







修改自【论文笔记】Unified Human-Centric Model 系列之MotionBERT1
论文原文 MotionBERT: A Unified Perspective on Learning Human Motion Representations
这篇文章提出了一个统一的框架,通过学习从不同数据源(动作捕捉数据,带标签/不带标签的视频)中获取强大的人体运动表示,并将其应用到各种下游任务,如三维姿态估计,动作识别和人体网格恢复。
该框架分两个阶段:预训练和微调。在预训练阶段,使用双流时空transformer(DSTformer)作为运动编码器,通过从受损的二维骨骼中恢复三维人体运动来进行自监督的预训练任务,以学习有用的运动表示。
在下游任务的微调阶段,预训练的编码器和简单的任务特定头(例如姿态估计的线性层,动作识别的MLP)组合在一起。然后针对每个任务端到端微调整个网络,几乎无需修改。
实验结果显示,预训练模型可以很好地迁移,在所有三个任务(三维姿态估计,基于骨骼的动作识别,包括有挑战性的一射识别,以及从视频中恢复人体网格)上都取得了state-of-the-art的结果。
消融实验证明了预训练的好处,DSTformer的双流自适应设计,以及不同预训练策略的效果。
限制包括仅关注单人骨骼,缺乏对外观,环境和交互的敏感性。未来的工作可以将学习到的运动特征与其他视频表示相结合。
总之,关键思想是通过在不同数据上进行自监督预训练来学习通用的人体运动表示,然后可以轻松地将其适配到各种下游任务并提高其性能。结果证明了学习到的运动嵌入的通用性。
这篇文章希望能够针对Human-centric任务构建一种统一的预训练范式来学习通用的人体运动表征,从而帮助下游任务(例如人体姿态估计、动作识别、网格估计等)的完成。
统一预训练范式的难点在于,不同下游任务的数据集中,所包含的标签类型是不同的,如何利用这些标签差异极大的数据集构建统一的预训练任务,这将会是一个难点。同时,如果能够构建出来这样一种统一的任务,那也就相当于运用了比原来任何一种下游任务更多的数据,从而帮助性能的提升。
本文的解决方案是,在预训练阶段进行从noisy 2D observations恢复3D motion的任务,从而帮助模型理解和学习人体的潜在三维结构。
方法框架如下图所示。首先进行从2D估计3D的预训练任务,训练Motion Encoder来学习一个好的人体运动表征。然后在预训练结束后,利用该Motion Encoder,在不同的下游任务上利用特定数据集进行finetune。
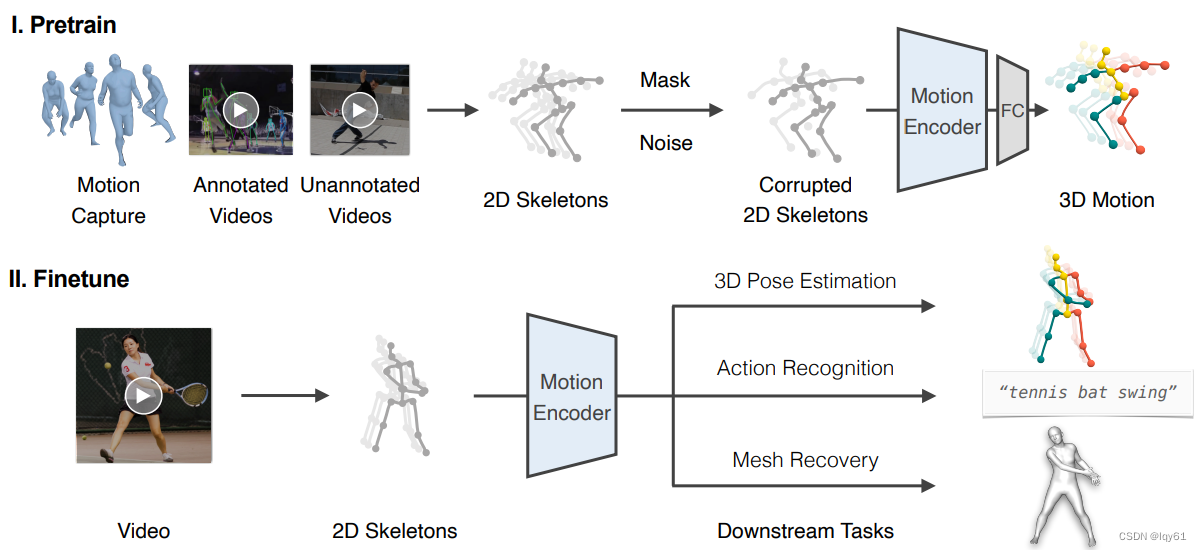
FC即全连接层(fully connected layers)
由于Motion Encoder需要能够从noisy 2D skeletons恢复出3D motion,它应当具备充分的捕捉人体依赖关系和运动特点的能力。因此,文章对于Motion Encoder的网络结构进行了设计,提出了一种Dual-stream Spatio-temporal Transformer (DSTformer) 来捕捉运动序列中长距离的时空依赖关系,网络结构如下图所示。
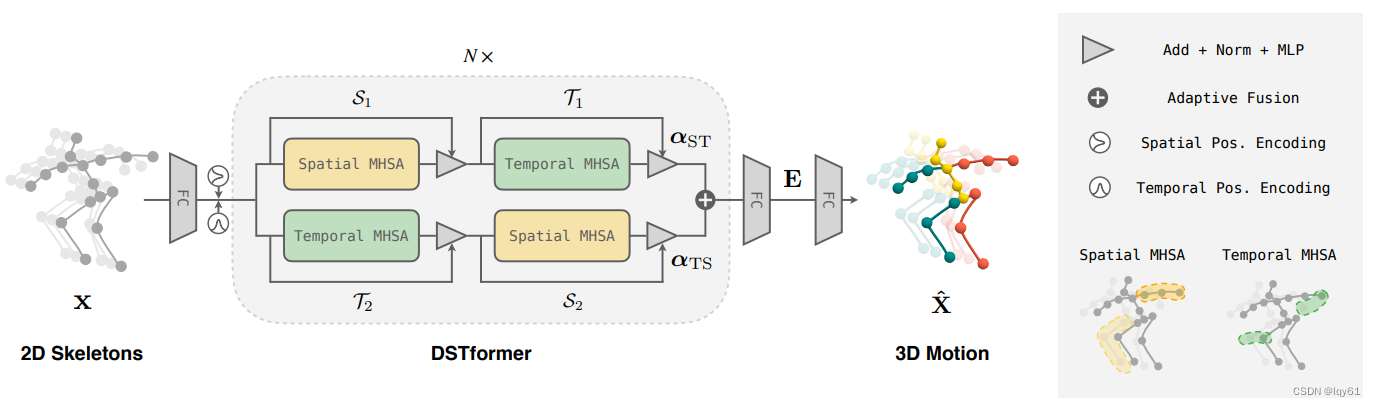
在DSTformer的forward函数中,输入x的shape为B, F, J, C,这几个变量的含义如下:
B: 代表batch size,即一次输入的样本数量。
F: 代表时间序列长度,即输入的帧数或时间步数。
J: 代表关节数量,即每个人体姿态样本包含的关键点数量。
C: 代表通道数,即每个关节的特征向量长度。
假设输入x表示32个样本(B=32), 每个样本都是人体做同一个动作的姿态序列,序列长度是50帧(F=50),每帧包含17个身体关键点(J=17), 如肩、肘、腕等,每个关键点用一个2D坐标表示它的空间坐标信息、用一个值表示置信度(推测)(C=3)。
先将输入坐标投影至特征空间中:将B与F合并,然后通过一层全连接网络将3维的特征©投影为Cf:256维。
