







 北京大学团队提出HoT框架,通过剪枝和恢复策略降低VPT的计算量,特别是对长视频序列,同时保持或提高精度。HoT可无缝集成到现有模型,如MHFormer、MixSTE和MotionBERT,显著降低FLOPs和提升FPS。
北京大学团队提出HoT框架,通过剪枝和恢复策略降低VPT的计算量,特别是对长视频序列,同时保持或提高精度。HoT可无缝集成到现有模型,如MHFormer、MixSTE和MotionBERT,显著降低FLOPs和提升FPS。
目前,Video Pose Transformer(VPT)在基于视频的三维人体姿态估计领域取得了最领先的性能。近年来,这些 VPT 的计算量变得越来越大,这些巨大的计算量同时也限制了这个领域的进一步发展,对那些计算资源不足的研究者十分不友好。例如,训练一个 243 帧的 VPT 模型通常需要花费好几天的时间,严重拖慢了研究的进度,并成为了该领域亟待解决的一大痛点。
那么,该如何有效地提升 VPT 的效率同时几乎不损失精度呢?
来自北京大学的团队提出了一种基于沙漏 Tokenizer 的高效三维人体姿态估计框架HoT,用来解决现有视频姿态 Transformer(Video Pose Transformer,VPT)高计算需求的问题。该框架可以即插即用无缝地集成到 MHFormer,MixSTE,MotionBERT 等模型中,降低模型近 40% 的计算量而不损失精度,代码已开源。

-
标题:Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
-
论文地址:https://arxiv.org/abs/2311.12028
-
代码地址:https://github.com/NationalGAILab/HoT
研究动机
