






前言
在《》期中我们介绍了有关KNN算法的思想和理论知识,但理论终究需要实战进行检验。本节我们就从实战的角度,继续介绍KNN算法的应用。
语法介绍
KNN算法是一个非常优秀的数据挖掘模型,它既可以解决离散型因变量的分类问题,也可以处理连续型因变量的预测问题,而且该算法对数据的分布特征没有任何的要求。在本次的实战项目中,将利用该算法对学生知识的掌握程度作分类判别,并对高炉发电量作预测分析。
Python中的sklearn模块提供了有关KNN算法实现分类和预测的功能,该功能存在于子模块neighbors中。其中,KNeighborsClassifier“类”可以解决分类问题,而KNeighborsRegressor“类”则可以解决预测问题。首先,针对这两个“类”的语法和参数含义作详细描述:
neighbors.KNeighborsClassifier(n_neighbors=5,weights=’uniform’, algorithm=’auto’, leaf_size=30,p=2,metric=’minkowski’, metric_params=None, n_jobs=1)
neighbors.KNeighborsRegressor(n_neighbors=5,weights=’uniform’, algorithm=’auto’, leaf_size=30,p=2,metric=’minkowski’, metric_params=None, n_jobs=1)
n_neighbors:用于指定近邻样本个数K,默认为5;
weights:用于指定近邻样本的投票权重,默认为’uniform’,表示所有近邻样本的投票权重一样;如果为’distance’,则表示投票权重与距离成反比,即近邻样本与未知类别的样本点距离越远,权重越小,反之,权值越大;
algorithm:用于指定近邻样本的搜寻算法,如果为’ball_tree’,则表示使用球树搜寻法寻找近邻样本;如果为’kd_tree’,则表示使用KD树搜寻法寻找近邻样本;如果为’brute’,则表示使用暴力搜寻法寻找近邻样本。默认为’auto’,表示KNN算法会根据数据特征自动选择最佳的搜寻算法;
leaf_size:用于指定球树或KD树叶子节点所包含的最小样本量,它用于控制树的生长条件,会影响树的查询速度,默认为30;
metric:用于指定距离的度量指标,默认为闵可夫斯基距离;
p:当参数metric为闵可夫斯基距离时,p=1,表示计算点之间的曼哈顿距离;p=2,表示计算点之间的欧氏距离;该参数的默认值为2;
metric_params:为metric参数所对应的距离指标添加关键字参数;
n_jobs:用于设置KNN算法并行计算所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能;
对比两个“类”的语法和参数,可以发现两者几乎是完全一样的,在本人看来,有两个比较重要的参数,它们是n_neighbors和weights,在实际的项目应用中需要对比各种可能的值,并从中挑出出理想的参数值。为了将KNN算法的理论知识应用到实战中,接下来将利用这两个“类”作分类和预测分析。
KNN模型的分类功能
对于分类问题的解决,将使用Knowledge数据集作为演示,该数据集来自于UCI主页(http://archive.ics.uci.edu/ml/datasets.html)。数据集一共包含403个观测和6个变量,首先预览一下该数据集的前几行信息:
# 导入第三方包import pandas as pd# 导入数据Knowledge= pd.read_excel(r’C:\Users\Administrator\Desktop\Knowledge.xlsx’)# 返回前5行数据Knowledge.head()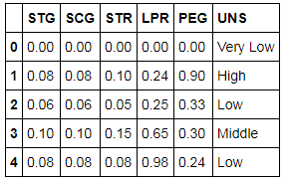
如上表所示,行代表每一个被观察的学生;前5列分别为学生在目标学科上的学习时长(STG)、重复次数(SCG)、相关科目的学习时长(STR)、相关科目的考试成绩(LPR)和目标科目的考试成绩(PEG),这5个指标都已做了归一化的处理;最后一列是学生对知识掌握程度的高低分类(UNS),一共含有四种不同的值,分别为Very Low、Low、Middle和High。 接下来,利用该数据集构建KNN算法的分类模型。
为了验证模型的拟合效果,需要预先将数据集拆分为训练集和测试集,训练集用来构造KNN模型,测试集用来评估模型的拟合效果:
# 导入第三方模块from sklearn import model_selection
# 拆分训练集和测试集
X_train, X_test, y_train, y_test
