







前言
假装有
一、Python调参
(1)建模前的准备
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
(2)KNN的重要参数
首先,复习一下参数有啥(传送门),总结一下重要的:
n_neighbors(K值,默认邻居的数目,之前说过记得是奇数)、weights(是否考虑权重,uniform,奇数;distance,考虑)、p值(距离类型,只有当 weights = ‘distance’ 时,p才有意义;1,曼哈顿距离;2,欧拉距离;3,其他)
可以看到,重要参数有三个,排列组合起来,也有很多组合。如果还按照上一步那样手动调整,效率很低。
所以这一步,介绍一种叫做网格搜索(Grid Search)的方法,高效寻找参数。
from sklearn.neighbors import KNeighborsClassifier
param_grid=[
{
'weights':['uniform'],
'n_neighbors':[3,5,7,9,11]
},
{
'weights':['distance'],
'n_neighbors':[3,5,7,9,11],
'p':[i for i in range(1,4)]
},
]
boost = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, scoring='roc_auc', n_jobs = -1, verbose = 1) grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
保姆级操作演示
1、是不是看得似懂非懂,先介绍一下网格搜索(Grid Search)函数吧:
先上官方网站,全英文的,献给需要的同志:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
再看简介:就是自动调参,只要把参数范围输进去,能够输出最优参数组合。然而该方法适合于小数据集,一旦数据的量级上去了,很难得出结果(放心我们拿到的基本都算小数据集)。
2、它的参数如下:
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
挑选重要的说:
① estimator:基本模型,比如这个是KNN;
② param_grid:需要最优化的参数的取值范围,可以是列表或者字典;
③ scoring:模型评价标准。分为几种情况:
(a)默认None,则使用estimator的误差估计函数;
(b)使用一种score,则需要指定用哪一种,比如使用scoring=‘roc_auc’;可选的有一堆:‘accuracy’,‘balanced_accuracy’,‘roc_auc’等,具体看这里:
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
(c)或者自定义一个score,具体案例自学:
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring
(d)或者多个score,这里不说,自学成才:
https://scikit-learn.org/stable/modules/grid_search.html#multimetric-grid-search
④ n_jobs:并行数。-1:跟CPU核数一致;默认值为1;
⑤ cv:交叉验证参数,默认五折交叉验证。
⑥ verbose:日志冗长度。0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
3、来看看我的代码:
主要看:
param_grid=[
{
'weights':['uniform'],
'n_neighbors':[3,5,7,9,11]
},
{
'weights':['distance'],
'n_neighbors':[3,5,7,9,11],
'p':[i for i in range(1,4)]
},
]
看得出规律了么:首先,当weights为uniform,n_neighbors试3、5、7、9、11;其次,当weights为distance,n_neighbors试3、5、7、9、11,p取值从1到3;注意:i for i in range(1,4),不包括4的哈。
3、然后boost = KNeighborsClassifier(),建立一个KNN模型,参数默认就好,因为下边再调整;
4、接着构建网格模型:
grid_search = GridSearchCV(boost, param_grid, scoring=‘roc_auc’, n_jobs = -1, verbose = 1)
参数都能看明白了哈。
5、接着就是fit一个模型:grid_search.fit(X_train, y_train)
6、Fit结束后,有三个函数可以用:
(a)调用 .best_estimator_ ,可以输出最佳模型;
(b)调用 .best_score_ , 可以输出最佳模型对应的度量;
(c)调用 .best_params_ ,可以输出最佳模型对应的参数;
7、所以最后一步就是输出最优模型,以及用来做拟合。
说了那么多,看看结果吧:
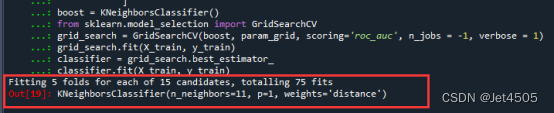
一共75种参数组合,最优参数是:n_neighbors=11, p=1, weights=‘distance’。
二、模型评价