在 VPT 模型中,通常每一帧视频都被处理成一个独立的 Pose Token,通过处理长达数百帧的视频序列(通常是 243 帧乃至 351 帧)来实现卓越的性能表现,并且在 Transformer 的所有层中维持全长的序列表示。然而,由于 VPT 中自注意力机制的计算复杂度与 Token 数量(即视频帧数)的平方成正比关系,当处理具有较高时序分辨率的视频输入时,这些模型不可避免地带来了巨大的计算开销,使得它们难以被广泛部署到计算资源有限的实际应用中。此外,这种对整个序列的处理方式没有有效考虑到视频序列内部帧之间的冗余性,尤其是在视觉变化不明显的连续帧中。这种信息的重复不仅增加了不必要的计算负担,而且在很大程度上并没有对模型性能的提升做出实质性的贡献。
因此,要想实现高效的 VPT,本文认为首先需要考虑两个因素:
-
时间感受野要大:虽然直接减短输入序列的长度能够提升 VPT 的效率,但这样做会缩小模型的时间感受野,进而限制模型捕获丰富的时空信息,对性能提升构成制约。因此,在追求高效设计策略时,维持一个较大的时间感受野对于实现精确的估计是至关重要的。
-
视频冗余得去除:由于相邻帧之间动作的相似性,视频中经常包含大量的冗余信息。此外,已有研究指出,在 Transformer 架构中,随着层的加深,Token 之间的差异性越来越小。因此,可推断出在 Transformer 的深层使用全长的 Pose Token 会引入不必要的冗余计算,而这些冗余计算对于最终的估计结果的贡献有限。
基于这两方面的观察,作者提出对深层 Transformer 的 Pose Token 进行剪枝,以减少视频帧的冗余性,同时提高 VPT 的整体效率。然而,这引发了一个新的挑战:剪枝操作导致了 Token 数量的减少,这时模型不能直接估计出与原视频序列相匹配数量的三维姿态估计结果。这是因为,在传统的 VPT 模型中,每个 Token 通常对应视频中的一帧,剪枝后剩余的序列将不足以覆盖原视频的全部帧,这在估计视频中所有帧的三维人体姿态时成为一个显著的障碍。因此,为了实现高效的 VPT,还需兼顾另一个重要因素:
