
它对人体不同部位的关键点赋予不同权重,按照误差重要性平均求解。比如四肢关键点权重更大,因为它们运动更复杂。
这种设计可以使网络更关注对结果影响较大的关键点。
总之,T-Loss优化时间连贯性,WMPJPE Loss优化空间精度,两者共同作用可以获得精确平滑的3D姿态预测结果。 ↩︎















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