直接上代码了,省得大家回去考古(下回不上了,自行保存好):
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
#绘画测试集混淆矩阵
classes = list(set(y_test))
classes.sort()
plt.imshow(cm_test, cmap=plt.cm.Blues)
indices = range(len(cm_test))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('guess')
plt.ylabel('fact')
for first_index in range(len(cm_test)):
for second_index in range(len(cm_test[first_index])):
plt.text(first_index, second_index, cm_test[first_index][second_index])
plt.show()
#绘画训练集混淆矩阵
classes = list(set(y_train))
classes.sort()
plt.imshow(cm_train, cmap=plt.cm.Blues)
indices = range(len(cm_train))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('guess')
plt.ylabel('fact')
for first_index in range(len(cm_train)):
for second_index in range(len(cm_train[first_index])):
plt.text(first_index, second_index, cm_train[first_index][second_index])
plt.show()
import math
from sklearn.metrics import confusion_matrix,roc_auc_score,auc,roc_curve
cm = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
#测试集的参数
a = cm[0,0]
b = cm[0,1]
c = cm[1,0]
d = cm[1,1]
acc = (a+d)/(a+b+c+d)
error_rate = 1 - acc
sen = d/(d+c)
sep = a/(a+b)
precision = d/(b+d)
F1 = (2*precision*sen)/(precision+sen)
MCC = (d*a-b*c) / (math.sqrt((d+b)*(d+c)*(a+b)*(a+c)))
auc_test = roc_auc_score(y_test, y_testprba)
#训练集的参数
a_train = cm_train[0,0]
b_train = cm_train[0,1]
c_train = cm_train[1,0]
d_train = cm_train[1,1]
acc_train = (a_train+d_train)/(a_train+b_train+c_train+d_train)
error_rate_train = 1 - acc_train
sen_train = d_train/(d_train+c_train)
sep_train = a_train/(a_train+b_train)
precision_train = d_train/(b_train+d_train)
F1_train = (2*precision_train*sen_train)/(precision_train+sen_train)
MCC_train = (d_train*a_train-b_train*c_train) / (math.sqrt((d_train+b_train)*(d_train+c_train)*(a_train+b_train)*(a_train+c_train)))
auc_train = roc_auc_score(y_train, y_trainprba)
#绘画训练集ROC曲线
fpr_train, tpr_train, thresholds_train = roc_curve(y_train, y_trainprba, pos_label=1, drop_intermediate=False) #改成y_test或者y_train
plt.plot([0, 1], [0, 1], '--', color='navy')
plt.plot(fpr_train, tpr_train, 'k--',label='Mean ROC (area = {0:.4f})'.format(auc_train), lw=2,color='darkorange')
plt.xlim([-0.01, 1.01]) # 设置x、y轴的上下限,设置宽一点,以免和边缘重合,可以更好的观察图像的整体
plt.ylim([-0.01, 1.01])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # 可以使用中文,但需要导入一些库即字体
plt.title('Please replace your title')
plt.legend(loc="lower right")