-
Seq2seq 的推理:一个实际的三维人体姿态估计系统应当能够通过 seq2seq 的方式进行快速推理,即一次性从输入的视频中估计出所有帧的三维人体姿态。因此,为了实现与现有 VPT 框架的无缝集成并实现快速推理,需要保证 Token 序列的完整性,即恢复出与输入视频帧数相等的全长 Token。
基于以上三点思考,作者提出了一种基于沙漏结构的高效三维人体姿态估计框架,⏳ Hourglass Tokenizer (HoT)。总的来说,该方法有两大亮点:
-
简单的 Baseline、基于 Transformer 通用且高效的框架
HoT是第一个基于 Transformer 的高效三维人体姿态估计的即插即用框架。如下图所示,传统的 VPT 采用了一个 “矩形” 的范式,即在模型的所有层中维持完整长度的 Pose Token,这带来了高昂的计算成本及特征冗余。与传统的 VPT 不同,HoT 先剪枝去除冗余的 Token,再恢复整个序列的 Token(看起来像一个 “沙漏”),使得 Transformer 的中间层中仅保留少量的 Token,从而有效地提升了模型的效率。HoT 还展现了极高的通用性,它不仅可以无缝集成到常规的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,同时也能够适配各种 Token 剪枝和恢复策略。
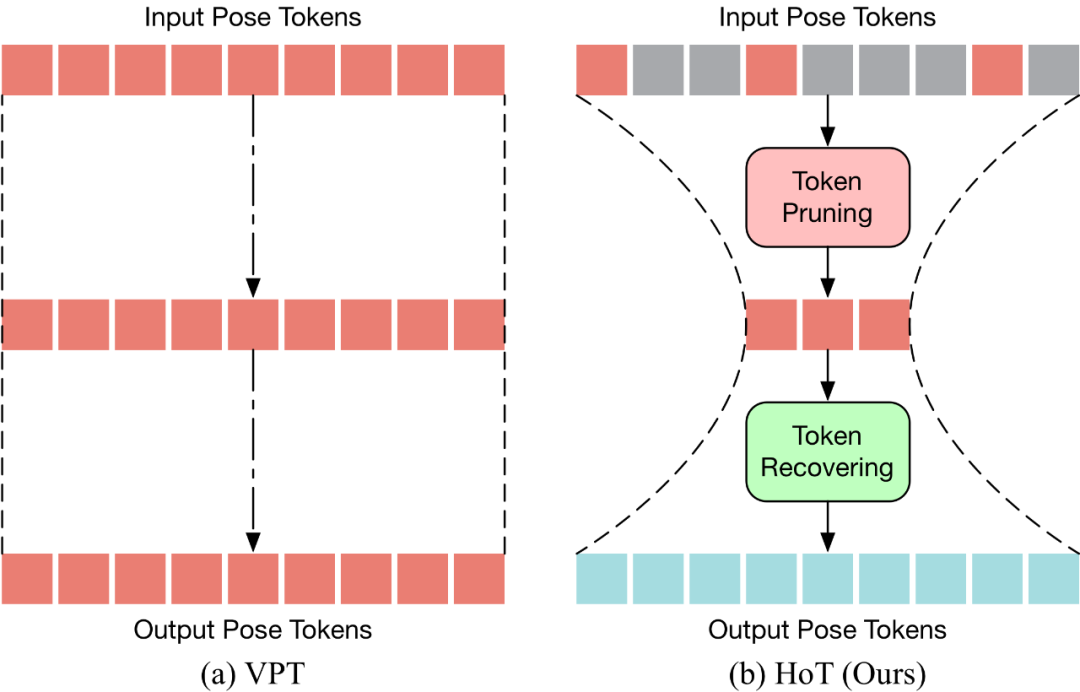
-
效率和精度兼得
HoT揭示了维持全长的姿态序列是冗余的,使用少量代表性帧的 Pose Token 就可以同时实现高效率和高性能。与传统的 VPT 模型相比,HoT 不仅大幅提升了处理效率,还实现了高度竞争性甚至更好的结果。例如,它可以在不牺牲性能的情况下,将 MotionBERT 的 FLOPs 降低近 50%;同时将 MixSTE 的 FLOPs 降低近 40%,而性能仅轻微下降 0.2%。