加入时间和空间维度的位置编码:对于空间维度的位置编码,加入形状为 1 × J × Cf 的可学习参数,不同时刻是统一的值,见代码中的self.temp_embed参数;对于时间维度的位置编码,加入形状为 1 × T × Cf 的可学习参数,不同关键点是统一的值,见代码中的self.pos_embed参数。
时间和空间位置编码在Transformer模型中是一个常用的技巧,目的是为序列中不同的时间步或空间位置注入区分性信息,以帮助自注意力机制 Capture 抓取序列的顺序信息。
具体到DSTformer中的实现:
时间位置编码:通过一个可学习的参数self.temp_embed,为输入序列的不同时间步(帧)embeddings添加位置信息。即每个时间步的embeddings中,会有一个对应该时间步的固定向量。这样自注意力就可以感知不同帧的先后顺序。
空间位置编码:通过可学习的参数self.pos_embed,为输入序列不同的关节添加位置信息。即每个关节的embeddings中,会有一个对应该关节的固定向量。这样自注意力可以感知不同关节的空间信息,例如它们的连接关系等。
这两种位置编码都是学习出来的,而不是使用正弦函数等预定义的位置编码。并且它们对所有样本都是共享的,即所有batch对应的时间步或关节使用相同的编码。
通过在embeddings中加入这种位置信息,自注意力机制可以更容易地区分序列中的不同时间步和不同关节,从而建模它们的顺序和结构信息。
在训练过程中,这些位置编码会逐步学习到对模型有用的位置表示,如时间顺序或关节结构等方面的知识。它们和embeddings一起作为Transformer的输入。
综上,这是Transformer类模型区分序列中不同位置的一个简单有效的机制,对于像人体姿态这样的结构化序列建模非常重要。DSTformer通过这种位置编码的设计增强了其时空建模能力。
代码:
self.temp_embed = nn.Parameter(torch.zeros(1, maxlen, 1, dim_feat))
self.pos_embed = nn.Parameter(torch.zeros(1, num_joints, dim_feat))
trunc_normal_(self.temp_embed, std=.02)
trunc_normal_(self.pos_embed, std=.02)
# x [ BF , J , Cf ]
x = x + self.pos_embed
_, J, C = x.shape
x = x.reshape(-1, F, J, C) + self.temp_embed[:,:F,:,:]
DSTformer中时间和空间位置编码直接加在输入特征上,而不是作为一个独立的维度,这种实现方式为什么还能起到区分不同位置的作用呢?
主要有以下几点原因:
在Transformer中,位置编码不一定需要作为一个独立的维度输入到自注意力中,把它加在输入embeddings上也是可以的。
虽然直接相加,但位置编码中的信息可以看作是对原有输入特征的补充和增强,为序列表示引入外部的位置先验信息。
自注意力机制本身是能对序列建模并关注到顺序信息的,位置编码的作用是辅助它更易区分不同位置,即使编码信息混合在一起,也能起到这个效果。
和输入特征简单相加虽然不是完全独立,但计算上更加高效,也较容易实现。
类似的设计也出现在其他Transformer模型中,例如BERT中就直接将位置编码加在输入token embeddings上。
而且,相对于原有特征(3维),投影到Cf(256维)已经可以算是额外附加维度了,所以自然能直接相加。
随机地丢弃一些关键点的数据:通过dropout实现,见代码中的self.pos_drop网络层。
进行完这些步骤之后,可以将其送入N层级联的DSTformer网络中,接下来将对一层DSTformer的结构进行介绍。