#plt.savefig('rf_ljz_training sets muti-ROC.tif',dpi=300)
plt.show()
#绘画测试集ROC曲线
fpr_train, tpr_train, thresholds_train = roc_curve(y_test, y_testprba, pos_label=1, drop_intermediate=False) #改成y_test或者y_train
plt.plot([0, 1], [0, 1], '--', color='navy')
plt.plot(fpr_train, tpr_train, 'k--',label='Mean ROC (area = {0:.4f})'.format(auc_test), lw=2,color='darkorange')
plt.xlim([-0.01, 1.01]) # 设置x、y轴的上下限,设置宽一点,以免和边缘重合,可以更好的观察图像的整体
plt.ylim([-0.01, 1.01])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # 可以使用中文,但需要导入一些库即字体
plt.title('Please replace your title')
plt.legend(loc="lower right")
#plt.savefig('rf_ljz_training sets muti-ROC.tif',dpi=300)
plt.show()
#绘画测试集PR曲线
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, average_precision_score
precision_1, recall_1, thresholds = precision_recall_curve(y_test, y_testprba)
plt.step(recall_1, precision_1, color='darkorange', alpha=0.2,where='post')
plt.fill_between(recall_1, precision_1, step='post', alpha=0.2,color='darkorange')
plt.figure("P-R Curve")
plt.title('Precision/Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.plot(recall_1,precision_1)
plt.show()
AP_test = average_precision_score(y_test, y_testprba, average='macro', pos_label=1, sample_weight=None)
#绘画训练集PR曲线
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, average_precision_score
precision_1, recall_1, thresholds = precision_recall_curve(y_train, y_trainprba)
plt.step(recall_1, precision_1, color='darkorange', alpha=0.2,where='post')
plt.fill_between(recall_1, precision_1, step='post', alpha=0.2,color='darkorange')
plt.figure("P-R Curve")
plt.title('Precision/Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.plot(recall_1,precision_1)
plt.show()
AP_train = average_precision_score(y_train, y_trainprba, average='macro', pos_label=1, sample_weight=None)
看看结果,见识一下啥叫过拟合:
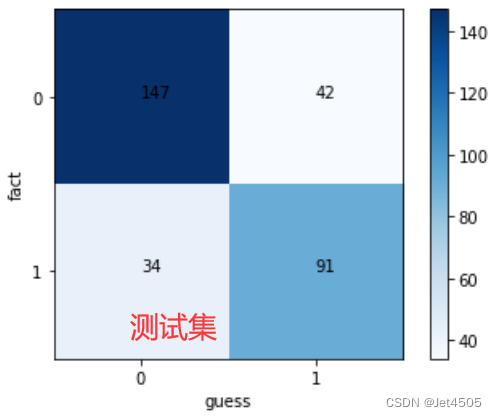
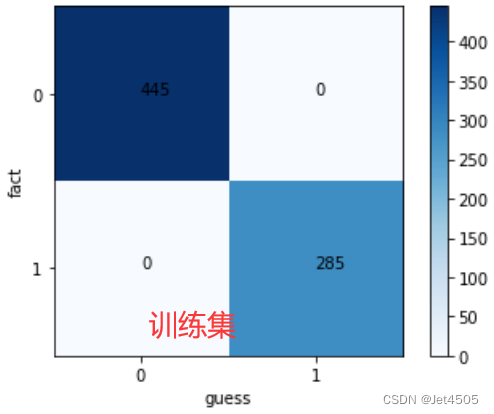
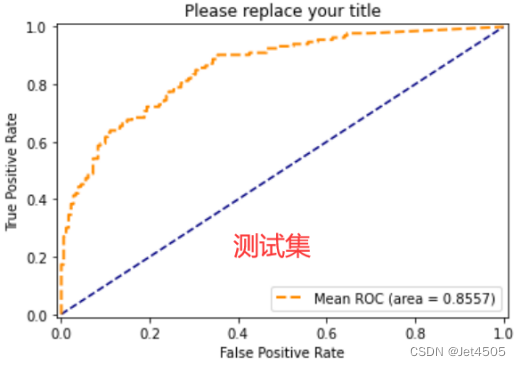
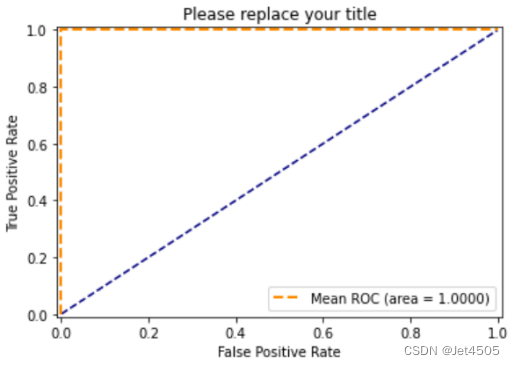
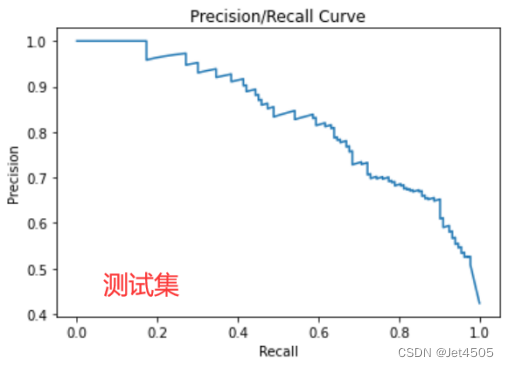
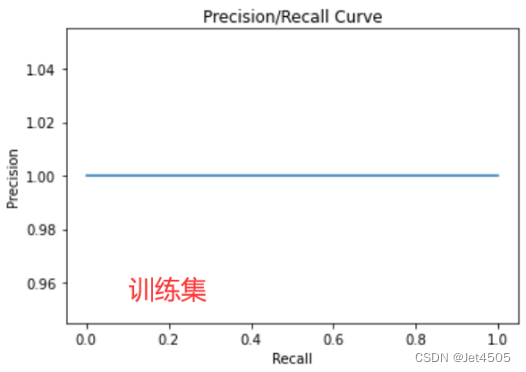
KNN的通病,挺容易过拟合的,训练集100%,测试集85%。大家可以在优化下参数,看看能否解决或者减少过拟合问题。比如增加n_neighbors、p的测试数,换一个score,增加交叉认证数(cv=10?)。
三、SPSSPRO调参
我就随便弄弄,有兴趣的自己琢磨哈,看看结果:
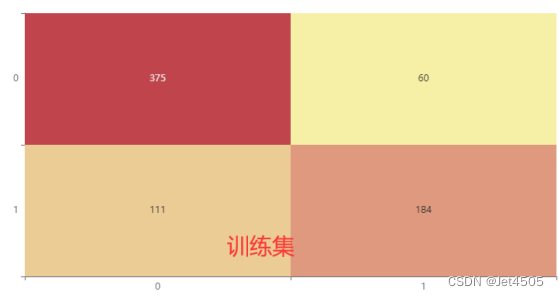
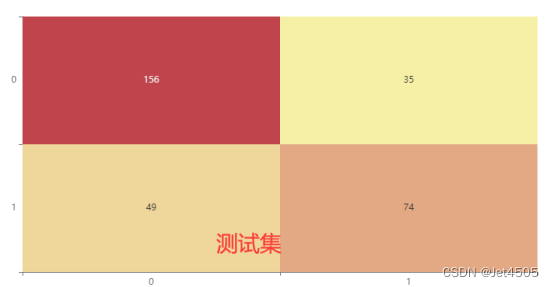
还阔以,没有过拟合,不过测试集性能差一些。不过总体来看,也没有逻辑回归好,哈哈哈。
总结
NA

















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