模型方法
提出的 HoT 整体框架如下图所示。为了更有效地执行 Token 的剪枝和恢复,本文提出了 Token 剪枝聚类(Token Pruning Cluster,TPC)和 Token 恢复注意力(Token Recovering Attention,TRA)两个模块。其中,TPC 模块动态地选择少量具有高语义多样性的代表性 Token,同时减轻视频帧的冗余。TRA 模块根据所选的 Token 来恢复详细的时空信息,从而将网络输出扩展到原始的全长时序分辨率,以进行快速推理。
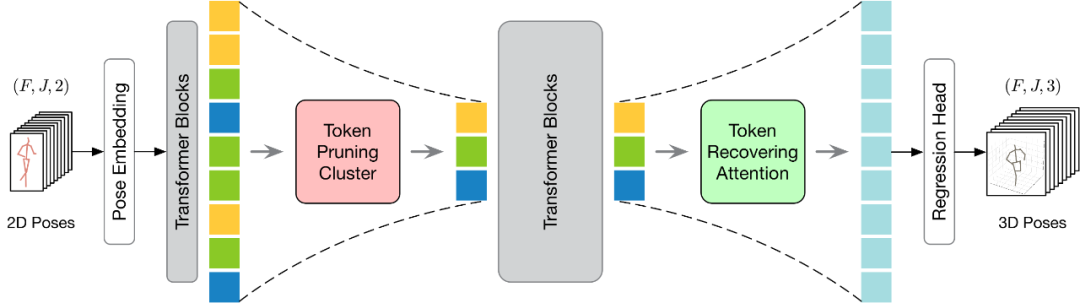
Token 剪枝聚类模块
本文认为选取出少量且带有丰富信息的 Pose Token 以进行准确的三维人体姿态估计是一个难点问题。
为了解决该问题,本文认为关键在于挑选那些具有高度语义多样性的代表性 Token,因为这样的 Token 能够在降低视频冗余的同时保留必要的信息。基于这一理念,本文提出了一种简单、有效且无需额外参数的 Token 剪枝聚类(Token Pruning Cluster,TPC)模块。该模块的核心在于鉴别并去除掉那些在语义上贡献较小的 Token,并聚焦于那些能够为最终的三维人体姿态估计提供关键信息的 Token。通过采用聚类算法,TPC 动态地选择聚类中心作为代表性 Token,借此利用聚类中心的特性来保留原始数据的丰富语义。
TPC 的结构如下图所示,它先对输入的 Pose Token 在空间维度上进行池化处理,随后利用池化后 Token 的特征相似性对输入 Token 进行聚类,并选取聚类中心作为代表性 Token。

Token 恢复注意力模块
TPC 模块有效地减少了 Pose Token 的数量,然而,剪枝操作引起的时间分辨率下降限制了 VPT 进行 seq2seq 的快速推理。因此,需要对 Token 进行恢复操作。同时,考虑到效率因素,该恢复模块应当设计得轻量级,以最小化对总体模型计算成本的影响。