DSTformer中包含两种结构的子网络:Spatial MHSA和Temporal MHSA。它们也很好理解,分别是在空间和时间维度进行attention计算,而在另一个维度的计算是并行的,可以通过“DSTformer网络结构图”的右下角子图进行理解。文章认为,先做Spatial MHSA再做Temporal MHSA提取的特征,和先做Temporal MHSA再做Spatial MHSA提取的特征是不同的。
文章认为空间自注意力(Spatial MHSA)和时序自注意力(Temporal MHSA)的先后顺序会影响提取的特征是有以下原因:
Spatial MHSA主要建模一个时刻内不同关节之间的关系,而Temporal MHSA建模一个关节在时间上的变化。
如果先进行Spatial MHSA,则后续的Temporal MHSA能基于一个时刻内关节关系比较丰富的特征进行时间建模。
反之,如果先进行Temporal MHSA,则后续的Spatial MHSA需要基于一个关节在时间上比较丰富的特征来建模空间关系。
虽然理论上都能学到空间和时间信息,但先后顺序的不同会导致两个自注意力模块的学习侧重点不同。
具体来说,Space-Time顺序更专注于空间关系,而Time-Space顺序更专注于时间关系。
文章通过实验也验证了这两种顺序会得到略有差异的结果,说明顺序的改变确实影响到特征。
为获取空间和时间信息的综合表达,文章提出了双流结构来同时学习两个顺序的表示,兼顾了各个顺序代表的时空信息。
因此文章中设计的DSTformer块中有两个分支,两个分支中Spatial和Temporal MHSA的顺序是相反的,再提取完两种特征后再进行合并。
最简单的合并方式就是计算两种特征的平均值,然而这篇工作希望模型能够根据输入的特性动态地调整两种特征的比例,因此引入了 αST和αTS 参数。首先将两个分支的输出(记为 y1,y2 )在特征维度进行concat,然后通过一个投影矩阵将其投影为维度为2的向量并计算softmax结果,记为 αST和αTS ,二者的和为1,就可以用来调整 y1,y2 的比重。这样得到的结果作为一个DSTformer block的最终输出。
从代码中看,不同深度的block以及αST和αTS投影层都是不一样的(结构一样,具体参数不同)。
经过几层级联block之后,再经过一层全连接和Tanh,得到的就是motion embedding。如果需要进行3D motion的恢复,则再加入head(一层全连接层)即可。
DSTformer中使用多层级联的Block结构主要有以下几点考虑:
增加网络层数可以让模型学习到更抽象和高级的特征表示。
级联结构也称为深层网络,通过多层非线性转换,来提取数据中的复杂模式。
每增加一层Block,都会引入一个自注意力和一个全连接层,增强了模型的表达能力。
网络的层数控制了模型学习表示的复杂程度,需要通过实验来选择最佳的值。
更多层数会增加模型参数,并不一定带来准确率的提升,需要在复杂度和效果之间权衡。
DSTformer的Block中引入了残差连接和规范化2,使得很深的网络也能顺利训练。
深层网络在许多任务中都展现出了提取高质量特征的能力。
对于DSTformer来说,需要多层来学习人体运动的复杂时空Patterns。
实验结果表明,适当增加DSTformer的层数(如5层)可以带来性能的提升。
综上,结合残差连接的多层Block是获取复杂特征表示的常用且有效方式。DSTformer通过这种典型设计提取了高质量的人体运动表征。但层数仍需要根据实际情况调整以防过拟合。
在统一的预训练任务中,我们能够利用的有两种类型的数据。
第一种是大量存在的3D mocap data:将3D动捕数据随机地投影得到一些2D骨架数据,然后在2D骨架数据中随机mask掉一些关键点并加入噪声,从而模拟真实数据中的遮挡、检测失败和误差现象。对于这种数据,可以加入位置误差损失和速度误差损失用于预训练。
第二种是一些没有3D GT的2D数据,比如in-the-wild的人体姿态数据集。在这种情况下,可以通过手动标注或者2D estimation的方式获取一些2D骨架数据,然后通过2D重投影误差进行训练。