=model_selection.train_test_split(Knowledge[predictors], Knowledge.UNS,
test_size = 0.25, random_state = 1234)当数据一切就绪以后,按理应该构造KNN的分类模型,但是前提得指定一个合理的近邻个数k,因为模型非常容易受到该值的影响。虽然KNeighborsClassifier“类”提供了默认的近邻个数5,但并不代表该值就是合理的,所以需要利用多重交叉验证的方法,获取符合数据的理想k值:
# 导入第三方模块import numpy as npfrom sklearn import neighborsimport matplotlib.pyplot as plt# 设置待测试的不同k值K = np.arange(1,np.ceil(np.log2(Knowledge.shape[0])))# 构建空的列表,用于存储平均准确率accuracy = []for k in K: # 使用10重交叉验证的方法,比对每一个k值下KNN模型的预测准确率
cv_result =
model_selection.cross_val_score(
neighbors.KNeighborsClassifier(n_neighbors = k, weights = 'distance'),
X_train, y_train, cv = 10, scoring='accuracy')
accuracy.append(cv_result.mean())# 从k个平均准确率中挑选出最大值所对应的下标 arg_max = np.array(accuracy).argmax()# 中文和负号的正常显示plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制不同K值与平均预测准确率之间的折线图plt.plot(K, accuracy)# 添加点图plt.scatter(K, accuracy)# 添加文字说明plt.text(K[arg_max], accuracy[arg_max], '最佳k值为%s' %int(K[arg_max]))# 显示图形plt.show()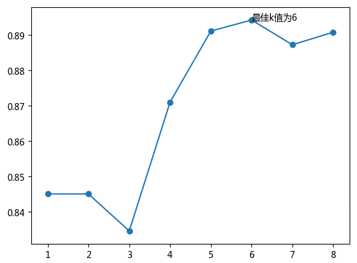
如上图所示,经过10重交叉验证的运算,确定最佳的近邻个数为6个。接下来,利用这个最佳的k值,对训练数据集进行建模,并将建好的模型应用在测试数据集上:
# 重新构建模型,并将最佳的近邻个数设置为6knn_class = neighbors.KNeighborsClassifier(n_neighbors = 6, weights = 'distance')# 模型拟合knn_class.fit(X_train, y_train)# 模型在测试数据集上的预测predict = knn_class.predict(X_test)# 构建混淆矩阵cm = pd.crosstab(predict,y_test)
cm
如上表所示,返回了模型在测试集上的混淆矩阵 ,单从主对角线来看,绝大多数的样本都被正确分类。进而基于混淆矩阵,计算出模型在测试数据集上的预测准确率
# 导入第三方模块from sklearn import metrics# 模型整体的预测准确率metrics.scorer.accuracy_score(y_test, predict)
如上结果所示,模型的预测准确率为91.09%。准确率的计算公式为:混淆矩阵中主对角线数字之和与所有数字之和的商。遗憾的是,该指标只能衡量模型的整体预测效果,却无法对比每个类别的预测精度、覆盖率等信息。如需计算各类别的预测效果,可以使用下方代码:
# 分类模型的评估报告print(metrics.classification_report(y_test, predict))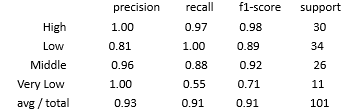
如上结果所示,前四行代表因变量y中的各个类别值,最后一行为各指标的综合水平;第一列precision表示模型的预测精度,计算公式为:预测正确的类别个数/该类别预测的所有个数;第二列recall表示模型的预测覆盖率,计算公式为:预测正确的类别个数/该类别实际的所有个数;第三列f1-score是对precision和recall的加权结果;第四列为类别实际的样本个数。
KNN模型的预测
对于预测问题的实战,将使用CCPP数据集作为演示,该数据集涉及了高炉煤气联合循环发电的几个重要指标,其同样来自于UCI网站。首先通过如下代码,获知各变量的含义以及数据集的规模:
# 读入数据ccpp = pd.read_excel(r'C:\Users\Administrator\Desktop\CCPP.xlsx')
ccpp.head()
ccpp.shape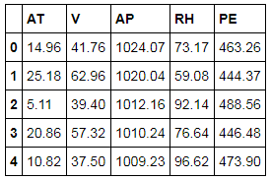
如上表所示,前4个变量为自变量,AT表示高炉的温度、V表示炉内的压力、AP表示高炉的相对湿度、RH表示高炉的排气量;最后一列为连续型的因变量,表示高炉的发电量。该数据集一共包含9,568条观测,由于4个自变量的量纲不一致,所以在使用KNN模型进行预测之前,需要对其作标准化处理:
# 导入第三方包from sklearn.preprocessing import minmax_scale# 对所有自变量数据作标准化处理predictors = ccpp.columns[:-1]
X = minmax_scale(ccpp[predictors])同理,也需要将数据集拆分为两部分,分别用户模型的构建和模型的测试。使用训练集构建KNN模型之前,必须指定一个合理的近邻个数k值。这里仍然使用10重交叉验证的方法,所不同的是,在验证过程中,模型好坏的衡量指标不再是准确率,而是MSE(均方误差):
# 设置待测试的不同k值K = np.arange(1,np.ceil(np.log2(ccpp.shape[0])))# 构建空的列表,用于存储平均MSEmse = []for k in K: # 使用10重交叉验证的方法,比对每一个k值下KNN模型的计算MSE
cv_result = model_selection.cross_val_score(
neighbors.KNeighborsRegressor(n_neighbors = k, weights = 'distance'),
X_train, y_train, cv = 10, scoring='neg_mean_squared_error')
mse.append((-1*cv_result).mean())# 从k个平均MSE中挑选出最小值所对应的下标 arg_min = np.array(mse).argmin()# 绘制不同K值与平均MSE之间的折线图plt.plot(K, mse)# 添加点图plt.scatter(K, mse)# 添加文字说明plt.text(K[arg_min], mse[arg_min] + 0.5, '最佳k值为%s' %int(K[arg_min]))# 显示图形plt.show()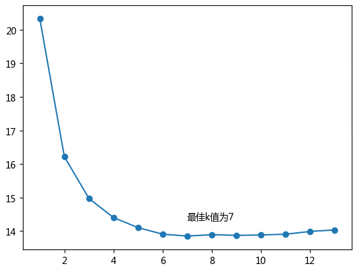
如上图所示,经过10重交叉验证,得到最佳的近邻个数为7。接下来,利用这个最佳的k值,对训练数据集进行建模,并将建好的模型应用在测试数据集上:
# 重新构建模型,并将最佳的近邻个数设置为7knn_reg = neighbors.KNeighborsRegressor(n_neighbors = 7, weights = 'distance')# 模型拟合knn_reg.fit(X_train, y_train)# 模型在测试集上的预测predict = knn_reg.predict(X_test)# 计算MSE值metrics.mean_squared_error(y_test, predict)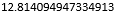
如上结果所示,对于连续因变量的预测问题来说,通常使用MSE或RMSE(均方误差根)评估模型好坏,如果该值越小,说明预测值与真实值越接近。单看上面计算所得的12.81可能没有什么感觉,这里可以对比测试集中的真实数据和预测数据,查看两者之间的差异,不妨取出各自的前10行用于比较:
# 对比真实值和实际值pd.DataFrame({'Real':y_test,'Predict':predict}, columns=['Real','Predict']).head(10)
如上表所示,通过对比发现,KNN模型在测试集上的预测值与实际值非常的接近,可以认为模型的拟合效果非常理想。
最后,读者也不妨试试别的预测算法,并对比KNN算法效果,你会发现KNN算法真的是非常理想的机器学习工具。关于其他算法的详细介绍,读者可以查看我的新书《从零开始学Python数据分析与挖掘》。
结语
OK,关于KNN算法的分类与预测实战我们就分享到这里,如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。
















 2868
2868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