为了解决上述挑战,本文设计了一个轻量级的 Token 恢复注意力(Token Recovering Attention,TRA)模块,它能够基于选定的 Token 恢复详细的时空信息。通过这种方式,由剪枝操作引起的低时间分辨率得到了有效扩展,达到了原始完整序列的时间分辨率,使得网络能够一次性估计出所有帧的三维人体姿态序列,从而实现 seq2seq 的快速推理。
TRA 模块的结构如下图所示,其利用最后一层 Transformer 中的代表性 Token 和初始化为零的可学习 Token,通过一个简单的交叉注意力机制来恢复完整的 Token 序列。

应用到现有的 VPT
在讨论如何将所提出的方法应用到现有的 VPT 之前,本文首先对现有的 VPT 架构进行了总结。如下图所示,VPT 架构主要由三个组成部分构成:一个姿态嵌入模块用于编码姿态序列的空间与时间信息,多层 Transformer 用于学习全局时空表征,以及一个回归头模块用于回归输出三维人体姿态结果。

根据输出的帧数不同,现有的 VPT 可分为两种推理流程:seq2frame 和 seq2seq。在 seq2seq 流程中,输出是输入视频的所有帧,因此需要恢复原始的全长时序分辨率。如 HoT 框架图所示的,TPC 和 TRA 两个模块都被嵌入到 VPT 中。在 seq2frame 流程中,输出是视频中心帧的三维姿态。因此,在该流程下,TRA 模块是不必要的,只需在 VPT 中集成 TPC 模块即可。其框架如下图所示。
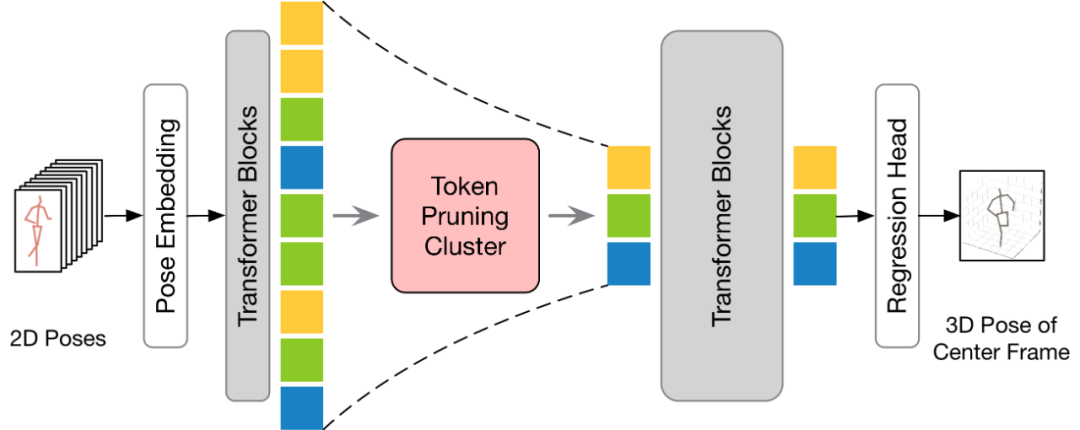
实验结果
消融实验
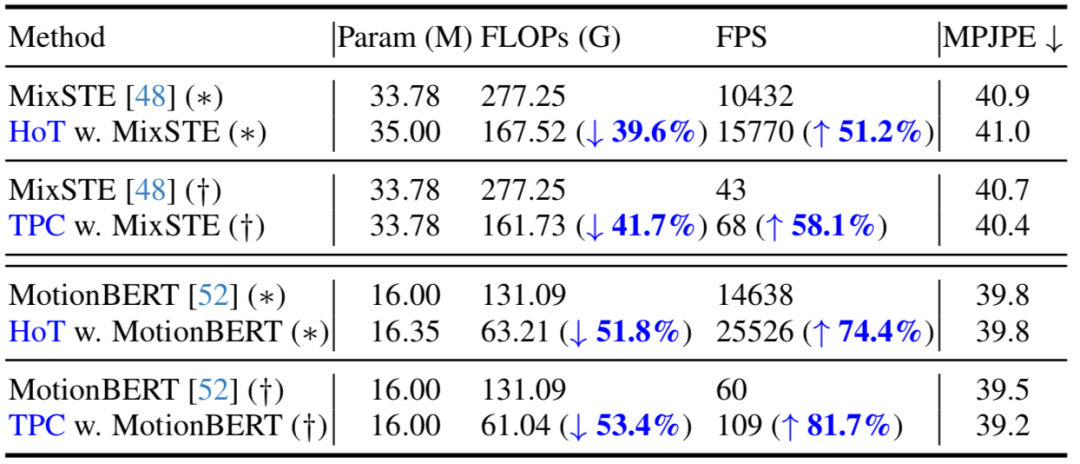
在下表,本文给出了在 seq2seq(*)和 seq2frame(†)推理流程下的对比。结果表明,通过在现有 VPT 上应用所提出的方法,本方法能够在保持模型参数量几乎不变的同时,显著减少 FLOPs,并且大幅提高了 FPS。此外,相比原始模型,所提出的方法在性能上基本持平或者能取得更好的性能。