从这里我们也能够看出,之所以文章会采取2D-3D lifting作为预训练任务,一大原因就是对于各种人体相关的数据集,都能够通过手动标注或2D估计来获得2D骨架数据,保证了对于各种heterogenous数据集的利用率。
对于不同的下游任务,本文采取了minimalist design原则,即设计尽量简单的head。
3D姿态估计任务:只需要reuse预训练模型即可。
基于骨架的动作识别任务:global average pooling+MLP with one hidden layer.
人体网格恢复:利用每一帧的motion embedding估计pose参数,而由于shape参数在一段视频中具有一致性,因此在temporal维度对所有motion embedding计算平均,然后回归出shape参数。
接下来更具体详细地解释Block
Block(ST)的代码如下:
if self.st_mode=='stage_st':
x = x + self.drop_path(self.attn_s(self.norm1_s(x), seqlen))
x = x + self.drop_path(self.mlp_s(self.norm2_s(x)))
x = x + self.drop_path(self.attn_t(self.norm1_t(x), seqlen))
x = x + self.drop_path(self.mlp_t(self.norm2_t(x)))
return x
stage_ts同st类似,stage_para暂时不说。
drop_path和norm1_s3不用说,mlp之前也有说到2
详细介绍self.attn_s、self.attn_t:
主要介绍spatial,temporal和spatial差不多,只是要多几个reshape(可以学习)。
# x的shape是B*F(记作B), J(记作N), C(记作C)
# self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# self.qkv(x)的shape是B*F, J, C*3
# 线性层nn.Linear将输入特征映射到一个3倍大的空间,用于生成query,key和value
# reshape将原特征分为self.num_heads个头(多头注意力),每个头学习到的都是整体特征的一部分信息,多头结合可以增强特征。
q, k, v = qkv[0], qkv[1], qkv[2]
# q、k、v的shape为B(即B*F),num_heads,N(即J),C // self.num_heads
x = self.forward_spatial(q, k, v)
def forward_spatial(self, q, k, v):
B, _, N, C = q.shape
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = attn @ v
x = x.transpose(1,2).reshape(B, N, C*self.num_heads)
return x
forward_spatial实现了空间自注意力,其步骤如下:
输入q,k,v矩阵,其shape为[B(即B*F), 头数4(num_heads), 关节数N(J), 特征维度C(C // self.num_heads)]
计算attn矩阵,公式为:attn = (q @ k.transpose(-2, -1)) * scale
其中,@表示矩阵乘法,transpose对k进行转置,矩阵点积计算相关性5
scale是缩放因子,一般为vectors长度的倒数根号,用以平衡值
对attn用softmax归一化,得到注意力分布
DropoutRegularization可有可无
attn与v矩阵相乘,得到输出表示
调整shape为[B,关节数N,所有头的特征维度C]
返回输出x
所以,空间自注意力主要通过q,k矩阵点积计算同一时刻不同关节之间的相关性,作为注意力分布,再与v合成输出。它自动学习到了不同关节之间的空间依赖关系,例如手肘与手腕的运动关联。这种机制是Transformer类模型中典型的空间建模方式。
(暂完)
第一次弄这种笔记,不太懂,如有侵权,请联系我。原博主的文章特别好,欢迎去关注、阅读,我也是看到他的文章比我总结的要好才在他的基础上进行解释的。 ↩︎
残差连接(Residual Connection)和规范化(Normalization)都是深度学习模型中常用的技术,其作用如下:
残差连接:
将层的输入直接与输出相加,即 x + F(x)
避免信息在通过层的传播过程中逐步衰减或失真
缓解深度网络的梯度消失问题,使训练容易
引入恒等映射,保证至少不劣化
卷积网络中的微调或范畴,如ResNet
规范化:
对层的输入或输出特征进行规范化
常见方法有Batch Normalization (BN)、Layer Normalization (LN)
减小内部协变量偏移,加速训练
控制特征分布,防止流量饱和
使模型更稳定,对参数初始化和变化更鲁棒
DSTformer中Block模块除了引入残差连接和LayerNorm,与标准Transformer不同的是还额外加入了一个MLP(多层感知机)。引入MLP主要有以下几点考虑:
MHSA进行了特征的交互建模,而MLP可以进行非线性转换,使得特征更具判别性。
残差连接+规范化保证信息传播,MLP引入非线性提升表达能力。
MLP通常包含两层全连接网络以及非线性激活,增加了模型的参数空间。
自注意力后的MLP可以看作是一个特征变换和映射的过程。
MHSA focus在特征关系上,MLP更focus在特征空间转换,两者起到互补作用。
MLP增加了模型优化的参数空间,也为调整representations提供了更多灵活性。
对DSTformer而言,MLP有助于获得更抽象和高级的人体运动特征。
实验证明,引入MLP明显提升了模型的精度,证明其效果。 ↩︎ ↩︎DSTformer中Block模块里的这4个LayerNorm层是一样的,都对输入进行了规范化(normalization)。
虽然它们操作和参数相同,但作者给它们起不同的变量名可能主要出于以下几点考虑:
从代码阅读的角度,可以很清晰地表明norm作用在Attention之前和MLP之后,起到划分模块的作用。
尽管数值上一样,但概念上它们作用在不同模块的不同状态上,起到语义上的区分。
这样的写法更符合模块化和封装的思想,每个组件只关心输入和输出,不需要关心内部实现。
从计算图构建的角度,每个Component都构建一个计算过程,而不是共享计算。
保持独立的Component也为未来的修改、替换、拓展提供方便,提高代码的可维护性。
一些工具和框架要求构建独立的计算步骤,这样的写法也符合其要求。
所以虽然结果一样,但具体组件名称的独立定义是有其考虑的,主要出于编码规范、计算图构建和未来维护等方面的综合考量。这在构建模块化的深度网络时是一个常见且推荐的编程实践。 ↩︎自注意力机制中的多头(multi-head)设计主要有以下几点考虑:
将特征映射到不同的子空间(通过多组矩阵映射),实现对输入的多视角建模。
每个头学习到的都是整体特征的一部分信息,多头结合可以增强特征。
不同的头可关注不同的依赖关系,如空间、语义、位置等不同方面。
多头注意力结果拼接后再做线性变换,进行信息整合,得到增强的特征。
增加了模型学习表示的方式,使表达能力更强,并可平衡需学习的参数。
多头在Transformer类模型中已被证明很有效,能明显提升性能。
对DSTformer来说,可以让不同头学习人体结构的不同方面依赖。
空间或时序自注意力都使用了类似的多头机制。
所以多头设计让模型可以关注不同的特征依赖,输出都融合到一起,增强表达力。它是自注意力模块的重要组成部分和创新点。 ↩︎点积的相关性在以前的文章中说过,主要是与特征向量的夹角有关。 ↩︎















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