本文还对比了不同的 Token 剪枝策略,包括注意力分数剪枝,均匀采样,以及选择前 k 个具有较大运动量 Token 的运动剪枝策略,可见所提出的 TPC 取得了最好的性能。

本文还对比了不同的 Token 恢复策略,包括最近邻插值和线性插值,可见所提出的 TRA 取得了最好的性能。

与 SOTA 方法的对比
当前,在 Human3.6M 数据集上,三维人体姿态估计的领先方法均采用了基于 Transformer 的架构。为了验证本方法的有效性,作者将其应用于三个最新的 VPT 模型:MHForme,MixSTE 和 MotionBERT,并与它们在参数量、FLOPs 和 MPJPE 上进行了比较。
如下表所示,本方法在保持原有精度的前提下,显著降低了 SOTA VPT 模型的计算量。这些结果不仅验证了本方法的有效性和高效率,还揭示了现有 VPT 模型中存在着计算冗余,并且这些冗余对最终的估计性能贡献甚小,甚至可能导致性能下降。此外,本方法可以剔除掉这些不必要的计算量,同时达到了高度竞争力甚至更优的性能。

代码运行
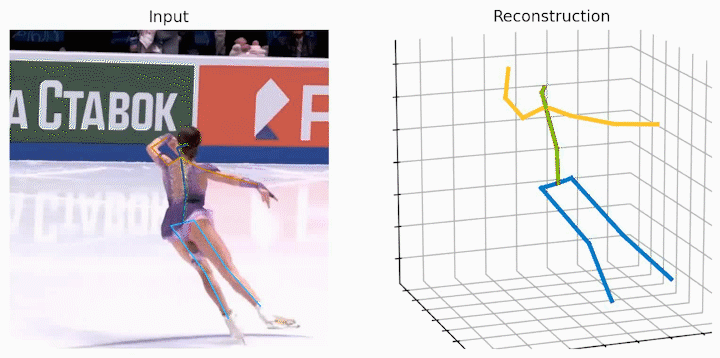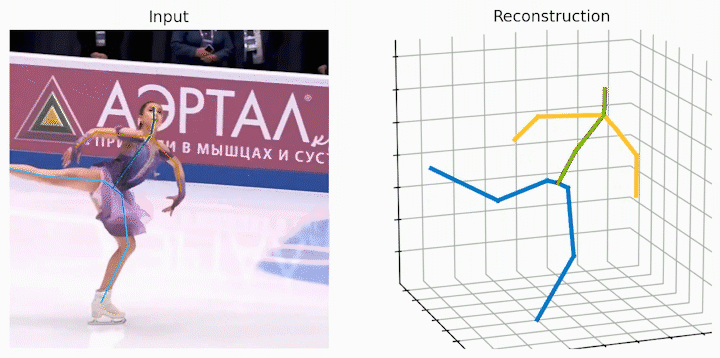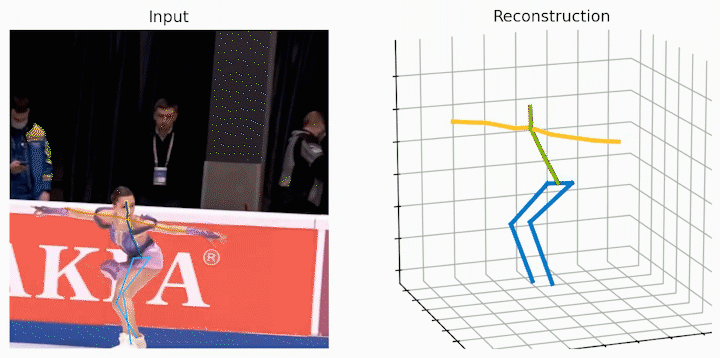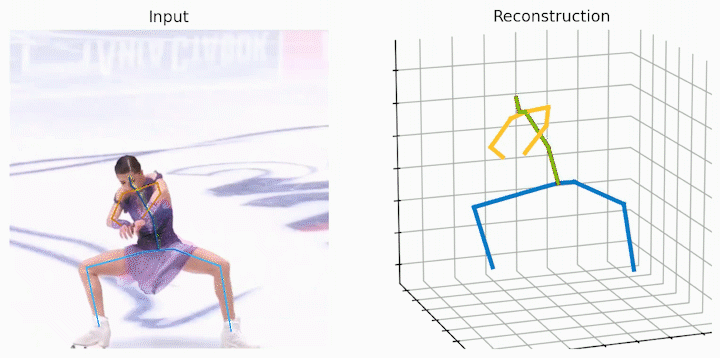
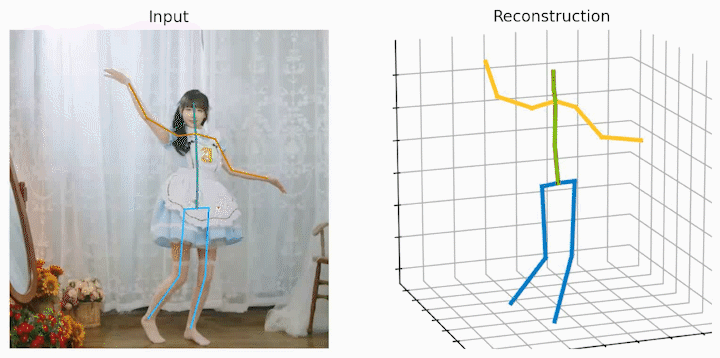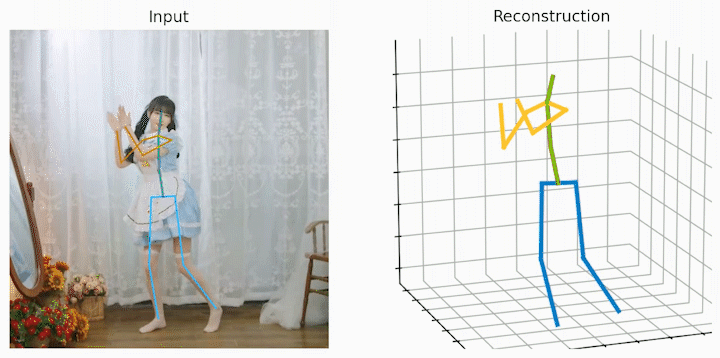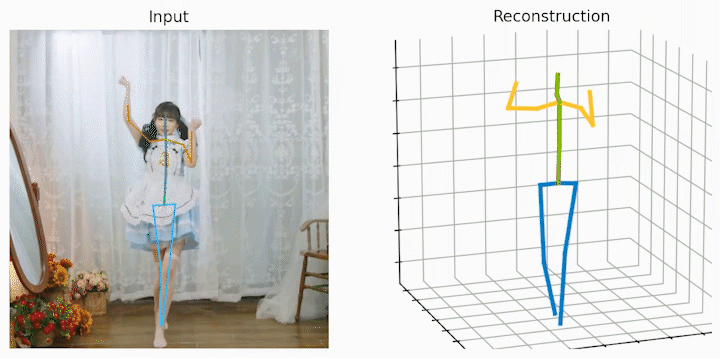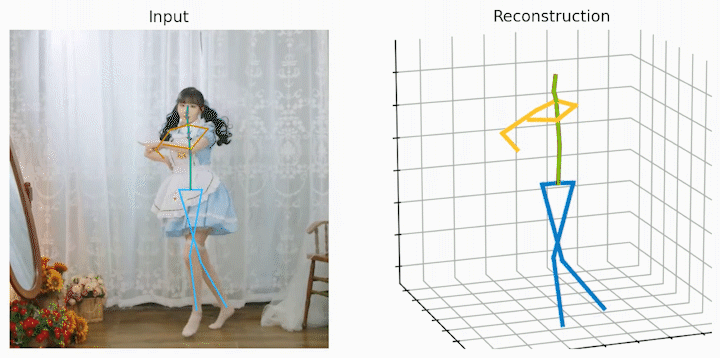
作者还给出了 demo 运行(https://github.com/NationalGAILab/HoT),集成了 YOLOv3 人体检测器、HRNet 二维姿态检测器、HoT w. MixSTE 二维到三维姿态提升器。只需下载作者提供的预训练模型,输入一小段含有人的视频,便可一行代码直接输出三维人体姿态估计的 demo。
python demo/vis.py --video sample_video.mp4运行样例视频得到的结果:
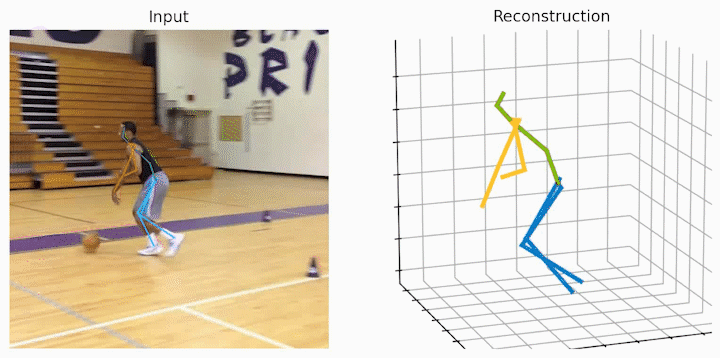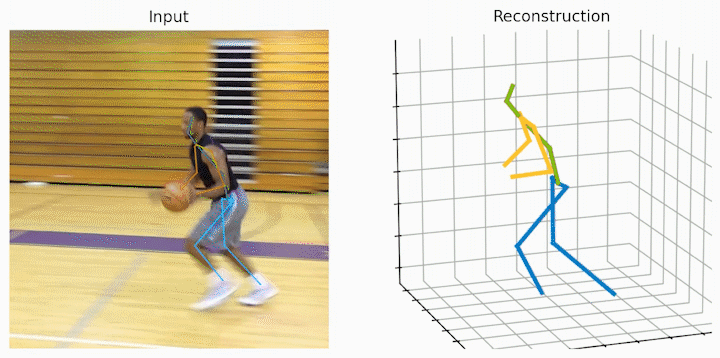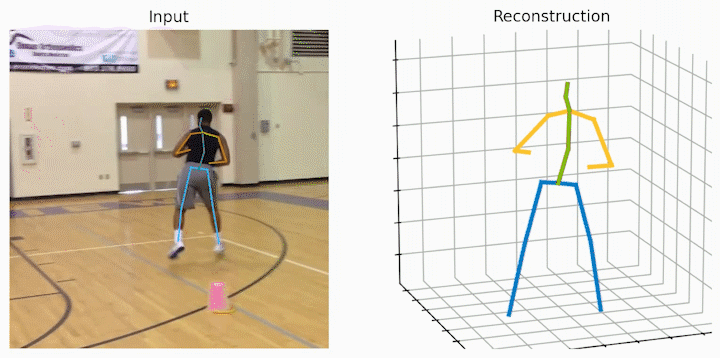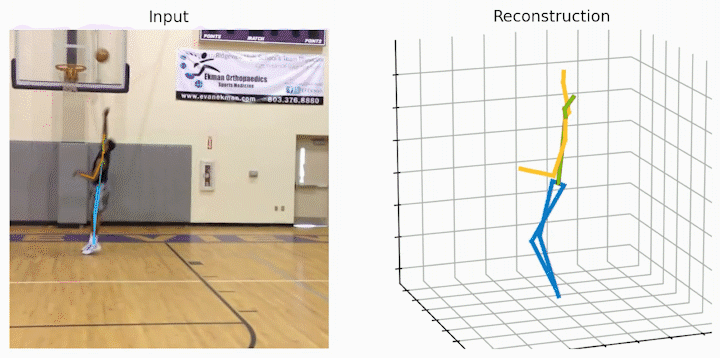
小结
本文针对现有 Video Pose Transforme(VPT)计算成本高的问题,提出了沙漏 Tokenizer(Hourglass Tokenizer,HoT),这是一种即插即用的 Token 剪枝和恢复框架,用于从视频中高效地进行基于 Transformer 的 3D 人体姿势估计。研究发现,在 VPT 中维持全长姿态序列是不必要的,使用少量代表性帧的 Pose Token 即可同时实现高精度和高效率。大量实验验证了本方法的高度兼容性和广泛适用性。它可以轻松集成至各种常见的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,并且能够有效地适应多种 Token 剪枝与恢复策略,展示出其巨大潜力。作者期望 HoT 能够推动开发更强、更快的 VPT。















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









